
2月9日,紐約時報英文網站發表一篇文章,指出如今非常熱門的AI應用人臉識別,針對不同種族的準確率差異巨大。其中,針對黑人女性的錯誤率高達21%-35%,而針對白人男性的錯誤率則低於1%。
文章引用了MIT媒體實驗室(MIT Media Lab)研究員Joy Buolamwini與來自微軟的科學家Timnit Gebru合作的一篇研究論文《性別圖譜:商用性別分類技術中的種族準確率差異》(Gender Shades: Intersectional Accuracy Disparitiesin Commercia lGender Classification)中的數據。
論文作者選擇了微軟、IBM和曠視(Face++)三家的人臉識別API,對它們進行性別判定的人臉識別功能測試。

在一組385張照片中,白人男性的識別誤差最高隻有1%

在一組271張照片中,膚色較黑的女性識別誤差率高達35% 圖源:紐約時報,JoyBuolamwini,M.I.T.MediaLab
論文研究使用了自行收集的一組名為Pilot Parliaments Benchmark(PPB)數據集進行測試,裏麵包含1270張人臉,分別來自三個非洲國家和三個歐洲國家。
在判斷照片人物性別方麵,以下是論文作者測試後得到的關鍵發現:
- 所有的分類器在識別男性人臉上的表現要優於女性人臉(8.1%-20.6%的錯誤差別)
-?所有分類器在膚色較白的人臉上表現優於膚色較深的人臉(11.8%-19.2%的錯誤差別)
-?所有分類器在膚色較深的女性人臉上表現最差(錯誤率在20.8%-34.7%之間)
- 微軟和IBM的分類器在淺膚色男性人臉上表現最好(錯誤率分別為0%及0.3%)
- Face++的分類器在膚色較深的男性人臉上表現最好(錯誤率0.7%)
-?最差的一組與最好的一組差距高達34.4%
需要指出的是,三家人臉識別API都沒有很細節地解釋自己所使用的分類方法,也沒有提及自己所使用的訓練數據。
不過,微軟在服務中表明“不一定每次都有100%的準確率”;Face++則特別在使用條款中表明對準確性不予保證。
關於可能的原因,時報文章表示,當下的人工智能是數據為王,數據的好壞和多少會影響AI的智能程度。因而,如果用來訓練AI模型的數據集中,白人男性的數據多於黑人女性,那麼係統對後者的識別能力就會不如前者。
現有的數據集中存在這一現象,比如根據另一項研究的發現,一個被廣泛使用的人臉識別數據集中,75%都是男性,同時80%是白人。
曠視回應表示,深色人種數據集比較難獲得,所以會差一些;另外,使用RGB攝像頭進行人臉識別時,深膚色人的人臉特征比較難找,特別是在暗光條件下,這也是一方麵的原因。
IBM回應:論文用的版本太老,新版已改善
針對Buolamwini和Gebru的這一論文發現,2月6日,IBM在自家的IBM Research博客上發表了一篇回應文章。
文章並未否認論文的發現,而是指出,IBM的Watson Visual Recognition服務一直在持續改善,在最新的將於2月23日推出的新版服務中,使用了相比論文中更廣泛的數據集,擁有強大的識別能力,相比論文中的錯誤率有近10倍的下降。
隨後文章中表示IBM Research用類似論文中的方法進行了實驗,發現如下:
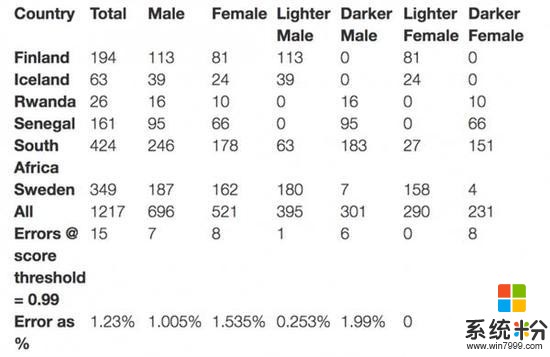
結果顯示整體的錯誤率都很低,雖然膚色較黑的女性的錯誤率仍然是所有人群中最高的,但相比論文的結果有很大下降。
曠視回應:深膚色人種識別錯誤率高是普遍現象,在商用產品中會改善
針對這篇論文向曠視尋求回應,對方給予了非常詳細的解答。
回應中,曠視首先對論文的研究方法表示認可,但同時指出研究所用的線上API是較舊的版本,在商用的產品中不會出現這類問題;而且,此類問題也是業內普遍存在的,不僅限於測試的這三家。
原因主要有兩點,一是深色人種數據集的缺乏,二是深色人種人臉特征較難提取。
以下為回應全文:
我們相信文章(論文)立意不是針對哪一家的技術,基本是不吹不黑的中立態度,而且從文章的測試方法來看還是比較科學的,但是文章中所用的“PPB”(?Pilot Parliaments Benchmark)數據集在GitHub的發布地址已經失效,所以我們目前無法自行檢測以驗證文章的結論。
在集成到Face++API中的時候,曠視研究院有針對不同人種進行檢測、識別等測試。但是就目前國際範圍內的研究水平來說,不管是在學界還是產業界,對於膚色人種的識別表現都沒有對“膚色較淺(引用文章用詞)”人種優秀,從此文的測試結果中也可以看出,微軟、IBM和Face++在膚色較深人種識別的表現中(尤其是膚色較深女性)機器的誤實率會更高。
一方麵從人類基因和人臉識別技術角度來說,皮膚的顏色越深對於基於RGB可見光的人臉識別的難度就越大,因為機器在進行人臉檢測、分析和識別的過程中需要對人臉圖像進行預處理和特征提取,所以皮膚顏色越深,麵部的特征信息就越難提取,尤其是在一些暗光情況下,更加難以檢測和區分。
另一方麵,人臉識別很大程度上依賴於數據訓練,而在整個行業中黑色人種的可訓練數據量較少,所以識別的結果在某些程度上不盡人意,所以文章呈現的測試結果是行業普遍存在的現象。文章中隻是選取了三家行業代表來進行了測試,如果樣本量足夠大,那可能還會得出其他的結論。
不過測試結果也顯示,Face++對於黑人男性的識別錯誤率(0.7%)是最低的,且在PPB的南非子測試集中,Face++識別膚色較淺人種的表現是完美無瑕的,這些其實也間接說明Face++的人臉識別能力是處於全球領先的地位。
文章作者提出了一個很好的問題,但文章中測試的API線上版本和我們為用戶提供的商業版本無關,用戶在業務使用中不會有任何影響。
當然我們也相信行業內都在針對人種識別優化做著各種努力。而就Face++來講,未來研究院會從幾個角度去改善目前的狀況,如增加訓練數據,針對不同人種進行專門訓練,另外是從算法層麵優化現在的流程,提升對不同人種的識別性能,此外,曠視也在加大3D感知的研發力度,將三維特征信息融合到應用中彌補二維信息的不足使模型更加魯棒。
AI真的有歧視嗎?
根據時報的報道,論文的作者之一黑人女性Buolamwini做這項研究之前,曾遇到過人臉識別無法識別她的臉,隻有在她戴上一張白色麵具時才行,因而引發了她開啟這項研究。很明顯,這項研究試圖探討AI時代是否存在社會不公甚至種族歧視的問題。
種族歧視作為一個非常敏感的話題,許多事情隻要有些微沾上點邊就會引發強烈反彈。在人臉識別這塊,無論是論文作者的研究,還是廠商的實驗都明確發現女性深色人種識別誤差率更高。但這就能代表AI存有歧視嗎?
顯然並不是,細究其中的原因,之所以膚色較深女性較難識別,除了有天然人臉特征更難提取之外,還有可供訓練的數據集較少的原因。
而從市場的角度來說,IBM和微軟的服務在白人男性中表現最好,是因為其市場主要在歐美,而那裏白人占多數;曠視的主要市場在東亞和東南亞,因而其在黃種人當中的表現會好很多,這跟歧視沒有關係,而是市場導向的技術研發。
話又說回來,這篇論文確實顯示,AI的智能性跟訓練數據有很大關係,因而在設計AI應用時,我們應該盡量使用廣泛且代表性強的數據,照顧到不同的人群;同時要積極對公眾解釋AI的實現原理。
這件事同時表明,鼓勵新技術的發展惠及更多少數族裔是一件需要更多重視的事情,不僅僅是人臉識別,還有語言、文化等各方麵。
編輯:齊少恒
相關資訊
最新熱門應用

bicc數字交易所app
其它軟件32.92MB
下載
比特國際網交易平台
其它軟件298.7 MB
下載
熱幣交易所app官方最新版
其它軟件287.27 MB
下載
歐昜交易所
其它軟件397.1MB
下載
vvbtc交易所最新app
其它軟件31.69MB
下載
星幣交易所app蘋果版
其它軟件95.74MB
下載
zg交易所安卓版app
其它軟件41.99MB
下載
比特幣交易app安卓手機
其它軟件179MB
下載
福音交易所蘋果app
其它軟件287.27 MB
下載
鏈易交易所官網版
其它軟件72.70MB
下載