
允中 發自 凹非寺
量子位 出品 | 公眾號 QbitAI
百度宣布了一項AI方麵的新成績。
昨天,百度自然語言處理(NLP)團隊研發的V-Net模型以46.15的Rouge-L得分登上微軟的MS MARCO(Microsoft MAchine Reading COmprehension)機器閱讀理解測試排行榜首。
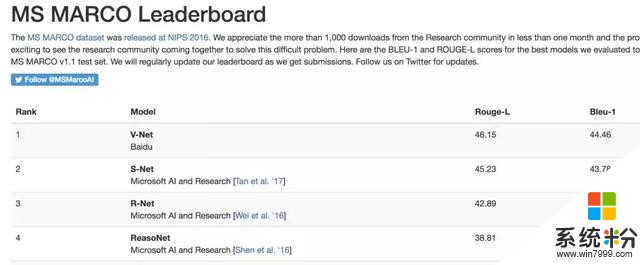
MARCO是微軟基於搜索引擎BING構建的大規模英文閱讀理解數據集,包含10萬個問題和20萬篇不重複的文檔。MARCO數據集中的問題全部來自於BING的搜索日誌,根據用戶在BING中輸入的真實問題模擬搜索引擎中的真實應用場景,是該領域最有應用價值的數據集之一。
此次百度NLP在MARCO提交的V-NET模型,使用了一種新的多候選文檔聯合建模表示方法,通過注意力機製使不同文檔產生的答案之間能夠產生交換信息,互相印證,從而更好的預測答案。
值得注意的是,此次百度隻憑借單模型(single model)就拿到了第一名,並沒有提交更容易拿高分的多模型集成(ensemble)結果。
百度提供的信息稱,在機器閱讀理解領域,研究者多參與由斯坦福大學發起的SQuAD挑戰賽。但相比SQuAD,MARCO的挑戰難度更大,因為它需要測試者提交的模型具備理解複雜文檔、回答複雜問題的能力。

據了解,對於每一個問題,MARCO提供多篇來自搜索結果的網頁文檔,係統需要通過閱讀這些文檔來回答用戶提出的問題。但是,文檔中是否含有答案,以及答案具體在哪一篇文檔中,都需要係統自己來判斷解決。
更有趣的是,有一部分問題無法在文檔中直接找到答案,需要閱讀理解模型自己做出判斷;MARCO也不限製答案必須是文檔中的片段,很多問題的答案必須經過多篇文檔綜合提煉得到。這對機器閱讀理解提出了更高的要求。
目前MARCO的排行榜上主要是百度、微軟等玩家。而SQuAD的參與者包括:科大訊飛、阿裏巴巴、微軟、騰訊、Facebook、三星、複旦、CMU等眾多機構。
百度表示,在自然語言處理領域已經過十餘年積累與沉澱,更致力通過技術應用解決實際問題。這也是百度此次選擇MARCO數據集而不是SQuAD的主要原因。
目前,百度的閱讀理解、深度問答等技術已經在搜索等產品中實際應用。
“此次在MARCO的測試中取得第一,隻是百度機器閱讀理解技術經曆的一次小考,”百度自然語言處理首席科學家兼百度技術委員會主席吳華表示,“我們希望……AI能夠理解人類的語言、用自然語言與人類交流,讓AI更‘懂’人類。”
— 完 —
誠摯招聘
量子位正在招募編輯/記者,工作地點在北京中關村。期待有才氣、有熱情的同學加入我們!相關細節,請在量子位公眾號(QbitAI)對話界麵,回複“招聘”兩個字。
量子位 QbitAI · 頭條號簽約作者
վ'ᴗ' ի 追蹤AI技術和產品新動態
相關資訊
最新熱門應用

matic交易所
其它軟件225.08MB
下載
比特可樂交易所鏈接
其它軟件7.27 MB
下載
defi去中心化交易所
其它軟件166.47M
下載
易歐數字app官網安卓手機
其它軟件397.1MB
下載
中幣交易所app蘋果手機
其它軟件77.35MB
下載
yfii幣交易所app
其它軟件223.89MB
下載
oke歐藝app官方
其它軟件397.1MB
下載
比特國際資產交易所app
其它軟件163.20M
下載
環球交易所app
其它軟件47.40MB
下載
比安交易所官網app
其它軟件179MB
下載