
機器之心原創
參與:邱陸陸
今年 9 月,微軟語音識別研究團隊在黃學東的帶領下,將去年 10 月刷新的 5.9% 詞錯率降至 5.1%。作為微軟全球技術院士,黃學東認為,在技術研究的「最後一英裏」,每 0.1 個百分點的進步都異常艱難。
每年的秋天也都是微軟語音「收獲」的季節,重量級的研究成果接連發布,將人與機器連接更緊密的產品逐步進入大眾視野。今年也不例外,刷新 Switchboard WER 紀錄的論文於八月發布,與 Harman 聯手研發的智能音箱準備就緒,在中國,小冰也順利進入第五代。
9 月 8 日,我們專訪了機器之心的「老朋友」——微軟全球技術院士黃學東,共同探討了語音領域這一年裏技術方法的變遷,關注重點的轉移,以及從高精度模型到好用產品的轉化之路。以下為專訪內容:
WER 5.1% 的「超人」語音識別模型和說不定不會來的強人工智能
去年十月份,微軟的語音識別係統在 Switchboard 語音識別任務測試中達到了低至 5.9% 的詞錯率(WER),實現了人類專業速記員的水平。現在一年過去了,語音識別領域有哪些突破性進展嗎?
有,進展用一句話可以總結:詞錯率從 5.9% 降到了 5.1%。可能大家覺得這個進展不大,但是在「最後一英裏」上,每 0.1 個百分點的進步都蠻艱難,必須保證係統沒有任何bug。何況從相對錯誤率降幅(relative error rate reduction)角度, 5.9 到 5.1 是一個超過 10% 的相對進步,我們覺得十分滿意。
另外,通過做 Switchboard 我們學到了很多新東西。這些會直接轉化到我們的產品係統,讓從 Cortana 到 Cognitive Services 再到 PowerPoint Presentation Transltor 這些微軟的各種語音產品與服務都向前走。除了沒有計算資源限製的情況下的最佳效果之外,我們也關注在訓練數據和訓練時間有限的情況下的最佳效果。雖然微軟有錢有人力,但是我們希望與其他研究人員站在同樣的起跑線上交流係統研發成果,並且做到最好。
從 5.9% 到 5.1% 是如何實現的呢?調整結構亦或調整參數?
我們跑了一千多個實驗,評估了上百個不同的模型,幾乎把所有的排列組合試了一遍,可以說是「粒粒皆辛苦」了。
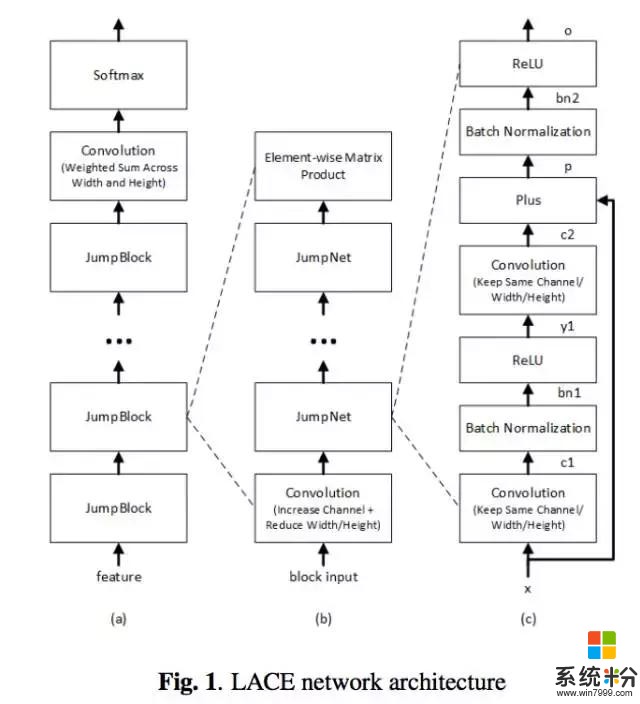
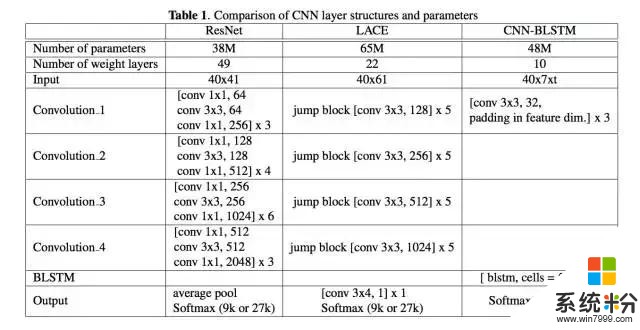
模型效果的進步來自以下幾個方麵:一是語音模型方麵,以前我們雖然同時用到 Bi-LSTM 和 ResNet,但是模型間是完全獨立、彼此並行的。現在我們把 CNN 和 Bi-LSTM 串聯為一個模型,通過三層卷積操作提取底層的特征,然後再用 六層 Bi-LSTM 學習特征之間的序列依賴關係。二是在語言模型方麵,模型從詞級別進一步細化到字符級別,並且利用了整個對話的全局信息以及其中的語段(session)局部信息。三是在不同模型相結合方麵,我們利用了不同的信號,這有點像提升決策樹和隨機森林算法的理念,信號是最基本的子語單元音(subphonetic senone),不同信號的引入讓係統更加魯棒。
5.9% 的次錯率是人類專業速記員的水平,那麼 5.1% 呢?是否可以說語音識別問題已經基本解決了?
語音識別作為一個整體還遠沒有解決,在 Switchboard 上可以說是解決了。5.1% 是什麼概念呢:IBM在澳洲找了4個專業轉錄團隊,他們可以比較、討論、重聽,四個團隊一起工作的最好結果可以做到 5.1%。所以說,我們的係統做到5.1%,我覺得是達到了「超人」的水平。但是這隻是在 Switchboard 這個任務上。
真正的語音識別有口音、噪音、遠場、語速等等問題,在這些方麵,人的魯棒性還是不同一般的。所以我們在這個任務上達到了「超人」的水平隻是一個小小的裏程碑。今年我們的係統比去年增加了四個更加強大的神經網絡、有了比去年更強大的語言模型,但是模型還不是即時的,因此距離投入實際應用還有一定的距離。然而就像現在生物學家尋找治療癌症的藥物的過程一樣,我們要不惜代價去尋找更好的靶點。這就是為什麼我們仍然在追求 WER 更低的係統。但我覺得今後幾年語音識別普遍達到超人水平應該不是一個關鍵問題。
那麼關鍵問題會是哪些任務?
語言理解,理解那些在交流過程中還沒有用語言表達出來的意思。在感知方麵,今後幾年計算機可以達到人的水平,然而在認知上,人可以通過上下文以及額外的手勢和眼神等信息對說話人的意思有比較透徹的理解,計算機在這方麵差距還是很大的。
另外現在的係統還是非常的複雜,語音部分就有14個神經網絡並行運作,要整合起來,再把語言模型加上去,再做整合…… 係統還是需要做非常多簡化。
您在加入微軟之前也曾參與過 CMU 的語音係統開發,高校和企業的研究團隊在開發語音係統時有什麼異同?
本質上是一樣的,因為微軟研究院的大批人都是從CMU過去的。CMU 的研究是非常實際的,要做最前沿的東西、做出來的東西要可以很快產品化且有實際效果。所以微軟的研究院和CMU 計算機係的風格是非常接近的。微軟的幾任院長,李開複、沈向洋、洪小文不僅僅都是從CMU計算機係出來的,還都跟隨同一位導師,Raj Reddy。
不同之處,一是在學術界做圖像的人比較多,做語音的人相對比較少。第二,業界用語音可以做到實用的任務比較多,所以工業界的投入相對比較高,學術界很難和工業界抗衡。
另外,雖然說深度神經網絡對感知這個大領域功不可沒,但是在推出產品的時候,工程師要考慮的問題遠比一個語音識別問題要多。比如用什麼樣的數據來訓練模型,用什麼樣的模型來做更有效率,如何和其他的係統更緊密地銜接…… 想要推出一個簡單好用、高效快速的產品或服務,是要解決很多工程問題的、方方麵麵都考慮到的,這是在大學做研究時候一般不會提到的事情。解決工程問題所需的資源比做一個這樣的研究係統高很多,例如現在我們這個團隊裏,做純研究的人員、資源不到10%。
語音領域從「識別」到「理解」,需要經過怎樣的一個進程?
神經網絡在識別領域所謂的「突破」其實並不算什麼突破。它就是一個函數,如果有足夠多有標注的點,就可以從一個序列映射到另一個序列。所以機器翻譯、圖像識別、語音識別,由於有很好標注的映射關係,所以進步比較大。但是自然語言理解,理解什麼,標注什麼?我們不僅缺少有標注的數據,即使標注了大家也不一定統一,尤其是深度推理、生成性模型,都是很玄乎的東西。
所謂(具有理解能力的)強人工智能,迄今為止還沒有看到任何大的進步。深度學習會不會為我們帶來強人工智能仍然是一個大問題。大家都覺得語音識別、計算機視覺、機器翻譯都有很大的突破,就會導致人工智能在感知上有突破。其實這裏要畫一個很大的問號,不一定有。
好模型隻是好產品的其中一環
可以完成任何任務的「強人工智能」還很遙遠,那麼旨在完成有相關性的不同任務「遷移學習」?
微軟把三十多種不同的人工智能服務集合成 Cognitive Service 部署在雲上。Cognitive Service 最大的特點是有定製的能力,可以根據用戶在使用它時的不同要求,定製語音識別、圖像識別功能。我們把工具交到開發者手中,隻要有足夠多的數據,開發者就可以根據自己的需求進行定製。這也是一種遷移學習。

此外,像 Cortana 這樣的個人數字助理,現在基本尚不具備自我學習能力。隻有把這種能力納入係統,才會實現一個更大的飛躍。當然,實現這一功能要比較大的成本,因為不斷地學習需要不斷收集數據,所以有很大一部分是工程成本。
說到成本,訓練中、實驗中,我們可以不計成本地使用計算資源追求更高更快,但是實際部署上還是要考慮實時性以及運行成本的。您能給我們舉一個例子說明從模型到產品的優化過程嗎?
Microsoft PowerPoint Presentation Translator 就是一個例子。雖然我們在 Switchboard 達到了人的水平,但是來到具體產品中,要求實時性了,就是一個沒有達到人的水平的「簡化版」,並且還要戴一個麥克風來把遠場問題變成近場問題。
大家現在都可以去微軟的網站上去下載這個 Presentation Translator,它會成為 PowerPoint 的一個插件。然後你可以用英文、中文、法文等等語言進行演講,演講內容可以被實時翻譯成超過 60 種語言的文本。如果演講的聽眾講不同語言,他們還可以在自己的智能設備上通過 Microsoft Translator APP 加入會議,看不同語言的實時同聲傳譯,並用不同語言與嘉賓互動。重要的是,我們有能力根據用戶演講時的口音、用詞習慣進行調整。比如我有湖南口音,電腦會據此作出調整。
微軟的語音技術現在還服務於哪些人工智能的產品線?
除了 Presentation Translator之外,Skype 也有 Skype Translator,你在給另外一個人打電話的時候,你可以用你自己的語言講,對方也可以用他自己的語言來回答。然後微軟有Cortana,這個是個人助理,你可以通過語音與電腦進行交互。今年秋天我們還會推出一款智能音箱,是與德國的 Harman 合作的包含 Cortana 的產品。我自己試用經曆是,它改變了我的生活方式。每天早上在我睜開眼睛之前,我就可以和它對話,知道現在幾點了,有沒有微軟的新聞,我今天早上有哪些會議,我剛剛睡醒這半個小時得到了最充分的利用。音箱在家居裏是很不起眼的一個小小的設備,我們會用「背景設備」(ambient decice)來形容它,然而因為有了語音交互,它改變了所處的整個環境,讓我的生活更有效率。
能談談 Cortana 和 Alexa 以及其他第三方開發者的合作嗎?
第三方開發者可以開發 Cortana Skills。Alexa 也可以參與含有 Cortana 的音箱。我可以在 PC 上說,「Hey Cortana, open Alexa. 然後讓 Alexa 幫我去亞馬遜買東西。」Cortana 本身也有很多獨到的地方,他和 Office 365、Skype 的整合比較好,所以我知道我的日程、能與朋友聯絡。我們還有必應搜索,可以搜索知識庫並回答簡單問題。
微軟也與 Facebook 聯合推出了神經網絡交換格式 ONNX,能簡單談一談麼?
有了 ONNX 之後,我們和 Caffe2 和 Pytorch 的模型就可以互換。你可以用 Pytorch 寫模型,在 CNTK 上跑。CNTK 也能夠把在 Caffe 上的模型讀取並繼續訓練。CNTK 最大的強項就是快,跟據香港浸會大學褚教授團隊比較, CNTK 比 TensoFlow 在 RNN 上快 3-6 倍。這也是我們為什麼能夠率先達到5.1% 的 WER。它可以將大量數據合理分配到不同 GPU 上進行並行計算。
CNTK 是最底層的工具,用以產生 Presentation Translator模型,模型產生後被打包、放在雲端的 Cognitive Services 裏麵。在人工智能的每一個層麵微軟都有涉及。
像 Presentation Translator 這樣一個產品,從語音識別模型到最後以插件形式作為產品呈現在用戶麵前,開發過程中最大的障礙在哪裏?
我覺得一個好的產品最重要的是要了解的用戶的使用場景。我覺得這個PPT的場景非常到位。我當年帶著美式英文的底子去愛丁堡大學留學,一到蘇格蘭就傻了,蘇格蘭英語,看沒有問題,聽卻聽不懂。當時我就想,如果每一位教授講課的時候像 BBC 一樣有閉路字幕(closed caption)該多好。今天,如果愛丁堡大學的教授下載了Presentation Translator,那麼每一個去蘇格蘭的中國學生都不會重複我當年所受的痛苦了。換一個場景,我們可以支持100個人同時用60種不同的語言討論會話,60種語言基本上能涵蓋世界上90%的人口,他們都可以跨國語言障礙參與討論。
技術是產品中非常重要的一環,但並不是一個產品成功的關鍵。我覺得這些場景和技術一樣有價值。微軟能以這樣的場景通過人和機器的連接讓人和人靠得更近,消除語言障礙是一件非常有意義的事情。
相關資訊
最新熱門應用

zb交易所app最新官網2024
其它軟件225.08MB
下載
派網量化交易所app
其它軟件136.21 MB
下載
bitstamp交易所app
其它軟件33.27MB
下載
v8國際交易所app蘋果手機
其它軟件223.89MB
下載
雷達幣交易所官方網站軟件安卓版
其它軟件292.97MB
下載
歐意交易所官網蘋果手機
其它軟件397.1MB
下載
幣贏交易所app最新版安卓
其它軟件52.2 MB
下載
追幣網交易所最新版
其它軟件223.89MB
下載
比特牛交易所官網app蘋果版
其它軟件26.64MB
下載
火bi交易所
其它軟件175MB
下載