
2018年1月3日,微軟亞洲研究院的r-net率先在SQuAD EM值達到82.650,這意味著在ExactMatch (精準匹配)指標上首次超越人類在2016年創下的82.304。新智元第一時間采訪了MSRA周明團隊,為讀者詳細解析了何為EM、F1,超越人類的具體內涵,NLP最難突破的核心問題以及我國自然語言處理技術發展現狀和未來展望等眾多話題。
2018年1月3日,微軟亞洲研究院的r-net率先在SQuAD machine reading comprehension challenge 上達到82.650,這意味著在ExactMatch (精準匹配)指標上首次超越人類在2016年創下的82.304。
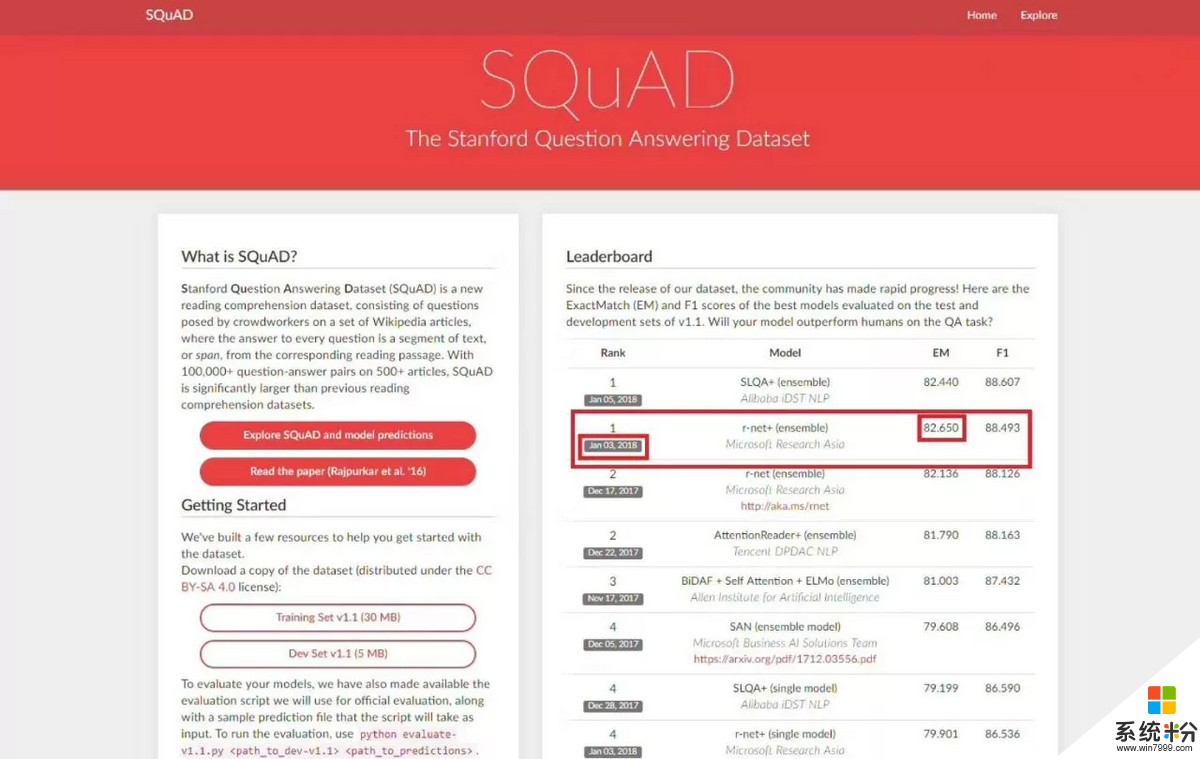
值得注意的是,其中阿裏巴巴數據科學與技術研究院IDST在1月5日提交的結果EM分數為82.44,雖比微軟亞洲研究院r-net略低,但也同樣超越了人類分數。騰訊NLP團隊之前提交的模型緊隨其後,可喜可賀。
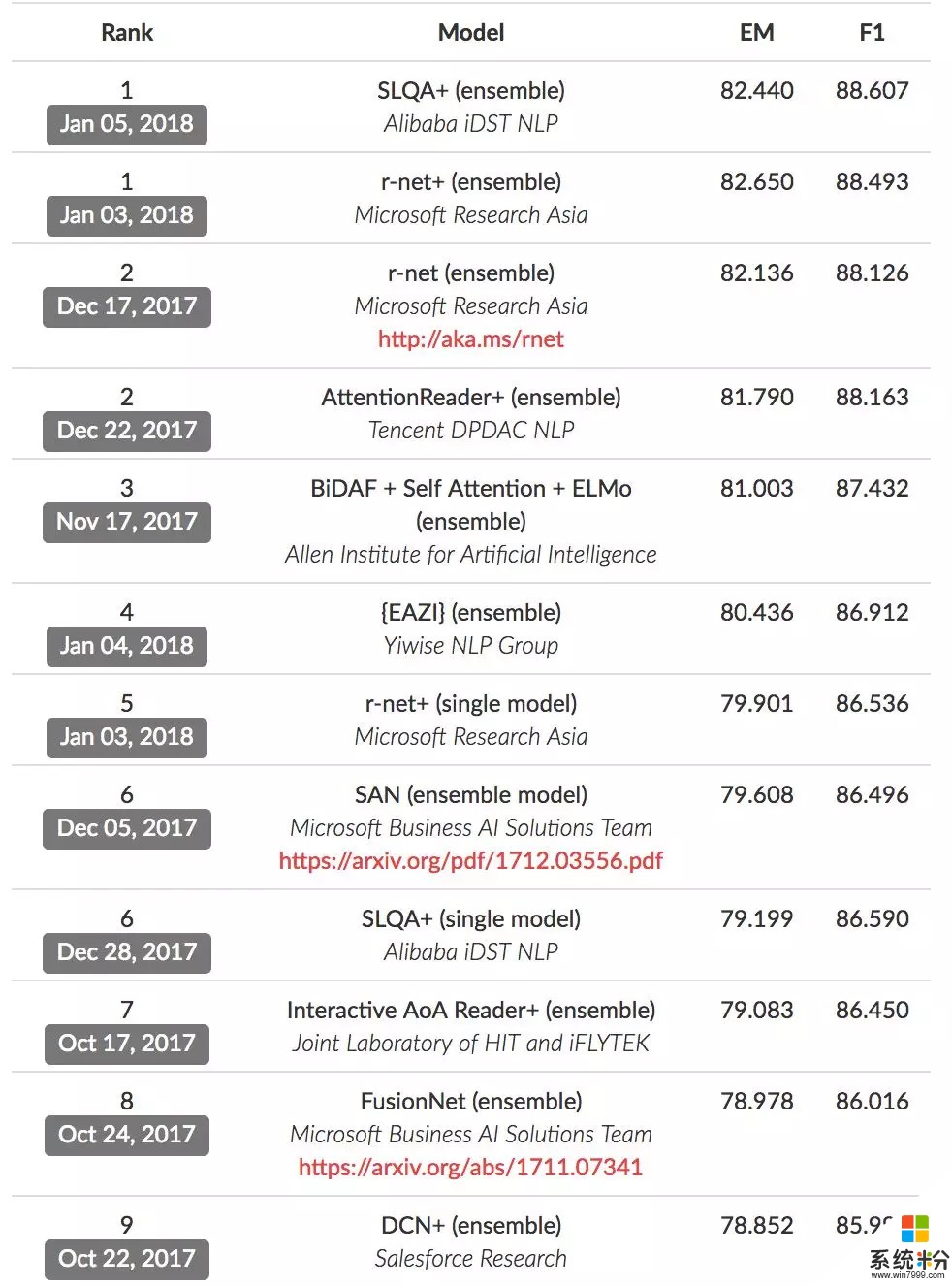
注:官網截圖時間為18年1月16日
在前10名單中,我們看到了中國團隊的“霸榜”:
並列第1:阿裏巴巴 iDST NLP、微軟亞洲研究院
並列第2:微軟亞洲研究院、騰訊DPDAC NLP
第5:微軟亞洲研究院
並列第6:阿裏巴巴 iDST NLP
第7:科大訊飛與哈工大聯合實驗室
包括微軟亞洲研究院、阿裏巴巴、騰訊、科大訊飛、哈爾濱工業大學等在內的中國自然語言處理領域的研究機構勇攀高峰,在SQuAD 機器閱讀理解比賽的前10的榜單中全麵領跑。
中國AI勢力崛起,積極共同推動著自然語言理解的進步。
正如微軟亞洲研究院副院長周明在朋友圈評論所說:祝賀中國的自然語言理解研究已經走在世界前列!高興的同時也更加意識到自然語言理解長路漫漫,更需繼續努力。
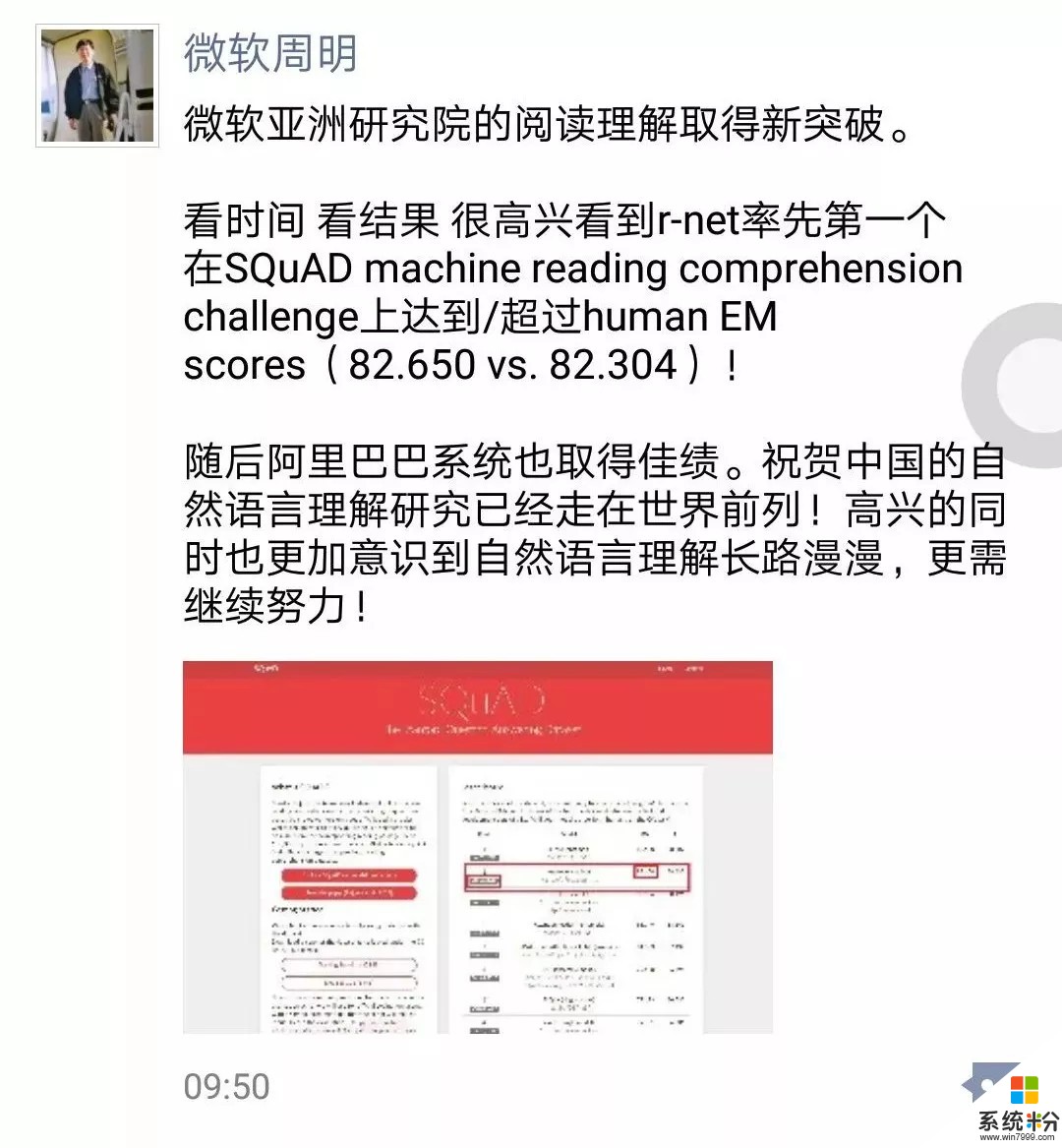
新智元第一時間采訪了周明老師團隊,周老師和MSRA的資深研究員韋福如耐心解答了眾多疑問,並探討了大量技術幹貨,以下為精彩內容呈現。注:周為周明老師回應,韋為韋福如解析。
EM和F1 數值是什麼?ensemble是什麼?和single模型的區別?
韋:SQuAD比賽中有兩個評測指標EM和F1。
EM(Exact Match)要求係統給出的答案和人的標注答案完全匹配才能得分(會去除標點符號和冠詞: a,an,the),完全匹配得1分否則不得分。
F1則根據係統給出的答案和人的標注答案之間的重合程度計算出一個0到1之間的得分,即詞級別的正確率和召回率的調和平均值。
舉個例子,假設某個問題的標注答案是“Denver Broncos”,係統隻有給出了和標注答案完全匹配(即“Denver Broncos”)的輸出,EM才會得1分,否則都不會得分。
而對於F1,即使係統輸出的答案和人的標注答案不完全一樣,比如係統輸出的是“Broncos”,這種情況雖然EM得分為0,但是在F1這個評價指標上會得到一部分分數(0.67)。
EM是一個要求更為嚴格的評測指標,也是MSRA這次係統首次超過人在SQuAD上的結果的評價指標。
模型集成(ensemble)是提高係統效果的常見方法。由於神經網絡模型的初始化以及訓練過程有隨機性,同樣的算法在同樣的數據上訓練多次會得到不一樣的模型。
模型集成就是訓練多個單模型(single model),然後將這些單模型的輸出進行綜合得到最終結果。
集成模型一般會比單模型效果更好,但是也會以係統反應速度和計算資源為代價。實際應用中需要在模型效果和模型效率(更好和更快)上取平衡。
超越人類的具體含義是指?

韋:SQuAD在測試數據集上對每個問題都至少有三個答案 (每個問題至少有3個人標注答案)。SQuAD會將第二個答案作為人的預測結果,將剩餘的答案作為標準答案。
對於EM指標,預測答案同任何一個標準答案相同就算得分。對於F1指標,會選取同所有標準答案中分數最高的作為其得分。這樣就得到了人的EM分數(82.304)和F1分數(91.221)。
周:16年這個比賽開始,我們微軟亞洲研究院每次提交模型幾乎都是第一,在2017年底,我們的成績82.136,已經十分接近人類的標準,僅差0.17個點。這次我們模型的EM值突破達到82.650,超越了人類在精準回答的指標0.3個點。簡單的說,可以這樣理解這0.3個點,我們的係統比人做這套題庫,多做對了30道題。
這遠遠不代表計算機超越了人類的閱讀理解水平,因為這樣的跑分結果是有一個前提條件約束的,比如在確定的題庫和測試時間,並且隻是成年人平均理解水平。
超越人類不能作為媒體的報道噱頭,我們在看到技術進步的同時,更應該冷靜思考模型的不斷完善和技術應用落地。這是一個生態,需要所有玩家一起健康競爭,把現階段麵臨的難題攻克,而非停留在比賽第一這樣的階段性喜悅中。
NLP最難突破的技術核心問題是什麼
韋:目前SQuAD榜單上排名靠前的係統采用的都是端到端的深度神經網絡。一般包含以下幾個部分:
Embedding Layer:一般采用的都是在外部大規模數據上預訓練的詞向量(例如Glove等),以及基於循環神經網絡或者卷積神經網絡的從字符到單詞的詞向量(表示),這樣就可以得到問題和文章段落裏麵每個單詞的上下文無關的表示。有的模型也會抽取一些特征和詞向量一起作為網絡的輸入。相當於是人的詞彙級的閱讀知識。
Encoding Layer:一般采用多層的循環神經網絡得到問題和文章段落的每個詞的上下文相關的表示。相當於人把問題和文章段落讀了一遍。
Matching Layer:實際上是得到問題裏麵的詞和文章段落詞之間的對應(或者叫匹配)關係。基本是采用注意力(attention)的機製實現,常見的有基於Match-LSTM和Co-attention兩種,這樣就得到文章裏麵每個詞的和問題相關的表示。相當於是帶著問題把文章段落讀了一遍。
Self-Matching Layer:在得到問題相關的詞表示的基礎上再采用self-attention的機製進一步完善文章段落中的詞的表示。相當於是再把文章段落讀一遍,書讀百遍,其義自見。
AnswerPointerLayer:對文章段落裏麵的每個詞預測其是答案開始以及答案結束的概率,從而計算文章段落中答案概率最大的子串輸出為答案。這個一般采用Pointer Networks實現。相當於人綜合所有的線索和知識定位到文章段落中的答案位置。
實際上,目前SQuAD上的排名靠前的係統在模型和算法上都有相通、相近之處。
而這也是SQuAD比賽一年多以來,整個閱讀理解研究的社區和同仁(來自不同學校、公司、研究機構)共同努力、相互借鑒和提高的結果。
目前最好的模型一般綜合了以下的算法或部件,包括早期基礎模型。
例如Match-LSTM(新加坡管理大學)和BiDAF(Allen Institute for Artificial Intelligence)注意力機製上的創新(例如Salesforce的Coattention機製,R-NET中的Gated-Attention機製等),R-NET中的Self-Matching(或者叫Self-Attention)機製,以及最近對模型效果提升明顯的預訓練的上下文相關的詞向量表示(Contextualized Vectors),包括基於神經機器翻譯訓練得到句子編碼器(Salesforce)以及基於大規模外部文本數據訓練得到的雙向語言模型(Allen Institute for Artificial Intelligence)等。
當然也有網絡模型的設計、參數調優方法等的改進和創新。可以說,目前的結果實際上是整個閱讀理解社區這一年多的不斷努力和合作的結果。
中文閱讀理解的難度比英文大嗎?
周:從現在研究階段成果來說,我沒有看到論文說中文閱讀理解一定比英文的難,我倒是覺得各有各的難度,比如中文的成語典故、英文的俚語都是難點,兩種語言的指代也各有不同,要具體場景具體分析,不斷調整模型。
現在國內馬上要有中文閱讀理解比賽了,是由中國中文信息學會(CIPS)和中國計算機學會(CCF)聯合主辦,百度公司、中國中文信息學會評測工作委員會和計算機學會中文信息技術專委會聯合承辦。競賽將於2018年3月1日正式開啟報名通道,獲勝團隊將分享總額10萬人民幣的獎金,並將在第三屆“語言與智能高峰論壇”舉辦技術交流和頒獎。
這是一件非常好的事,競賽數據集包含30萬來自百度搜索的真實問題,每個問題對應5個候選文檔文本,以及人工撰寫的優質答案。
比賽中任務通常定義為:讓機器閱讀文本,然後回答和閱讀內容相關的問題。閱讀理解涉及到語言理解、知識推理、摘要生成等複雜技術,極具挑戰。
這些任務的研究對於智能搜索、智能推薦、智能交互等人工智能應用具有重要意義,是自然語言處理和人工智能領域的重要前沿課題。
近半年,MSRA提升突破的關鍵
韋:我們這次的模型是R-NET不斷發展和提升的結果。
正如前麵提到的,我們在把自己的研究和經驗共享給學術界的同時(例如我們ACL 2017年的論文以及後麵的技術報告),也在不斷吸收和借鑒學術界的研究成果來提高R-NET。
在過去的幾個月裏麵,模型的主要提升來自於幾個方麵,從模型和算法上我們把模型做到更深的同時也做到了更廣(寬),例如Matching Layer以及整個係統中最為關鍵的注意力(attention)機製部分。
另外,我們也使用了基於外部大規模數據訓練的上下文相關的詞向量表示(Contextualized Vectors)。我們同時也正在做一些更有意思的研究,並在實驗中看到了很好的結果。
我們會在將來分享更多、更細節的信息,將我們的研究成果與學術界和工業界分享,並期待大家一起努力,共同推動機器閱讀理解的研究和應用創新。
機器閱讀理解技術已有的落地介紹
韋:機器閱讀理解技術有著廣闊的應用場景。
在搜索引擎中,機器閱讀理解技術可以用來為用戶的搜索(尤其是問題型的查詢)提供更為智能的答案。目前R-NET的技術已經成功地在微軟的必應搜索引擎中得到了很好的應用。我們通過對整個互聯網的文檔進行閱讀理解,從而直接為用戶提供精確的答案。
同時,這在移動場景的個人助理,如,微軟小娜(Cortana)裏也有直接的應用。
另外機器閱讀理解技術在商業領域也有廣泛的應用,例如智能客服中,可以使用機器閱讀文本文檔(如用戶手冊、商品描述等)來自動或輔助客服來回答用戶的問題。
在辦公領域,機器閱讀理解技術也有很好的應用前景,比如我們可以使用機器閱讀理解技術處理個人的郵件或者文檔,然後用自然語言查詢獲取相關的信息。
此外,機器閱讀理解技術在垂直領域也有非常廣闊的應用前景,例如在教育領域用來輔助出題,法律領域用來理解法律條款,輔助律師或者法官判案,以及在金融領域裏從非結構化的文本(比如新聞中)抽取金融相關的信息等。
我們認為閱讀理解能力是人類智能中最關鍵的能力之一,機器閱讀理解技術可以做成一個通用的能力,釋放給第三方用來構建更多的應用。
機器閱讀理解技術2018年以及更遠的展望
韋:技術上,目前基於深度學習的算法和模型還有很大的空間,能否提出可以對複雜推理進行有效建模,以及能把常識和外部知識(比如知識庫)有效利用起來的深度學習網絡,是目前很有意義的研究課題。
另外,目前基於深度學習的機器閱讀理解模型都是黑盒的,很難直觀地表示機器進行閱讀理解的過程和結果,因而可解釋性的深度學習模型也將是很有趣的研究方向。
在閱讀理解任務上,目前SQuAD的任務定義中答案是原文的某個子片段,而在實際中人可能讀完文章之後還需要進行更複雜的推理、並組織新的文字再表達出來。對此,微軟發布的MARCO數據集正在朝著這個方向努力。
此外,由於目前的SQuAD數據集中假設每個問題一定可以在對應的文檔段落中找到答案,這個限製條件對於比賽和研究來說是合理有效的,所以,現有的模型就算不是很確定也會選取一個最可能的文檔片段作為輸出。
這個假設和模型的輸出在實際應用中並不合理。人類在閱讀理解回答問題上有一個很重要的能力就是可以知道如果閱讀的文本裏麵沒有答案會拒絕回答。
而這個問題不論是在研究上,還是在實際應用中,都是非常重要的研究課題。我們也已經在開展這方麵的研究,並且取得了一些不錯的進展。
最後,由於SQuAD數據集中的文檔都是來自維基百科,雖然目前的模型都是數據驅動,但是要把目前的模型真正應用到特定的領域(尤其是垂直領域,比如金融、法律等),還需要在數據和模型上做適配和進一步的創新。
相關資訊
最新熱門應用

虛擬幣交易app
其它軟件179MB
下載
抹茶交易所官網蘋果
其它軟件30.58MB
下載
歐交易所官網版
其它軟件397.1MB
下載
uniswap交易所蘋果版
其它軟件292.97MB
下載
中安交易所2024官網
其它軟件58.84MB
下載
熱幣全球交易所app邀請碼
其它軟件175.43 MB
下載
比特幣交易網
其它軟件179MB
下載
雷盾交易所app最新版
其它軟件28.18M
下載
火比特交易平台安卓版官網
其它軟件223.89MB
下載
中安交易所官網
其它軟件58.84MB
下載