
選自Microsoft Blog
作者:Allison Linn
機器之心編譯
參與:李亞洲、黃小天

Rangan Majumder、Yi‐Min Wang 和高劍鋒(自左至右)在微軟雷德蒙德研究院。
微軟的研究員目前已經創造出了能夠像人類一樣完成兩種困難任務的技術:圖像識別和語音識別。現在微軟的頂級人工智能專家正在研究能夠完成更複雜任務的係統:閱讀文本進而回答問題。
Maluuba 的聯合創始人 Kaheer Suleman 說到,「我們正在嚐試開發一種文獻機器:它能閱讀、理解文本,然後學習如何交流,無論是筆錄還是口述。」微軟在今年年初時收購了這家創業公司。
機器閱讀係統也能幫助醫生、律師和其他專家更快地完成文檔閱讀這樣的苦差事,從而讓專家們有更多的時間治療病人或構想合法抗辯。
Maluuba 團隊是微軟幾個解決機器閱讀難題的團隊之一。其他兩個團隊,一個在華盛頓雷德蒙,一個在北京的研究室。這兩個團隊在斯坦福大學的 SQuAD 數據集上正在展開競爭,使用 Wikipedia 上的信息測試人工智能係統回答問題的能力。
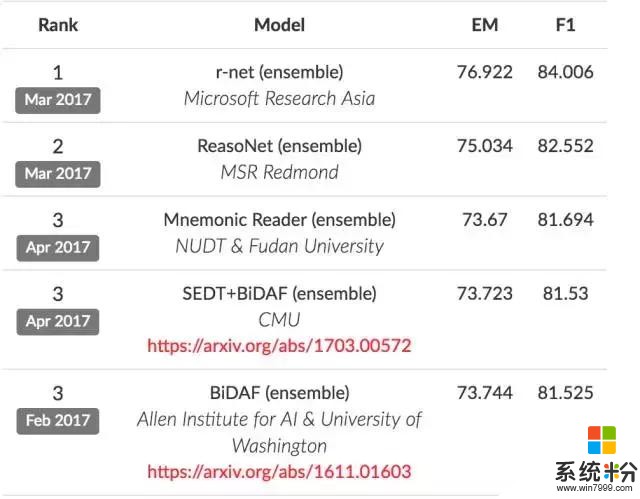
在 SQuAD 數據集上的排名
SQuAD 數據集是機器閱讀這一新興領域的核心基準,許多頂尖的學術或產業團隊都在使用它測試自己的係統。它類似於 ImageNet 競賽,激勵著計算機視覺的發展。此外,微軟研究員和其他來自學界、產業界的團隊也在使用另一個數據集 MS MARCO 進行激烈競爭,MS MARCO 數據集使用來自 Bing 搜索詞條的真實、匿名數據來測試係統回答問題的能力。
團隊成員說這是一個有附加值的挑戰,因為它是基於人類的真實問題。在這種數據上測試能保證建立的係統最終對客戶有用。
微軟 Bing 部門合作夥伴組的一位項目經理 Rangan Majumder 說:「我們不隻要獎勵一堆算法解決理論問題,我們也要使用它們解決真實問題,在真實數據上進行測試。」他與雷德蒙德機器閱讀研究團隊有密切的合作,並領導開發了 MS MARCO 數據集。

前排左二的韋福如、前排中間周明、以及微軟亞洲研究院自然語言研究團隊的成員
認知 VS 感知
總體而言,人工智能專家認為機器閱讀要比圖像識別這樣的人工智能任務更困難,因為中間有太多模糊不清的地方。
北京微軟亞洲研究院的周明博士表示,圖像識別這樣的技能是感知型任務:基於係統之前見過的圖像,使用機器學習算法進行識別。目前,周明博士帶領著微軟亞研的自然語言研究組。
機器閱讀是更複雜的認知型任務:它需要係統有大局觀,查看它所讀取文字的語境,甚至需要加入自身已有的關於這個主題的背景知識。
周說:「一些詞可能有不同的含義,而相同的事情可能用不同的方式提及。」
另一個複雜性在於:給出的回答可能不包含問題中的詞彙,甚至可能一個都沒有。
例如,讓我們假設有人問,「John Smith 的國籍是?」答案可能是,「John Smith 生於美國」,或者「他有美國護照」。在任何情況下,係統需要尋找、使用關聯國籍的信息,但可能不會明確的說國籍這個詞。
微軟深度學習技術中心的高劍鋒表示:「它需要生成一個答案,而且該答案與已有的都不同。」
Maluuba 的聯合創始人 Suleman 提到,這正是人們如何測試其他人學習內容的方式。問問題,從小就開始問,並貫穿一生。
他們團隊如何進一步推進機器閱讀任務?這是一句深入的描述,「他們正在研發一種能夠閱讀文章並構思問題的係統,而不隻是回答。該研究受啟發於 20 世紀 80 年代的一個研究,研究表明在答題測試中,學生被要求寫下關於一個主題的問題時會做的更好。」
Suleman 說:「有趣的是,生成問題時(而非回答)你真的需要更深入地理解文本。」

從左開始,依次是 Muluuba 聯合創始人 Kaheer Suleman 和 Sam Pasupalak
搜索引擎的終結
機器閱讀如此誘人是因為它對許多人都有很大幫助。
例如,高效的機器閱讀係統能夠推進搜索引擎的工作。相比於敲打詞條,然後獲得一堆鏈接,先進的機器閱讀係統能像一個知識淵博的人回答問題一樣給出解答。
高說,「它以自然的方式傳遞信息。」
大部分搜索引擎隻能做基礎的詞條搜索,而且不是人們期待的那種要複製所有的信息。
機器閱讀係統也能幫助醫生、律師以及其他專家更快地閱讀專業的醫學或判例文檔,從而讓他們有更多的時間對病人進行治療或構思合法抗辯。
它也能幫助人們更快地發現隱藏在汽車使用說明書或稅務條例中的信息,節約時間。
高說:「世界中有大量信息,尤其是互聯網中;為了讓信息產生價值,需要將其轉化為知識,而機器閱讀技術可以在信息與知識之間搭建一個橋梁。」
數十年的研究以及最新進展
微軟機器閱讀工作的根基可以追溯到大約 20 年之前研究者在自然語言處理領域所做的早期工作。那時,微軟的自然語言處理方麵的首席研究員 Bill Dolan 開玩笑說,係統的工作隻是偶爾很完美。
盡管如此,這一基礎性工作正在被整合進算法之中,雷德蒙德團隊正是借助這一算法取得了當前機器閱讀的絕大多數進展;該算法還是 Dolan 及其團隊在自然語言處理方麵取得的其他突破性成果的基礎。
正如過去幾年出現的人工智能進展,機器閱讀也從更好的深度學習算法、大幅提升的雲計算能力和海量數據中大受脾益。
研究者說這些能力,連同深度學習方法在圖像和語音識別領域的進步,已經使他們自信地感覺到機器閱讀的重大突破盡在眼前。這正是許多人依然驚奇的事情。
微軟亞洲研究院自然語言處理組首席研究員韋福如說:「這對於從事自然語言處理甚至是人工智能的研究者來說是一個長期的夢想。」
盡管如此,研究者警惕說,為了創造出可以同時在語言及其細微差別方麵真正理解人類訴求的係統,仍然有大量工作要做。
通常來講,人工智能係統仍然隻擅長處理特殊任務,它們也許能夠找到問題的正確答案,精確識別出狗的品種或者人類的情緒狀態,甚至理解會話中的詞語;但是,研究者指出,這並不意味著它們可以人類一出生就具有的方式理解信息,注意到所有的細微差別和語境。
韋福如指出,即使機器閱讀團隊的係統可以在 SQuAD 數據集中和人表現的一樣好,但並不意味著機器可以像人一樣真正閱讀和理解,這是未來必須要麵臨的一個挑戰。
周說:「這隻是通向自然語言理解巨大挑戰的一小步。」
相關資訊
最新熱門應用

幣團交易所
其它軟件43MB
下載
必安交易所官網
其它軟件179MB
下載
bicc數字交易所app
其它軟件32.92MB
下載
比特國際網交易平台
其它軟件298.7 MB
下載
熱幣交易所app官方最新版
其它軟件287.27 MB
下載
歐昜交易所
其它軟件397.1MB
下載
vvbtc交易所最新app
其它軟件31.69MB
下載
星幣交易所app蘋果版
其它軟件95.74MB
下載
zg交易所安卓版app
其它軟件41.99MB
下載
比特幣交易app安卓手機
其它軟件179MB
下載