

計算機網絡係統領域頂級會議NSDI 2017於三月末在美國波士頓召開。會議結束之後,我們邀請了微軟亞洲研究院的聯合培養博士生肖文聰與我們分享了他的此次參會的心得體會。你還可能看過他此前分享的SoCC的參會體驗。
會議簡介NSDI的全稱是Networked Systems Design and Implementation,是USENIX旗下的旗艦會議之一,也是計算機網絡係統領域久負盛名的頂級會議。與網絡領域的另一頂會Sigcomm相比,NSDI更加側重於網絡係統的設計與實現,眾所周知的大數據係統Spark就發表在2012年的NSDI大會上。
NSDI特別重視文章質量,會議采用嚴格的雙盲評審,每篇文章都要經過兩輪總計六到八個審稿人審閱,之後還需要經過程序委員會的討論篩選。最後,今年的NSDI在投稿的兩百多篇文章中收錄了學術論文40篇,錄取率為18%。
本屆NSDI在美國波士頓舉行,大會總共持續三天,分為13個session,從數據中心到無線網絡,從安全隱私到異常檢測,從存儲係統到分布式計算,既有經典的網絡問題負載均衡(Load balance)和調度(Scheduling),也有視頻檢測係統和分布式機器學習係統等新場景下的新問題,可以說是涵蓋了網絡係統研究的方方麵麵。每個session僅有三四篇文章,每篇文章都需要在大會上作近半小時的口頭報告並接受提問。除了Oral環節外,第二天的晚上還設有一個單獨的Poster session,總共錄取了量少質優的22篇poster,展示了來自年輕PhD學生的很多新思路和新想法。

早在我第一次去開會的時候,我的導師、微軟亞洲研究院副院長周禮棟博士和我在研究院的指導老師(mentor)伍鳴就告訴我,開會最重要的是什麼:交流!然而很多事情都是知易行難。我不禁回想起兩年前我第一次參與國際學術會議的時候的尷尬,當時由於對自己英語口語和口音的不自信,即便是麵對歡迎晚宴上坐在身旁的研究員,我也不知道該如何開口。我現在還記得,在我完成那年的暑期實習並從美國總部微軟雷德蒙研究院離職的那天,我的指導老師還分享給我不少經驗,其中之一就是關於語言交流的問題。因為英語並不是我們的母語,我們在與別人的交流中存在著理解上的偏差是很經常出現的,不斷訓練自己提升語言能力當然重要,但更重要的是要永遠保持耐心,去傾聽、理解、詢問,為達到一致的理解(context)去不斷嚐試溝通和表達自己。仔細回想,算上大四那年,我已經在微軟亞洲研究院的係統組實習快4年了,幾乎每個研究員都在科研上給予過我幫助,而組裏輕鬆而紮實的學術氛圍,堅持科研與產品相結合的實踐方法更是深深影響了我。我何其榮幸能得到這麼多人孜孜不倦的教誨,點點滴滴隻能牢記於心,不斷踐行。這次的大會上,我在茶歇期間成功搭訕了好幾位優秀學者並與Poster 環節超過一半的人都進行了交流,相比於上次,也算是小有進步。

係統組參會人員合照
實際上開會聊天是很高效的交流手段,而吃飯時間更是極好的溝通的機會。如果遇到一些年長的研究員,他們經常會分享一些高層次的對於研究方向和領域發展的思考,甚至是一些人生經驗。如果遇到跟自己相關領域的論文的作者,那麼就很容易能聊到論文新方法下的一些細節問題,其實透過作者讀論文往往是最快的方法!眾所周知,很多國際頂級學術會議涉及領域的範圍很廣,就拿NSDI來說,網絡係統領域的研究跨度很大,而近幾年交叉領域的新工作也比較多,聊天時經常會遇到自己可能還沒接觸到的研究麵,這時候與同行的交流經常能腦洞大開,相互激發新想法。這次的NSDI恰好是在學術重鎮波士頓舉行,波士頓周圍彙聚了很多著名的高校,包括著名的麻省理工學院(MIT)和哈佛大學。這帶來的一個好處就是參會的人不隻有網絡係統相關的研究員和論文作者,更有不少來自這些高校的PhD們,他們使參會人員更加多元化。俗話說的好,他山之石可以攻玉,很多前瞻性的文章和新穎的方法就是在這樣的跨界交流中提煉的。
這是我第二次參加國際學術會議,而不同於以往,這次我需要在大會上就自己的工作做近半小時的口頭報告。這裏要非常感謝我在微軟亞洲研究院係統組的同事們,從PPT到演講內容他們都幫我進行了細致的修改,還安排了三次的排練並教會我很多演講上的技巧。
盡管是早有準備,但我在前往波士頓的飛機上卻還是愈發的緊張和焦慮。然而就在當我剛到會場進行注冊的時候,我遇到了去年暑期在雷德蒙研究院實習時認識的研究員Amar,他的一句“溫控 ”(在英語使用者看來我的名字Wencong是應該這麼發音) 和爽朗的笑聲把我的思緒從陰冷的波士頓帶回了美麗的西雅圖的夏天,到那個大家都非常努力非常有愛的99號樓,一切的緊張和壓抑瞬間得到了緩解。當我站上演講台之後,與其說有那麼點緊張更不如說是一種興奮,看著下麵目光灼灼的“同學們”,我覺得自己更像一個傳播知識的老師,責任重大。
在完成了演講之後的茶歇,一位不認識的研究員突然跑過來,我看了一下名牌才發現,竟是大名鼎鼎的PowerGraph和GraphX的作者Joseph!他稱讚了我們的工作,並分享了他的一些相關的思考,包括係統設計層麵以及機器學習等。我非常開心自己的工作得到了肯定,通過自己的一些微小的工作,能讓大家在分布式係統的設計實現上看到一個新的方法,有一些新的啟發,我很自豪也很滿足。
焦點透視下麵我將從獲獎論文、微軟Azure的重磅工作、數據中心研究、以及機器學習相關係統4個方麵介紹一些NSDI上的論文。
獲獎論文
本屆NSDI共頒發了兩個獎項,Community Award(社區貢獻獎)和Best Paper Award(最佳論文獎)。其中Community Award被Dropbox斬獲,而來自Korea Advanced Institute of Science and Technology (KAIST) 的mOS則在眾多歐美名校的頂級網絡係統工作中脫穎而出,摘得了唯一的Best Paper Award!
Dropbox在論文The Design, Implementation, and Deployment of a System to Transparently Compress Hundreds of Petabytes of Image Files for a File-Storage Service中介紹了他們的圖像數據壓縮係統Lapton【1】,已經部署在Dropbox這樣一個世界範圍的雲存儲係統中,可以無損壓縮JPEG圖像文件到原來大小的77%。截至到2017年1月,已經壓縮高達數百個PB的數據,節省了46PB的存儲空間。這個係統已經在Github進行了開源。
KAIST的mOS則主要解決帶有狀態的網絡數據流層麵的MiddleBox的編程可重用性問題。MiddleBox是指網絡中部署的帶有除了包轉發以外功能的係統,比如說防火牆就是一個常見的MiddleBox應用,用於過濾未經許可的網絡流量。電信係統中對於蜂窩數據流量的計算和實時監控也是另外一個典型的MiddleBox應用。實現MiddleBox應用通常需要對於每個連接的數據包和狀態進行監控和處理,從而需要自己實現很多相應的包轉發等功能,KAIST的研究員提出了一套高層次編程接口,使得用戶隻需要專注於實現MiddleBox的應用,隱藏了底層數據流處理的邏輯,避免了複雜而易錯的數據流管理部分的重複性編程。而在底層,mOS通過一個高效而靈活的事件係統,支持百萬量級並發流事件的處理。mOS係統已經在Github上開源,相信會給MiddleBox的研究和產品帶來諸多的便利。
微軟Azure的重磅工作
微軟在這樣一個網絡係統領域的盛會中繼續保持著自己的重量級地位,參與了總共40篇文章中的9篇文章的工作,為工業界之最,表現搶眼。而微軟的研究員也在本屆NSDI的多個session中擔任主席。在近幾年的網絡係統研究中,一方麵微軟研究院不僅自己發表研究文章,並且還聯合其他多個科研機構以及其學生合作發表了多篇研究文章,另一方麵微軟的產品部門Azure也不斷發表文章介紹了他們在實際生產環境中的先進工作和經驗。
Azure雲服務是世界上最大的公有雲服務之一,微軟Azure的數據中心散布在世界各地,包含高達百萬量級的機器數目。Azure把虛擬機賣給客戶,需要給虛擬機的網絡提供防火牆、負載均衡等網絡功能,鑒於此,微軟的Azure team在數據中心設計中大規模實踐SDN。
在本屆NSDI的SDN and Network Design session,微軟Azure數據中心負責Host SDN team的Daniel Firestone介紹了他們長達8年的Host SDN的項目經驗,披露了核心係統——Virtual Filtering Platform (VFP) 【3】這樣一個端係統上的可編程端虛擬交換機的設計和實現細節。VFP已經部署在超過一百萬台的Azure服務器上,穩定的支持IaaS和PaaS的服務長達4年的時間。
第一階段的VFP項目著重在可編程性上,允許不同用戶能獨立的編寫網絡策略而不相互影響,並且支持網絡連接層麵的狀態化信息,還能夠編寫靈活的網絡策略。
第二階段的VFP項目則著重關注在可維護性和性能兩個層麵,一方麵提供熱部署的功能,另一方麵在基於FPGA 實現的SmartNIC的支持下,通過Unified Flow Table設計和Hardware Offloads,使得VFP在保持最開始的靈活軟件定義的特性下,能夠高效的支持40Gbps和50Gbps的高速數據中心網絡。進一步的,SmartNIC對每個服務器上運行著的虛擬機抽象出一塊虛擬網卡,虛擬機通過SR-IOV技術即可直接訪問這塊虛擬網卡,使得虛擬機收發網絡數據包都不需要CPU計算單元的參與,做到了CPU-bypass,既節省了CPU資源又降低了網絡延遲,並且更具經濟性。
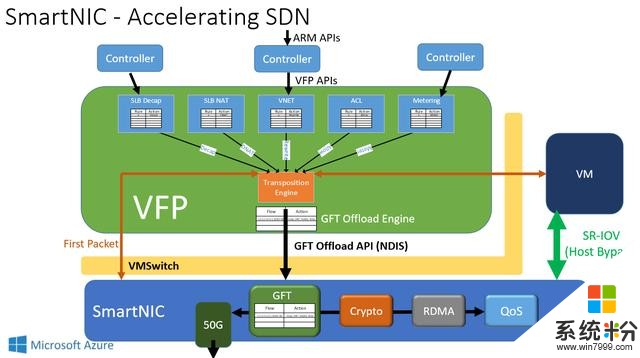
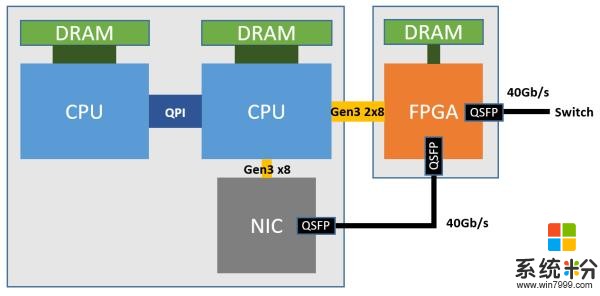
在如今的Azure數據中心中,正如下圖所示,每一台服務器上都插上了一塊FPGA,部署在本機網卡與外部網路之間,並通過PCIe連接到服務器上,FPGA 之間通過 LTL (Lightweight Transport Layer) 通信,在微秒級別的時間內就可以到達數據中心內任何的FPGA,真正做到了低延遲高帶寬。這樣一種部署的方式和軟硬件協同設計的方法讓FPGA從CPU中接手網絡功能並進一步加速了SDN,使得Host SDN得以在如今的高帶寬數據中心網絡中部署。軟件定義網絡以這樣一種全新的方式與硬件相融合,兼具靈活性與高效性。
持續火爆的數據中心研究
數據中心的研究一直是NSDI上的焦點,很多的工作都圍繞著數據中心的網絡來展開。
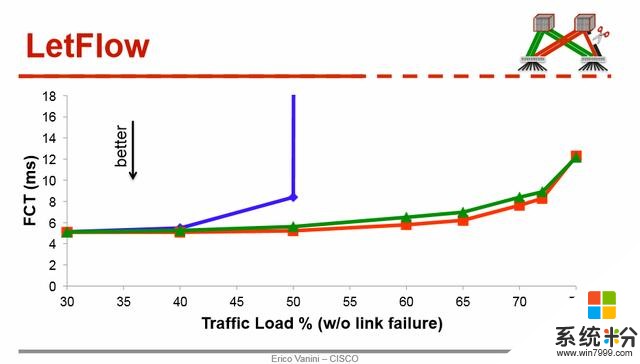
負載均衡(Load balance)和擁塞控製(Congestion control)一直是數據中心網絡中的經典問題。在14年的Sigcomm上,思科發表了CONGA,在如今看來仍然是state-of-art的congestion-aware load balance機製,在今年的NSDI上,他們又卷土重來,在文章Let it flow【4】中提出了一個非常簡單的負載均衡方法,延續了他們在CONGA裏麵的思路:與其在每個數據包上做負載均衡,不如考慮在Flowlet的粒度上做。這裏的Flowlet可以認為是以時間維度來切分的批量網絡包。其簡潔的新負載均衡算法,一言以蔽之,即隻要隨機的安排Flowlet到可用的網絡路徑上即可均衡流量。這種看似隨機的做法其實卻能非常好的感知網絡擁堵,從而做到負載均衡。這一做法的深層次原因在於:在擁塞嚴重的路徑上,Flowlet的大小會降低,而在通暢的路徑上,Flowlet的大小會增長。這一機製(下圖綠色) 比現有的很多流量均衡方法都有顯著優勢,而比起複雜的機製CONGA(下圖紅色),也隻有10~20%的差別。
在另一個工作Flowtune【5】中,MIT的研究員則關注網絡帶寬分配的收斂速度問題。在數據中心網絡中,網絡管理者會事先基於不同的策略定義優化的目標,把網絡的帶寬迅速的分給當前的數據流。這個優化目標是事先定義好的,比如說可以是流之間公平性(Fairness)或者流完成時間(FCT)。傳統的網絡帶寬分配這方麵工作基本都是基於數據包(packet)這個粒度,收斂到目標狀態所需要的時間相對較長。這篇文章提出按照Flowlet的粒度來分配網絡帶寬,每一個Flowlet都由一個中心化的控製器來決定發送速率。這裏麵關鍵的問題是如何快速計算出收斂到的最優速率,針對這一挑戰,他們提出了一個新的Newton-Exact-Diagonal方法來解決這個問題,並且設計實現了一個在CPU上的多核並行可擴展的係統。
機器學習和網絡係統
隨著機器學習和人工智能係統的迅速發展,以及這些技術在生產環境中的大規模應用,很多網絡係統的工作開始研究如何針對性的優化這些新應用。這屆的NSDI大會上湧現出了不少跟機器學習相關的文章,研究員們並不隻停留於設計實現網絡係統來為機器學習算法應用服務,還有更多的學者將機器學習方法應用到網絡係統的實際問題之中,而這個角度的工作相對來說是比較少的,十分令人欣喜。
Curator【6】是華盛頓大學和Nutanix合作的係統,它是一個部署在後端的MapReduce-style的框架,用於處理存儲係統中的後台任務,比如說磁盤碎片整理,冷熱數據搬運,備份數據等。論文介紹了他們多年來在分布式存儲係統設計上的經驗。值得一提的是,他們提出了用強化學習的方法來去確定SSD和HDD中分別存儲的數據量,並稱相較於經驗性的閾值策略方法會降低20%的延遲。
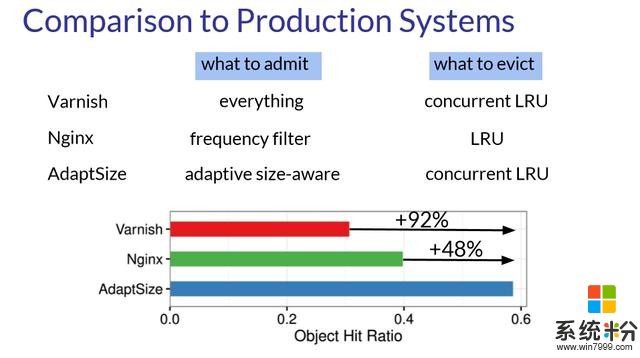
無獨有偶,這種動態閾值的思想在這屆NSDI大會中關於內容分發網絡(CDN)相關的工作AdaptSize【7】也得到了體現。CDN是一種節點散落在不同地理位置的大規模分布式係統。舉例來說,很多網絡應用中需要的資源,例如視頻和圖片等這樣的靜態資源,就可以預先緩存在就近的節點上。當用戶請求數據時,CDN係統根據網絡狀態的實際情況重定向用戶請求到就近節點上,以方便用戶的訪問。這樣既減輕核心服務器的負載壓力,又降低了獲取資源的延遲,提高了用戶體驗。在CDN上,一般會區分冷熱數據,把用戶經常訪問的熱數據 (Hot object) 放在內存這樣的低訪問延遲的存儲模塊中,而剩下的放在磁盤中,這樣內存中的熱數據就構成一個緩存。這裏最關鍵的問題就是,什麼樣的數據需要放進內存,現有的做法無非是把全部都放進去然後根據訪問頻率把低頻的踢出,或者是基於一個閾值把小數據放進去,畢竟小數據更加劃算。這篇文章采用一個馬爾可夫模型,根據請求的模式 (Request pattern) 自動調節相應閾值決定緩存的文件大小,進而獲得更好的緩存命中率。這個論文的結果非常的令人振奮,相比於現有的其他方法有近20個百分點的提升!
不隻是CDN,這種方法很容易應用到其他的相似場景,即上層有複雜而多變的數據訪問模式(Access pattern)的帶有緩存的係統。
更進一步的說,在係統中引入機器學習方法來代替固定的閾值,我認為是一個相對通用的方法,並且這種方法有可能在很多情況下都會有好處。係統或者網絡本身也許能學習感知到上層不同應用不同的數據訪問模式,從而自適應其特性,調整到更加合適的配置之下。然而這又為係統本身增加了複雜性和不確定性,畢竟穩定性、簡單可靠、乃至可複現是基礎設施平台一直以來的追求。所以說,這並不是放諸四海皆準的靈丹妙藥,但是也是一個很有趣的新思路。
CherryPick【8】是來自耶魯和微軟等四個機構的多方合作項目,其研究關注在雲係統的調度層麵,一個雲端服務可以應用不同的係統配置。然而,為了達到相同的性能,不同的配置可能會導致高達12倍乃至更多的成本耗費上的差別,這一點在重複性作業 (recurring job) 上顯得尤為突出。自動的在低搜索空間下為雲端服務找到最優配置所帶來的經濟性自然是不言而喻。文章使用了一個簡單的貝葉斯優化 (Bayesian Optimization) 來幫助優化搜索過程,決策搜索哪個配置下的運行性能,以及什麼時候停止搜索以找到最優的係統配置。我覺得這個工作建模的係統指標項還是相對來說比較簡單的,僅考慮任務占用的VM、CPU、內存、磁盤、網絡等靜態係統指標,並不考慮數據、係統當前總資源占用、任務間的相互幹擾之類的當前整個係統狀態相關的問題。其使用簡單模型針對這一特定問題固然有其好處,但是不一定適合更加複雜的情況。正如Google曾透露他們已經試圖用強化學習優化一些調度問題一樣,我相信機器學習在係統領域應用的研究才剛剛開始。采用數據驅動的方法,通過對於數據的分析和問題的建模,可以幫助我們加深對於複雜係統的理解,減少乃至避免經驗性的閾值和靜態配置,而這些新的方法論最終將反過來影響網絡係統的設計。
VideoStorm【9】是普林斯頓的Haoyu在微軟研究院實習的時候做的工作。隨著DNN在圖像視頻領域的物體識別追蹤上的不斷發展,利用這一方法實時的分析監控攝像頭的數據,完成如車輛追蹤這樣的人工智能任務已成為現實的需求。這篇文章針對這樣一個典型的人工智能應用,探討在給定資源下,綜合考慮多種視頻流任務的不同質量和不同延遲這一需求,如何分配雲端資源來同時處理成千上萬個視頻流數據任務的方法。這個係統已經在美國華盛頓州的貝爾維尤市完成部署,為實時交通數據的分析服務。這個實際的問題是深度學習從理論走向實踐的過程中會遭遇的現實挑戰,隨著更多這種應用的部署,相關的網絡係統都蘊含著更多類似的新研究機會。
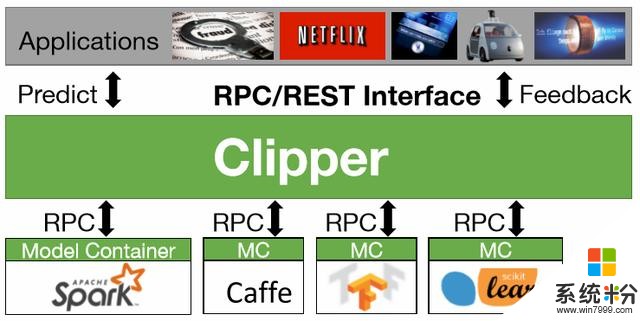
Big Data session中的四篇文章有三篇跟機器學習相關,第一篇是來自於伯克利RICE實驗室,其前身是AMPLab,其產出不止包括有影響力的論文,更是有影響力的開源項目和創業公司,由Databricks公司主導的Spark項目已經在大數據領域發展出繁榮的生態鏈。而在這次的NSDI上,他們發表了Clipper【10】係統。這是一個以通用性和低延遲為目標的機器學習服務(serving) 係統,對用戶端提供統一的接口,而底層則適配多種框架,包括 Spark MLlib,Caffe,Tensorflow,Scikit-Learn等,從而簡化這種服務係統的部署工作。Clipper係統通過應用緩存(caching),批處理(batching),以及自適應模型選擇(adaptive model selection)來優化延遲,提高吞吐率、準確率、和魯棒性。在當前機器學習技術廣泛應用,深度學習框架繁榮發展的現狀下,Clipper攜Spark在大數據係統上的領先地位和MLlib,試圖用一個前端框架一統model serving部分,可以說是雄心勃勃。然而不同於大數據時代,如今深度學習有更多的底層框架,比如說CNTK和MXNet,也更加依賴異構的硬件平台,比如說GPU、FPGA和以Google的TPU為代表的ASIC,以及計算密集型應用要求對於性能上的極致壓榨,這些都為大一統平台帶來了更多的挑戰。這次他們能否成功,我們將拭目以待。
第二篇則是來自CMU的Gaia【11】,討論如何設計係統來對基於全球分布(geo-distributed)的機器學習數據進行訓練。現在很多全球化的服務,比如說搜索引擎,都是部署在世界各地的數據中心中就近服務世界各地的用戶。數據中心內部一般都部署有低延遲高帶寬的網絡,而數據中心間的互聯網(WANs)則可能很慢,直接在不同數據中心間的數據上訓練機器學習模型,其訓練過程會嚴重受限於數據中心間的網絡,文章報告了高達53x的性能下降。這個工作通過解耦數據中心內部和外部的同步模型來優化性能,提出了一個新的一致性模型 (Approximate Synchronous Parallel) 來進一步的減少數據中心間的網絡通信,並且保持機器學習模型的收斂率。這個工作和Google日前宣布的Federated Learning的工作都是旨在考慮互聯網範圍內機器學習模型的訓練問題,後者將訓練數據分散到成千上萬的用戶手機中,協同訓練機器模型以提升模型質量,降低延遲。一方麵數據中心間乃至普通互聯網中的網絡存在帶寬低、延遲高、不穩定等問題,另一方麵機器學習模型又具有一定程度的容忍錯誤和延遲更新的特性,這涉及到網絡和機器學習算法的協同設計(co-design)的問題,非常的有趣。
第三篇是我們的工作TuX²(圖學習)【12】,是一個為分布式機器學習設計的全新圖計算引擎。
圖計算是一個經典的問題,很多的圖計算係統都專注為諸如PageRank這樣的經典圖計算問題優化,提供簡單而並行無關的編程模型,並且可以在係統內部感知圖結構進行係統層麵優化,從而高性能地進行橫向擴展,支持海量數據。我們的上一個工作,被錄取在SoCC’15上的GraM【13】已經可以高效支持高達萬億(trillion)邊數的超大規模圖計算。
基於我們對於機器學習應用的思考,我們發現多種重要的機器學習算法都有內在的圖結構模型。然而與圖計算算法不同,機器學習算法並不是很適合用現有的圖計算引擎來處理,原因可以分為兩個層麵,其一是缺乏對於重要機器學習概念的支持,例如小分批(mini-batch)和寬鬆的一致性模型,其二原有圖模型過於簡單並且在模型抽象上靈活性過低,從而為機器學習算法編程和高效執行都帶來了問題。
有鑒於此,為了利用圖計算的優勢同時又解決上述的問題,我們提出了分布式機器學習係統——圖學習TuX2 (Tu Xue Xi)。TuX2相比於傳統的圖計算引擎,在數據模型、調度模型、編程模型三個方麵都做了關鍵的擴展,全新的圖模型MEGA更是使得分布式圖計算引擎在保持原有的高效性的同時擁有更多的靈活性,支持Mini-Batch和靈活一致性模型等關鍵的機器學習概念,並且更適合編寫複雜的機器學習算法。

性能方麵, 在高達640億條邊的大規模數據上的實驗充分說明,TuX2相比當前最好的圖計算引擎PowerGraph和PowerLyra都取得了超過一個數量級上的性能提升,這一成績背後離不開我們的異質性(heterogeneity)圖節點優化和新編程模型MEGA。而對比現有的兩大機器學習係統,Petuum和ParameterServer,TuX2在大幅度減少代碼量的同時帶來了至少48%的性能提升,這主要是因為我們的圖編程模型MEGA的高層次抽象以及圖計算係統基於圖結構優化。
要知道,大規模分布式機器學習模型的訓練成為很多產品線的重要部分並且耗時良久,我們係統顯著的性能提升(Efficiency)有效的節省了計算資源,而其擴展性(scalability)使得支持更大規模的數據成為可能。
我們的願景是希望TuX2能夠真正連接圖計算和分布式機器學習兩個研究領域,讓更多的機器學習算法和優化能夠很簡單的在圖計算引擎上實現,從而利用好眾多的圖結構優化技術來進行係統層麵的優化,將兩個領域的研究工作更好的結合在一起,為人工智能的未來服務。
作者簡介
肖文聰
肖文聰,本科畢業於北京航空航天大學計算機學院,2014年加入北京航空航天大學與微軟亞洲研究院的聯合培養博士生項目,導師是北航的李未院士和微軟亞洲研究院副院長周禮棟博士。研究方向是大規模分布式圖計算和機器學習係統。
相關論文:
【1】Lapton:The Design, Implementation, and Deployment of a System to Transparently Compress Hundreds of Petabytes of Image Files for a File-Storage Service
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/horn
【2】mOS: A Reusable Networking Stack for Flow Monitoring Middleboxes
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/jamshed
【3】VFP: A Virtual Switch Platform for Host SDN in the Public Cloud
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/firestone
【4】Let It Flow: Resilient Asymmetric Load Balancing with Flowlet Switching
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/vanini
【5】Flowtune: Flowlet Control for Datacenter Networks
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/perry
【6】Curator: Self-Managing Storage for Enterprise Clusters
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/cano
【7】AdaptSize: Orchestrating the Hot Object Memory Cache in a Content Delivery Network
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/berger
【8】CherryPick: Adaptively Unearthing the Best Cloud Configurations for Big Data Analytics
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/alipourfard
【9】VideoStorm:Live Video Analytics at Scale with Approximation and Delay-Tolerance
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/zhang
【10】Clipper: A Low-Latency Online Prediction Serving System
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/crankshaw
【11】Gaia: Geo-Distributed Machine Learning Approaching LAN Speeds
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/hsieh
【12】Tux²: Distributed Graph Computation for Machine Learning
https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/xiao
【13】GraM: scaling graph computation to the trillions
http://dl.acm.org/citation.cfm?id=2806849&CFID=926649994&CFTOKEN=39893429
相關資訊
最新熱門應用

比特牛交易所官網app蘋果版
其它軟件26.64MB
下載
火bi交易所
其它軟件175MB
下載
比特兒交易平台app安卓手機
其它軟件292.97MB
下載
歐意交易所官網安卓版
其它軟件397.1MB
下載
歐意app官網
其它軟件397.1MB
下載
bitcoke交易所
其它軟件287.27 MB
下載
比特兒交易所app安卓版
其它軟件292.97MB
下載
幣咖交易所官網
其它軟件86.26MB
下載
bafeex交易所app
其它軟件28.5MB
下載
必勝交易所
其它軟件52.2 MB
下載