
AI科技評論按:微軟研究院對MRC領域遷移進行了首次嚐試。他們最新提出的SynNet模型能在一個新的領域獲得更準確的結果,而不需要額外的訓練數據,並且網絡性能接近全監督MRC係統。
對人類來說,閱讀理解是每天都在進行的基本任務。早在小學的時候,我們就能在閱讀文章後,回答與文章的中心思想和細節相關的問題。
但對AI來說,完美的進行閱讀理解仍然是一個難以實現的目標,但如果我們要評估和實現通用人工智能,就必須讓AI達成這個目標。
實際上,許多現實生活中的場景,包括客戶服務、建議、問答、對話和客戶關係管理,都需要用到閱讀理解。如果AI能完美的進行閱讀理解,它將在一些情況下有驚人的潛能,比如在成千上萬的文件中,迅速幫助醫生找到重要的信息,讓他們把時間用在更有價值的、可能會挽救生命的工作上。
因此,構建出能夠進行機器閱讀理解(MRC)的機器很有意義。比如在執行搜索請求時,機器理解將給出一個準確的答案,而不是拋給你一個網址,你需要點開之後在冗長的網頁中找到答案。此外,機器理解模型能夠理解狹窄和特定領域的文章中的知識,在那些領域中,支撐算法的搜索數據很少。
微軟專注於機器閱讀,目前正引領著該領域的競爭。微軟的多個項目,包括用於機器理解的深度學習項目,也把目光投向了MRC。盡管取得了很大的進展,但微軟還是忽視了一個關鍵問題,這個問題直到最近才被注意:怎樣針對一個新的領域構建MRC係統?
最近,微軟AI研究院的Po-Sen Huang、Xiaodong He等多名研究員和來自斯坦福大學的實習生David Golub針對這個問題開發了一種遷移學習算法。他們將在2017年的頂尖自然語言處理會議——EMNLP上介紹這種算法。這是開發出可擴展解決方案的關鍵步驟,可以將MRC擴展到更廣泛的領域。
微軟在朝著更大的目標在邁進,這種算法是他們取得進步的一個例子。他們想要用更複雜和微妙的能力來創造技術。
Rangan Majumder 在機器閱讀博客上說過:“我們的目的不是建立一堆解決理論問題的算法,我們正在用這些算法解決實際問題,在實際的數據上測試他們。”
目前,大多數最先進的機器閱讀係統都是建立在監督訓練數據的基礎之上,這些模型已經在樣例上進行過端到端的訓練。訓練樣例不僅包括文章,還包括與文章相關的手動標簽的問題和問題相應的答案。
通過這些示例,基於深度學習的MRC模型學會理解問題並從文章中推斷出答案,這包括多個論證和推理步驟。
然而,對於許多領域或行業而言,這種監督訓練數據並不存在。例如,如果要建立一個新的機器閱讀係統,來幫助醫生找到與新疾病相關的重要信息,問題是:可能會有很多可用的文檔,但是我們缺少與文檔相關的手動標簽的問題以及問題相應的答案。
這一挑戰正在變大,因為我們需要為每種疾病建立一個獨立的MRC係統,此外文獻的數量正在急劇增加。因此,至關重要的是,要弄清楚如何讓一個領域的MRC係統在另一個領域也能適用。在後麵那個新的領域中,沒有手動標簽的問題,也沒有問題相應的答案,但是有大量的文檔。
微軟的研究人員開發了一種新的模型——兩級綜合網絡(SynNet),可以用來解決上麵的問題。在這種方法中,基於一個領域中的監督數據,SynNet首先學會一種通用模式,這種通用模式能識別文章中可能的關注點。這些關注點指的是關鍵知識點、命名實體或語義概念,通常是人們可能會問到的問題的答案。然後,在第二級,模型會學著根據文章內容,圍繞可能的答案,形成自然語言問題。
訓練好的SynNet可以應用於新的領域。它可以在新的領域中閱讀文檔,針對這些文檔生成偽問題和答案。然後,針對那個新的領域,生成必要的訓練數據來訓練MRC係統。這個新的領域可能是一種新的疾病,一本新公司的員工手冊,或是一份新的產品手冊。
產生合成數據來對不足的訓練數據進行補充,這種想法在以前就有過研究。例如,針對於翻譯任務,Rico Sennrich和他的同事們在一篇論文中提出了一種方法:根據真實的句子生成新的句子,用來完善已有的機器翻譯係統。然而,與機器翻譯不同的是,對於像MRC這樣的任務,一篇文章需要既生成問題,又生成答案。此外,即使問題在語法上是流利的自然語句,答案通常是段落中某個突出的語義概念,例如一個命名實體、一段情節或是一個數字。由於答案與問題有不同的語言結構,因此將他們視為兩種不同類型的數據可能更合適。
微軟的新方法將產生問題-答案對的過程分成兩步:先通過段落來生成答案,再通過段落和生成的答案,來生成問題。因為答案通常是關鍵的語義概念,所以會先生成答案。問題可以被看作組合起來的完整句子,用來詢問前麵的概念。
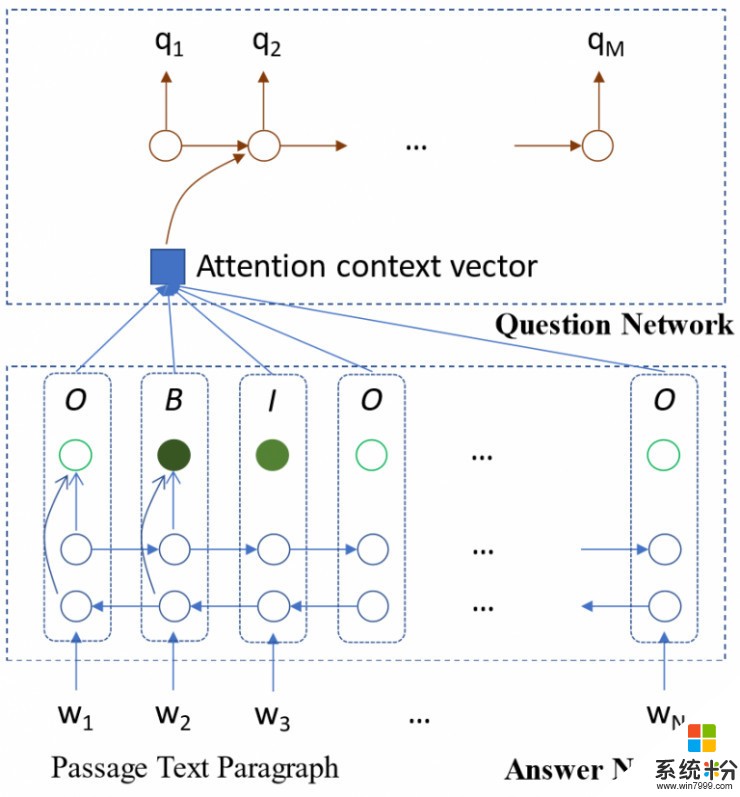
圖:訓練好的SynNet可以用於合成關於給定段落的答案和問題。模型的第一級是回答合成模塊,使用雙向長短時記憶網絡(LSTM)來預測關於輸入段落的輸入、輸出和開始(IOB)標簽,這些標簽標記出可能為答案的關鍵語義概念。第二級是問題合成模塊,使用單向長短時記憶網絡(LSTM)來生成問題,也生成段落中的嵌入詞和IOB ID。段落中的多個span標簽會被識別為可能的答案,但在生成問題時,他們隻選擇一個span標簽。
兩個從文章中生成問題和答案的例子,如下圖所示:


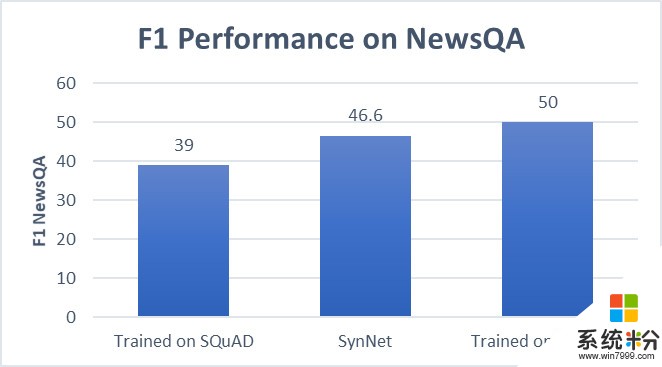
使用SynNet後,能在一個新的領域獲得更準確的結果,而不需要額外的訓練數據,並且網絡性能接近全監督MRC係統。
SynNet就像一名教師,根據她在以前的領域中學到的經驗,從新的領域的文章中創造出問題和答案,並利用她的這些創造來教學生在新的領域中進行閱讀理解。相應的,微軟的研究人員也開發了一組神經機器閱讀模型,包括最近開發的很有潛力的ReasoNet模型,這些模型就像是從教學資料中學習的學生,可以根據文章來回答問題。
據微軟所知,這是進行MRC領域遷移的首次嚐試。他們期待著開發可擴展的解決方案,快速擴展MRC的能力,進而釋放出機器閱讀顛覆性的潛力!
AI科技評論編譯。
via:Microsoft Research Blog
相關資訊
最新熱門應用

樂速通app官方最新版
生活實用168.55MB
下載
墨趣書法app官網最新版
辦公學習52.6M
下載
光速寫作軟件安卓版
辦公學習59.73M
下載
中藥材網官網安卓最新版
醫療健康2.4M
下載
駕考寶典極速版安卓app
辦公學習189.48M
下載
貨拉拉搬家小哥app安卓版
生活實用146.38M
下載
烘焙幫app安卓最新版
生活實用22.0M
下載
喬安智聯攝像頭app安卓版
生活實用131.5M
下載
駕考寶典科目四app安卓版
辦公學習191.55M
下載
九號出行
旅行交通133.3M
下載