

新智元推薦

1. 引言
過去幾年裏,自動語音識別(ASR)已經取得了重大的進步 [1-21]。這些進步讓 ASR 係統越過了許多真實場景應用所需的門檻,催生出了 Google Now、微軟小娜和亞馬遜 Alexa 等服務。這些成就中很多都是由深度學習(Deep Learning)技術推動的。
在這篇論文中,我們調查了過去兩年的新進展,並重點關注了聲學模型。我們討論了所調查的每一項有趣的研究成果的動機和核心思想。具體而言,第 2 節中,我們闡釋了使用深度循環神經網絡(RNN)和深度卷積神經網絡(CNN)的改進的 DL/HMM(深度學習-隱馬爾可夫模型)混合聲學模型。比起前饋深層神經網絡(DNN),這些混合模型能更好地利用語境信息,並由此得到了新的當前最佳的識別準確度。
第 3 節中,我們描述了僅使用很少或不使用不可學習組件的以端到端方式設計和優化的聲學模型。我們首先討論了直接使用音頻波形作為輸入特征的模型,其特征表征層是自動學習到的,而不是人工設計的。然後我們描述了聯結主義時序分類(Connectionist Temporal Classification, CTC)標準優化的模型,該模型允許序列到序列的直接映射。之後我們分析了構建於注意機製之上的序列到序列翻譯模型。
第 4 節中,我們討論了可以提升穩健性的技術,並重點關注了自適應技術、語音增強和分離技術、穩健訓練技術。第 5 節中,我們描述了支持高效解碼的聲學模型並涵蓋了通過教師-學生訓練(teacher-student training)與量化實現的跳幀和模型壓縮。第 6 節中,我們提出了正待解決的核心問題以及有望解決這些問題的未來方向。
2. 利用可變長度語境信息的聲學模型
DL/HMM 混合模型 [1-5] 是第一種在 ASR 上取得成功的深度學習架構,而且仍然是這一行業使用的主導模型。幾年前,大多數混合係統都是基於 DNN 的。
但是,由於音素和語速的不同,語境信息的最優長度也可能各不相同。這說明像在 DNN/HMM 混合係統中一樣使用固定長度的語境窗口(context window)可能並非利用語音信息的最佳選擇。近幾年,人們已經提出了一些可以更有效地利用可變長度語境信息的新模型。其中最重要的兩個模型使用了深度 RNN 和 CNN。
A. 循環神經網絡(RNN)
前饋 DNN 僅會考慮固定長度的幀的滑動窗口中的信息,因此無法利用語音信號中的長距離相關性。而 RNN 可以編碼自己內部狀態中的序列曆史,因此有望基於截止當前幀所觀察到的所有語音特征來預測音素。但不幸的是,純粹的 RNN 難以訓練。
為了克服這些問題,研究人員開發了長短期記憶(LSTM)RNN [23]。LSTM-RNN 使用輸入門、輸出門和遺忘門來控製信息流,使得梯度能在相對更長的時間跨度內穩定地傳播。
為了得到更好的建模能力,一種流行的做法是將 LSTM 層堆疊起來 [8]。但帶有太多 vanilla LSTM 層的 LSTM-RNN 非常難以訓練,而且如果網絡太深,還會有梯度消失問題。這個問題可以使用 highway LSTM 或 residual LSTM 解決。
在 highway LSTM [29] 中,相鄰層的記憶單元通過門控的直接鏈路連接在一起,這為信息提供了一種在層之間更直接且不衰減地流動的路徑。
residual LSTM [30,31] 在 LSTM 層之間使用了捷徑連接(shortcut connection),因此也提供了一種緩解梯度消失問題的方法。
另外還有一種二維時頻 LSTM(2-D, time-frequency (TF) LSTM)[35, 36],可以在時間和頻率軸上對語音輸入進行聯合掃描,以對頻譜時間扭曲(spectro-temporal warping)建模,然後再將其輸出的激活(activation)用作傳統的時間 LSTM 的輸入。這種時間-頻率聯合建模能為上層的時間 LSTM 提供更好的規範化的特征。
網格 LSTM(Grid LSTM [38] )是一種將 LSTM 記憶單元排布成多維網格的通用 LSTM,可以被看作是一種將 LSTM 用於時間、頻譜和空間計算的統一方法。
盡管雙向 LSTM(BLSTM)通過使用過去和未來的語境信息能得到比單向 LSTM 更好的表現,但它們並不適合實時係統,因為這需要在觀察到整個話語之後才能進行識別。因為這個原因,延遲受控 BLSTM(LC-BLSTM)[29] 和行卷積 BLSTM(RC-BLSTM)等模型被提了出來,這些模型構建了單向 LSTM 和 BLSTM 之間的橋梁。在這些模型中,前向 LSTM 還是保持原樣。但反向 LSTM 會被替代——要麼被帶有最多 N 幀前瞻量的反向 LSTM(如 LC-BLSTM 的情況)替代,要麼被集成了 N 幀前瞻量中的信息的行卷積替代。
B. 卷積神經網絡(CNN)
卷積神經網絡(CNN)是另一種可以有效利用可變長度的語境信息的模型 [42],其核心是卷積運算(或卷積層)。
時延神經網絡(time delay neural network/TDNN)是第一種為 ASR 使用多個 CNN 層的模型。這種模型在時間軸和頻率軸上都應用了卷積運算。
繼DNN 在 LVCSR 上的成功應用之後,CNN 又在 DL/HMM 混合模型架構下被重新引入。因為該混合模型中的 HMM 已經有很強的處理 ASR 中可變長度話語問題的能力了,所以重新引入 CNN 最初隻是為了解決頻率軸的多變性 [5,7,44,45]。其目標是提升穩健性,以應對不同說話人之間的聲道長度差異。這些早期模型僅使用了一到兩個 CNN 層,它們和其它全連接 DNN 層堆疊在一起。
後來,LSTM 等其它 RNN 層也被集成到了該模型中,從而形成了所謂的 CNN-LSTM-DNN (CLDNN) [10] 和 CNN-DNN-LSTM(CDL)架構。
研究者很快認識到處理可變長度的話語不同於利用可變長度的語境信息。TDNN 會沿頻率軸和時間軸兩者同時進行卷積,因此能夠利用可變長度的語境信息。基於此,這種模型又得到了新的關注,但這一次是在 DL/HMM 混合架構之下 [13,47],並且出現了行卷積 [15] 和前饋序列記憶網絡(feedforward sequential memory network/FSMN) [16]等變體。
最近以來,主要受圖像處理領域的成功的激勵,研究者提出和評估了多種用於 ASR 的深度 CNN 架構 [14,17,46,48]。其前提是語譜圖可以被看作是帶有特定模式的圖像,而有經驗的人能夠從中看出裏麵說的內容。在深度 CNN 中,每一個更高層都是更低層的一個窗口的非線性變換的加權和,因此可以覆蓋更長的語境以及操作更抽象的模式。和有長延遲困擾的 BLSTM 不一樣,深度 CNN 的延遲有限,而且如果可以控製計算成本,那就更加適用於實時係統。
為了加速計算,我們可以將整個話語看作是單張輸入圖像,因此可以複用中間計算結果。還不止這樣,如果深度 CNN 的設計能保證每一層的步幅(stride)長到能覆蓋整個核(kernel),比如基於逐層語境擴展和注意(layer-wise context expansion and attention/LACE)的 CNN [17]和dilated CNN [46],它僅需更少數量的層就能利用更長範圍的信息,並且可以顯著降低計算成本。
3. 使用端到端優化的聲學模型
在 DNN/HMM 混合模型中,DNN 和 HMM 兩個組件通常是分別進行優化的。然而,語音識別是一個序列識別問題。如果模型中的所有組件都聯合進行優化,那就很可能得到更好的識別準確度。如果模型可以移除所有人工設計的組件(比如基本特征表征和詞典設計),那結果甚至可以更好。
A. 自動學習到的音頻特征表征
對語音識別而言,人工設計的對數梅爾濾波器組特征(log Mel-filter-bank feature)是否最優還存在爭議。受機器學習社區內端到端處理的啟發,研究者們一直在努力 [49-52] 試圖用直接學習濾波器替代梅爾濾波器組提取。直接學習濾波器就是使用一個網絡來處理原始的語音波形,並且與識別器網絡聯合訓練而得到濾波器。
遠場 ASR 領域當前的主導方法仍然是使用傳統的波束成形方法來處理來自多個麥克風的波形,然後再將經過波束成形處理過的信號輸入給聲學模型 [54]。在使用深度學習執行波束成形以及波束成形和識別器網絡的聯合訓練上,都已經有了一些研究工作 [55-58]。
B. 聯結主義時序分類(CTC)
語音識別任務是一種序列到序列的翻譯任務,即將輸入波形映射到最終的詞序列或中間的音素序列。聲學模型真正應該關心的是輸出的詞或音素序列,而不是在傳統的交叉熵(CE)訓練中優化的一幀一幀的標注。為了應用這種觀點並將語音輸入幀映射成輸出標簽序列,聯結主義時序分類(CTC)方法被引入了進來 [9,60,61]。為了解決語音識別任務中輸出標簽數量少於輸入語音幀數量的問題,CTC 引入了一種特殊的空白標簽,並且允許標簽重複,從而迫使輸出和輸入序列的長度相同。
CTC 的一個迷人特點是我們可以選擇大於音素的輸出單元,比如音節和詞。這說明輸入特征可以使用大於 10ms 的采樣率構建。CTC 提供了一種以端到端的方式優化聲學模型的途徑。在 deep speech [15, 63] 和 EESEN [64,65] 研究中,研究者探索了用端到端的語音識別係統直接預測字符而非音素,從而也就不再需要 [9,60,61] 中使用的詞典和決策樹了。
確定用於 CTC 預測的基本輸出單元是一個設計難題。其中,預先確定的固定分解不一定是最優的。[68] 中提出了 gramCTC,可以自動學習最適合目標序列的分解。但是,所有這些研究都不能說是完全端到端的係統,因為它們使用了語言模型和解碼器。
因為 ASR 的目標是根據語音波形生成詞序列,所以詞單元(word unit)是網絡建模的最自然的輸出單元。[18] 中表明通過使用 10 萬個詞作為輸出目標並且使用 12.5 萬小時數據訓練該模型,發現使用詞單元的 CTC 係統能夠超越使用音素單元的 CTC 係統。
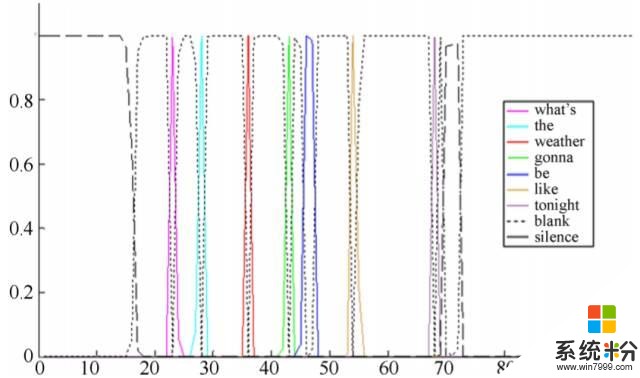
圖 1:詞 CTC 的一個示例
受 CTC 研究的啟發,最近有研究者提出了無 lattice 最大互信息(lattice-free maximum mutual information/LFMMI),可以無需從交叉熵網絡進行初始化,就能從頭開始訓練深度網絡。
總體來說,從 DNN 到 LSTM(時間建模)再到 CTC(端到端建模),聲學模型存在一個清晰的主要發展路徑。盡管使用音素作為建模單元時,LFMMI 等一些建模技術可以得到與 CTC 類似的表現,但它們可能並不非常符合端到端建模的趨勢,因為這些模型需要專家知識來設計,也需要語言模型和詞典等組件才能工作。
C. 基於注意的序列到序列翻譯模型
基於注意(attention)的序列到序列模型是另一種端到端模型 [71,72]。它源自機器學習領域內一種成功的模型 [73,74],即使用注意解碼器(attention decoder)對編碼器-解碼器框架 [75] 進行了擴展。
這種基於注意的模型並沒有像 CTC 那樣假設幀是獨立的,這也是注意模型的一大優勢。這種基於注意的模型的訓練難度甚至比 CTC 模型還大。
基於注意的模型也有不能單調地從左到右對齊和收斂緩慢的缺點。在 [76] 中,通過將 CTC 目標函數用作輔助成本函數,注意訓練和 CTC 訓練以一種多任務學習的方式結合到了一起。這樣一種訓練策略極大地改善了基於注意的模型的收斂,並且緩解了對齊問題。
4. 聲學模型穩健性
當測試集和訓練集匹配時,尤其是當兩者處在相當接近的對話條件下時,當前最佳的係統能夠得到很出色的識別準確度。但是,在有更多噪聲(包括音樂或幹擾性說話人)或帶有很強口音 [78,79] 等不匹配或複雜環境中時,係統的表現將大打折扣。這一問題的解決方案包括自適應、語音增強和穩健建模。
A. 聲學模型自適應
鑒於自適應數據有限,所以與說話人相關(SD)模型和與說話人無關(SI)模型的差距應該不大。參考文獻 [82] 為訓練標準加入了Kullback-Leibler divergence(KLD)正則化,防止自適應的模型偏離 SI 模型太遠。這種 KLD 自適應標準已被證明可以非常有效地處理自適應數據有限的情況。
與其調整自適應標準,大多數研究關注的是如何使用非常少量的參數來表征說話人的特征。奇異值分解(SVD)瓶頸自適應 [84] 是解決方案之一,這種方法可以通過使用 SVD 重構的結構得到占用資源低的 SD 模型 [85]。
k×k 的 SD 矩陣通常是對角主導矩陣,這一觀察啟發研究者提出了低秩加對角(low-rank plus diagonal/LRPD)分解,這種方法可以將 k×k 的 SD 矩陣分解成一個對角矩陣加上兩個低秩矩陣的乘積。
另一種旨在尋找變換的低維子空間的方法是子空間方法(subspace method),這種方法僅需少量參數就能指定每種變換。這一類別內的一種流行方法是使用輔助特征,比如 i-vector [89,90]、說話人代碼 [91] 和噪聲估計 [92],這些特征會與標準的聲學特征串接在一起。
其它子空間方法還包括聚類自適應訓練(CAT)[96,97] 和 factorized hidden layer(FHL),其中的變換會被局限在說話人子空間中。
CAT 風格的方法有一個問題,就是它的基(base)是滿秩矩陣,這需要非常大量的的訓練數據。因此,CAT 中的基的數量通常局限在少量幾個 [96,97]。使用 FHL [98,99] 是一種解決方案,這種方法將基限製為秩一矩陣。通過這樣的方式,能夠減少每個基所需的訓練數據,從而能在訓練數據固定的條件下增加基的數量。
B. 語音增強和分離
眾所周知,當語音中摻雜了很強的噪聲或幹擾語音時,當前的 ASR 係統的表現會變得很差 [105,106]。盡管人類聽者也會受到糟糕的音頻信號的影響,但表現水平的下降程度比 ASR 係統要明顯小很多。
在單聲道語音增強和分離任務中,會假設隻有線性混合的單麥克風信號已知,其目標是恢複音頻源中的每一個音頻流。語音的增強和分離通常在時頻域進行。
研究者近來已經為語音的增強和分離開發了很多深度學習技術。這些技術的核心是將增強和分離問題轉化成一個監督學習問題。更具體來說,就是給定配對的(通常是人工)混合語音和聲源流,針對每個時頻區間(time-frequency bin),優化深度學習模型使其能預測聲源是否屬於目標類別。
與說話人無關的多說話人語音分離的難度在於標簽的模糊性或排列問題。因為在混合信號中,音頻源是對稱的,所以在監督學習過程中,並不能預先確定的將正確源目標分配給對應輸出層。因此,模型將無法很好地訓練以分離語音。幸運的是,人們已經提出了幾種用於解決標簽模糊性問題的技術。
Hershey et al. [111, 112] 提出了一種被稱為深度聚類(deep clustering/DPCL)的全新技術。這種模型假設每個時頻區間都僅屬於一個說話人。在訓練過程中,每個時頻區間都被映射到了一個嵌入空間。然後對這個嵌入進行優化,使屬於同一個說話人的時頻區間在這個空間中相距更近,屬於不同說話人的則相距更遠。在評估過程中,該模型會在嵌入上使用一個聚類算法來生成時頻區間的分區。
Yu et al. [20] 和 Kolbak et al. [21] 則提出了一種更簡單的技術排列不變訓練(permutation invariant training/PIT)來攻克與說話人無關的多說話人語音分離問題。在這種新方法中,源目標被當作一個集合進行處理(即順序是無關的)。在訓練過程中,PIT 首先根據前向結果在句子層麵上確定誤差最小的輸出-目標分配。然後再最小化基於這一分配的誤差。這種策略一次性地簡單直接地解決了標簽排列問題和說話人跟蹤問題。PIT 不需要單獨的跟蹤步驟(因此可用於實時係統)。相反,每個輸出層都對應於源的一個流。
對於語音識別,我們可以將每個分離的語音流饋送給 ASR 係統。甚至還能做到更好,基於深度學習的聲學模型也許可以和分離組件(通常是 RNN)進行端到端的聯合優化。因為分離隻是一個中間步驟,Yu et al. [124] 提出直接在 senone 標簽上使用 PIT 優化交叉熵標準,而不再需要明確的語音分離步驟。
C. 穩健的訓練
深度學習網絡的成功是因為可以將大量轉錄數據用於訓練數以百萬計的模型參數。但是,當測試數據來自一個新領域時,深度模型的表現仍然會下降。
最近,為了得到對噪聲穩健的 ASR,對抗訓練 [125] 的概念也得到了探索 [126-128]。這種解決方案是一種完全無監督的域適應方法,不會利用太多關於新域的知識。它的訓練是通過在編碼器網絡的域鑒別器網絡之間插入一個梯度反向層(gradient reverse layer/GRL)實現的。
最近,為了不使用轉錄數據執行自適應,研究者提出了教師/學生學習(teacher/student (T/S) learning)方法 [132]。來自源域的數據由源域模型(教師)處理,以生成對應的後驗概率或軟標簽(soft label)。這些後驗概率被用於替代源自轉錄數據的硬標簽(hard label),以使用來自目標域的並行數據訓練目標模型(學生)。
5 具有有效解碼的聲學模型
通過堆疊多層網絡訓練深度網絡有助於改善詞錯率(WER)。但是,計算成本卻是個麻煩,尤其是在實時性具有很高的優先級的行業部署中。降低運行時成本的方法有好幾種。
第一種方法是使用奇異值分解(SVD)。SVD 方法是將一個滿秩矩陣分解成兩個更低秩的矩陣,因此可以在保證再訓練之後準確度不下降的同時顯著減少深度模型中的參數數量。
第二種方法是采用教師/學生(T/S)學習或知識精煉(knowledge distillation),從而通過最小化小規模 DNN 和標準的大規模 DNN 的輸出分布之間的 KLD 來壓縮標準的 DNN 模型。
第三種方法是通過大量量化來壓縮模型,既可以應用非常低比特的量化,也可以用向量量化。
第四種解決方案是操作模型結構。為了降低計算成本,研究者提出了一種帶有投射層的 LSTM(LSTMP),即在 LSTM 層之後增加一個線性投射層 [8]。
最後,可以使用跨幀的相關性來降低評估深度網絡分數的頻率。對於 DNN 或 CNN 而言,這可以通過使用跳幀(frame-skipping)策略完成,即每隔幾幀才計算一次聲學分數,並在解碼時將該分數複製到沒有評估聲學分數的幀 [149]。
6 未來方向
這一領域的研究前沿已經從使用近距離麥克風的 ASR 變成了使用遠場麥克風的 ASR,這種發展的推動力是用戶對無需佩戴或攜帶近距離麥克風就能與設備進行交互的需求的日益增長。
盡管為近距離場景開發的很多語音識別技術都可以直接用於遠場場景,但這些技術在遠距離識別場景中的表現不佳。為了最終解決遠距離語音識別問題,我們需要優化從音頻捕獲(如麥克風陣列信號處理)到聲學建模和解碼的整個流程。
作者簡介 | 俞棟博士
騰訊AI Lab副主任及西雅圖實驗室負責人
俞棟博士是首批將深度學習應用到語音識別領域的研究者,60項專利發明人及開源軟件CNTK開發者,曾任職美國微軟、並兼浙大、中科大及上海交大等教職。
他有浙大電子工程學士、美國印第安納大學計算機碩士、中科院自動化所模式識別與智能控製碩士及愛達荷大學計算機博士等學位。
本文經授權轉載自騰訊AI實驗室
點擊閱讀原文可查看職位詳情,期待你的加入~
相關資訊
最新熱門應用

熱幣網交易所app官網版安卓
其它軟件287.27 MB
下載
必安交易所app官網版安卓手機
其它軟件179MB
下載
龍網交易所安卓版
其它軟件53.33M
下載
雲幣網交易所蘋果app
其它軟件14.25MB
下載
幣u交易所鏈接
其它軟件150.34M
下載
唯客交易所安卓版
其它軟件59.95MB
下載
比特港交易所app官網
其它軟件223.86MB
下載
gdax數字交易平台
其它軟件223.89MB
下載
中幣交易所app官方
其它軟件288.1 MB
下載
中幣交易網
其它軟件287.27 MB
下載