

【新智元導讀】作為機器學習最熱門的領域之一,圖像識別是判斷AI聰明與否的一個重要標準。作為主要的參與者,微軟、IBM、穀歌和亞馬遜在這項技術上投入巨資,那麼,到底哪一家做得更好呢?研究發現,穀歌在圖像識別方麵取得了81.7%的準確率,僅次於人類,四家中排名第一。
機器學習最熱門的領域之一是圖像識別。有許多主要參與者在這項技術上投入巨資,包括微軟,IBM,穀歌和亞馬遜。但哪一個做得最好?
Perficient Digital的研究團隊發布了一份對這四家科技巨頭圖像識別的研究報告。報告顯示,穀歌在圖像識別方麵取得了81.7%的準確率,在四家中最高;IBM在圖像識別方麵取得了55.6%的準確率,在四家中最低。
本次研究涉及的圖像識別引擎包括:
亞馬遜AWS Rekognition穀歌VisionIBM Watson微軟Azure Computer Vision本次研究使用了2000張圖像,分為四類:
圖表風景人物產品每個圖像識別引擎返回的標簽總數如下:
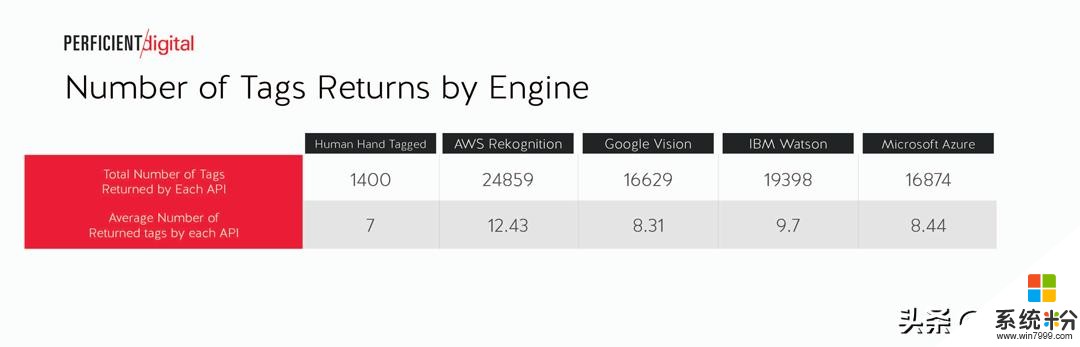
研究團隊使用兩種不同的方法來評估每個引擎:
來自每個圖像識別引擎的標簽的準確度(500個圖像),稱之為“準確度評估”。來自圖像識別引擎的標簽是否是描述每個圖像的最佳匹配(2000個圖像),這被稱為“匹配人類描述評估”。一、圖像識別引擎標簽準確度在準確性評估中,對500張圖像中的每一張,圖像識別引擎的每一個標簽都要評估其是否準確。有“準確、不準確和我不確定”三個選項(隻有1.2%的標簽被標記為“不確定”)。
這裏的區別在於標簽可以被判斷為準確,即使它是人類在描述圖像時不太可能使用的標簽。例如,室外場景的圖片可能被引擎標記為“全景”,並且完全準確,但仍然不是用戶想要描述圖像的標簽之一。
考慮到這一點,下表是每個引擎的得分:
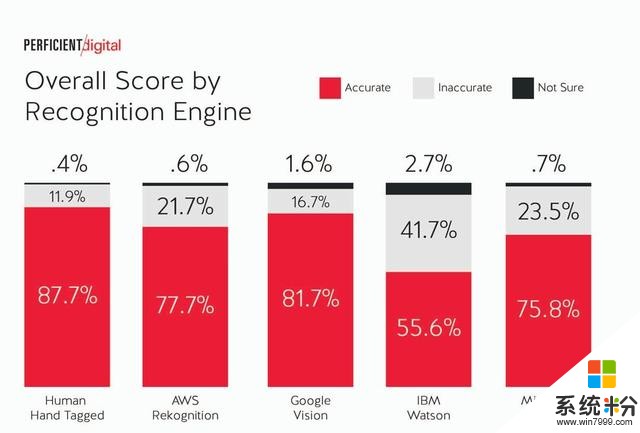
很明顯,贏家是穀歌Vision(準確率81.7%),亞馬遜AWS Rekognition排在第二位(準確率77.7%),微軟Azure排名第三(準確率75.8%),IBM Watson排名最後(準確率55.6%)。
置信水平以上分數涵蓋每個引擎返回的所有標記。但是,每個引擎也會返回他們對每個標記的置信度的分數。這使它能夠返回更具推測性的標簽。以下是每個引擎的置信度得分彙總的數據:
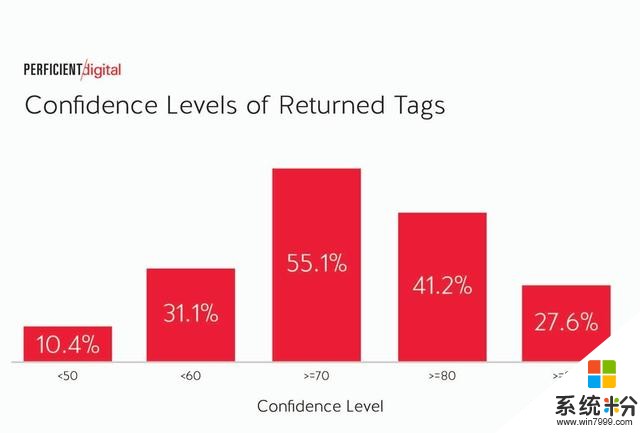
以下是引擎具有90%或更高置信度的所有圖像:
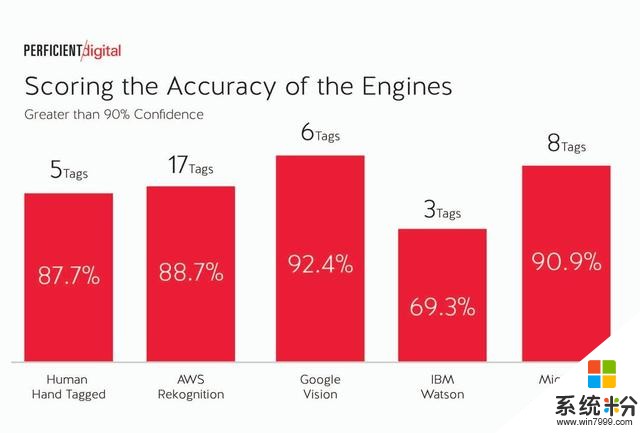
這些數據令人著迷的是,在純粹的準確性基礎上,四個引擎中的三個(亞馬遜,穀歌和微軟)的得分高於人類標記,最高置信度超過90%。
當我們將置信水平降至80%或更高時,讓我們看看這是如何變化的:
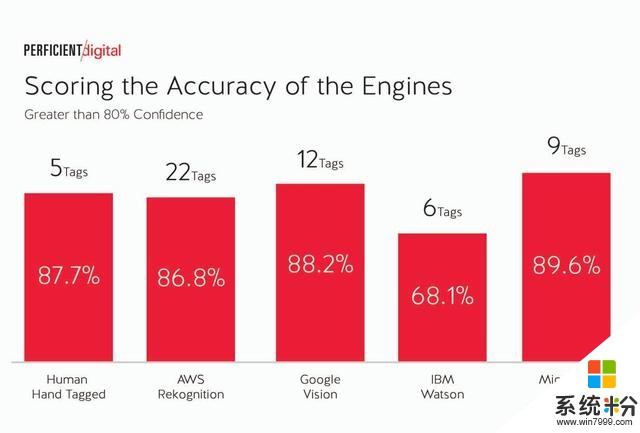
在這個級別,我們看到“人手標記”的分數基本上與我們在亞馬遜AWS Rekognition,穀歌Vision和微軟Azure Computer Vision中看到的分數相同。
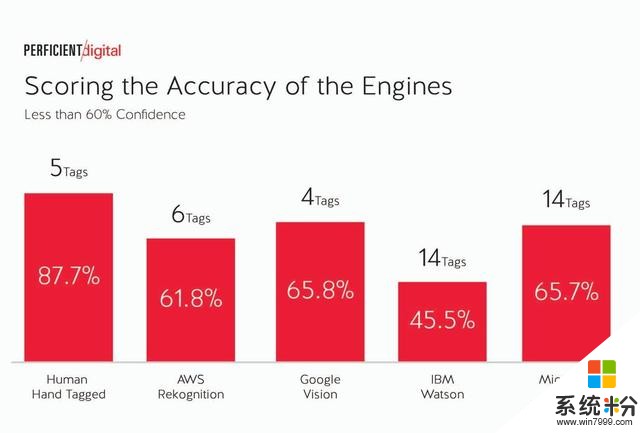
可以預期,給出低置信度的標簽的準確性會降低,事實證明是這樣的:
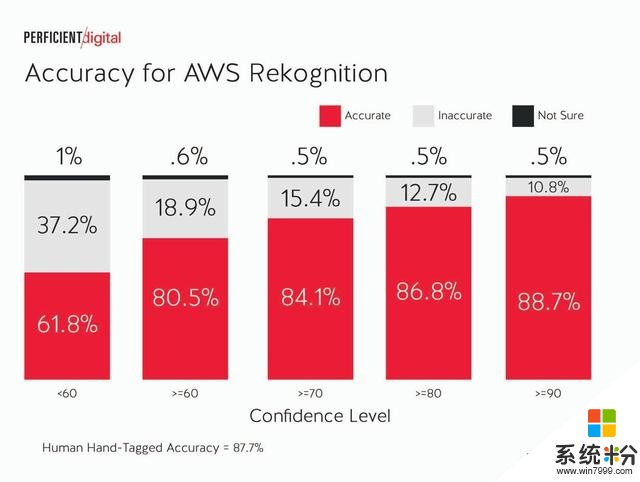
對於接下來的幾個圖表,研究人員通過圖像識別引擎在許多類別的置信水平上看準確性。
亞馬遜AWS Rekognition
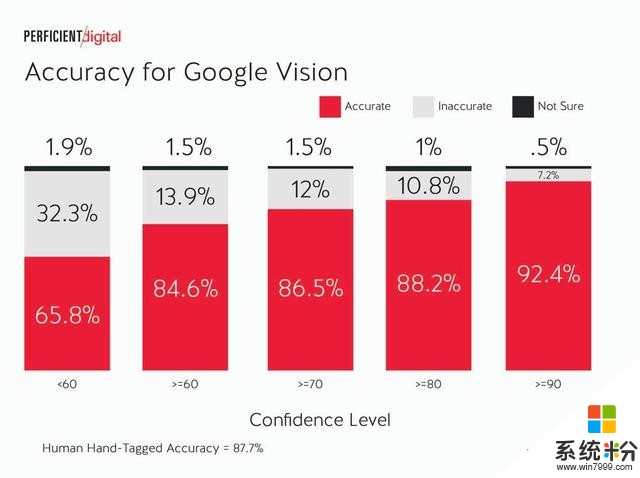
穀歌Vision:
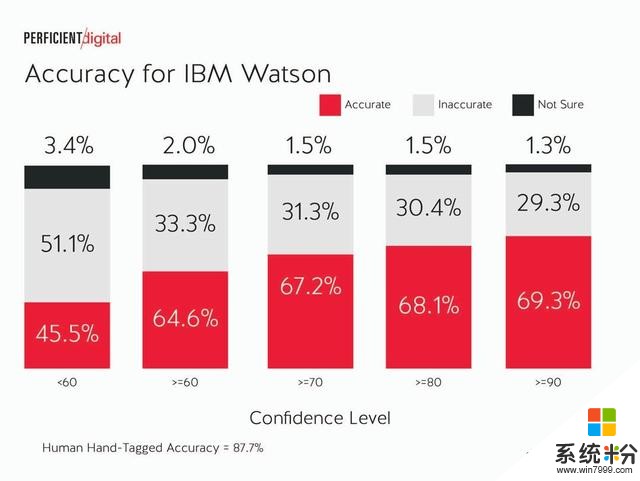
IBM Watson:
微軟Azure Computer Vision:
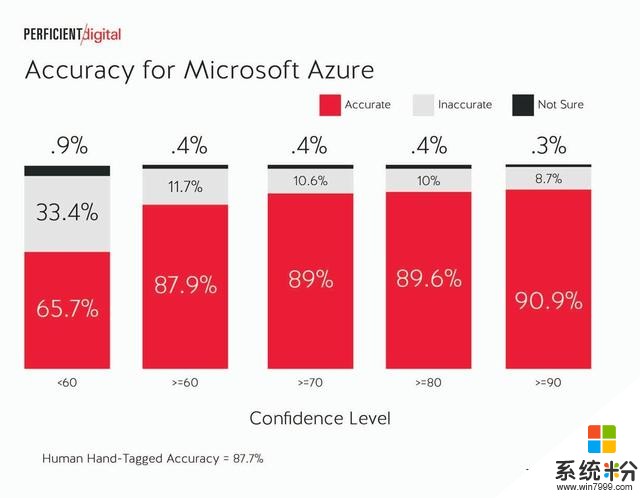
在所有的引擎中,我們都可以看到,它們在分配給更高置信度分數的標簽上做得更好。
二、圖像識別引擎與人類的想法相匹配的程度如何?匹配人類描述評估的不同之處在於,研究人員向用戶呈現了每個引擎為每個圖像提供的前五個最高置信度標簽,而沒有告訴他們來自哪個圖像識別引擎。
然後,在2000張圖像中,研究人員要求用戶選擇並排列他們認為最能描述圖像的前五個標簽。與之前的數據集不同,這裏的重點是最佳匹配人類的想法。這次評估的目的是看看哪個引擎最接近這一點。
對於數據,讓我們從平台的平均得分開始,總計:
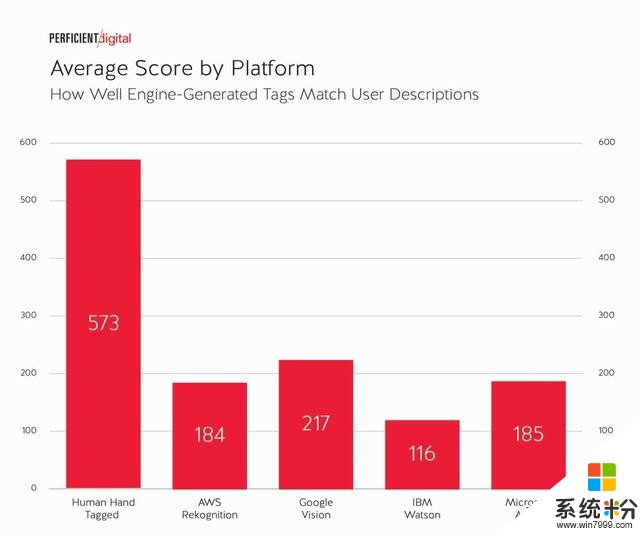
如圖所見,“手動標記”圖像的得分遠高於任何引擎。這是可以預料到的,因為手動標記的標簽的圖像描述是準確的。
四個圖像識別引擎和人類水平之間的差距非常大。值得注意的是,四個引擎中Google Vision明顯性能更高,但手動標記結果的選擇頻率仍遠高於任何引擎給出的結果。
總之,人類仍然可以比機器API更好地識別圖像,並對其他人解釋自己的看法。這是因為幾個因素的作用,其中包括語言的特異性、具備廣闊背景知識基礎的引擎常常會關注對人類沒有重大意義的屬性,因此雖然這些屬性是準確的,但人類更有可能描述他們的感受,更準確地識別圖像。
下圖為按圖像類型分類的分數視圖: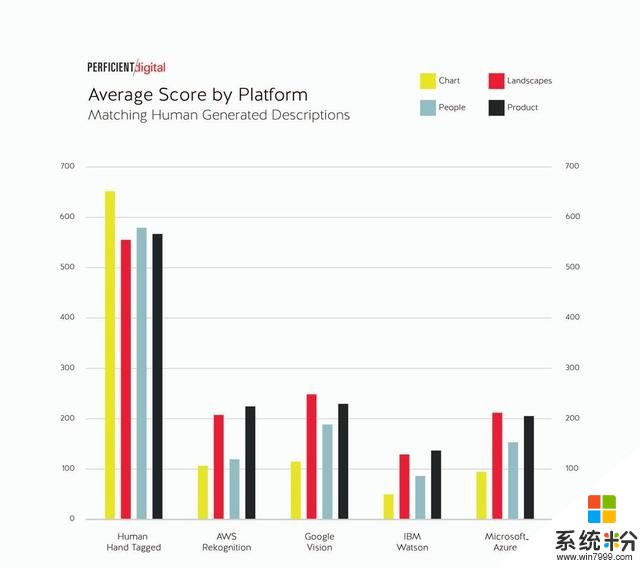
按圖像類別劃分很有意思。人類手動標記的標簽仍是每個類別中目標最多的標簽。Google Vision在四個類別中的三類中獲勝,亞馬遜AWS幾乎沒有在任何類別中占據優勢。
當引擎標簽的置信度為90%以上時,四個引擎中的三個得分高於人工標注標簽。
三、圖像識別引擎的詞彙表本研究最有趣的發現之一就是不同平台上詞彙引擎的變化情況。以下是參與比較的四個平台的原始數據,以及我們的“手動標記”結果。
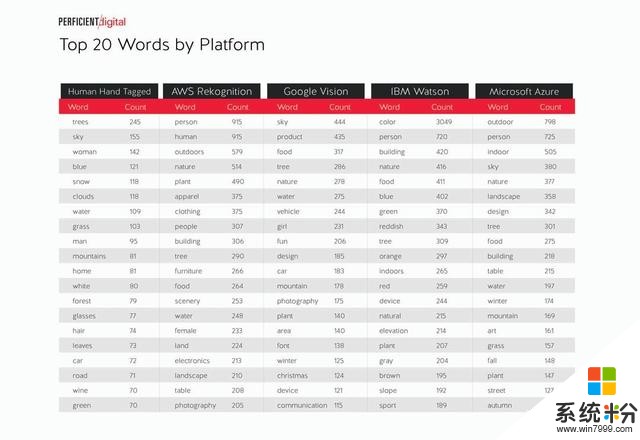
當然,根據圖像類型不同,詞彙發生變化是自然而然的事情(詳細數據以下給出)。
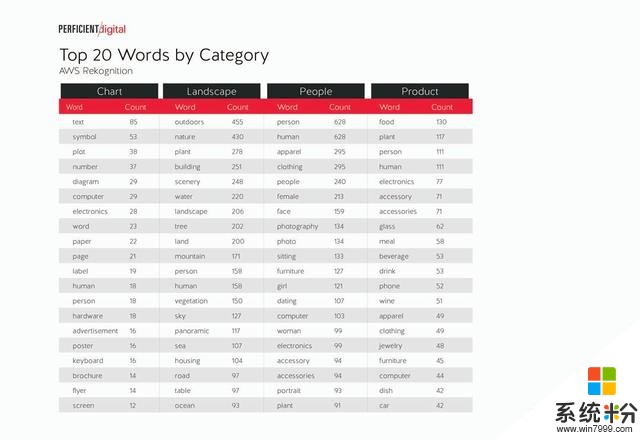
下圖為AWS Rekognition的結果:
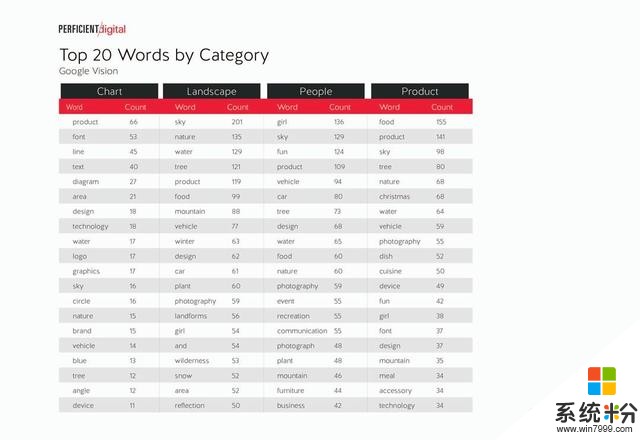
Google Vision:
IBM Watson:

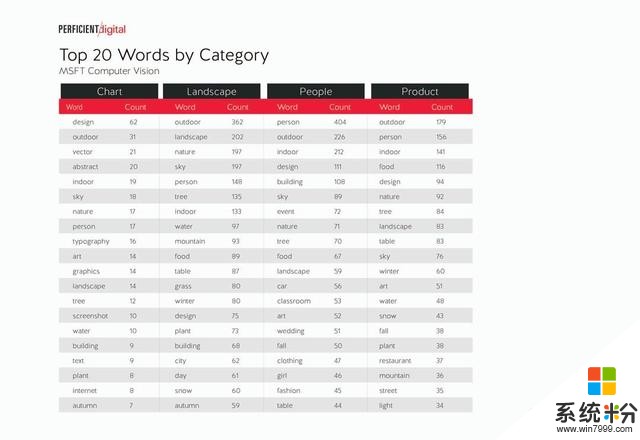
微軟 Azure Computer Vision:
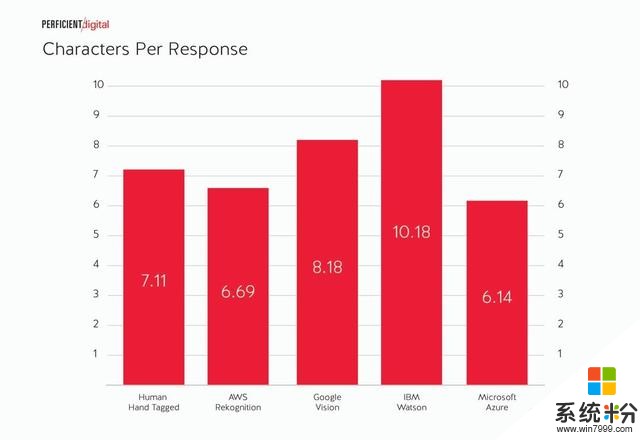
如上所見,你可能已經注意到了,我們將數據分成了一個個單詞,但不少數據標簽長度都不止一個單詞,而且標簽的平均長度會隨著不同引擎發生一定程度的變化,下圖所示為每個標簽下的平均單詞數量。
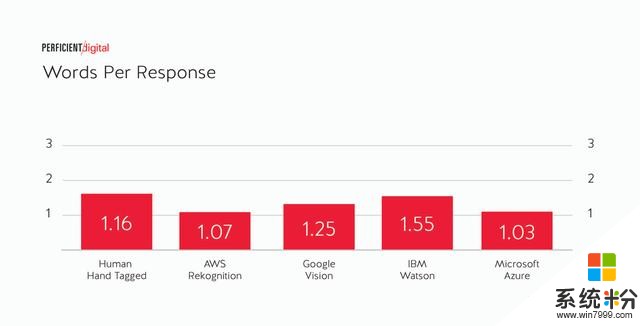
最後,是對於每個圖像識別引擎每次反應的平均字數。
每種引擎下的等級水平
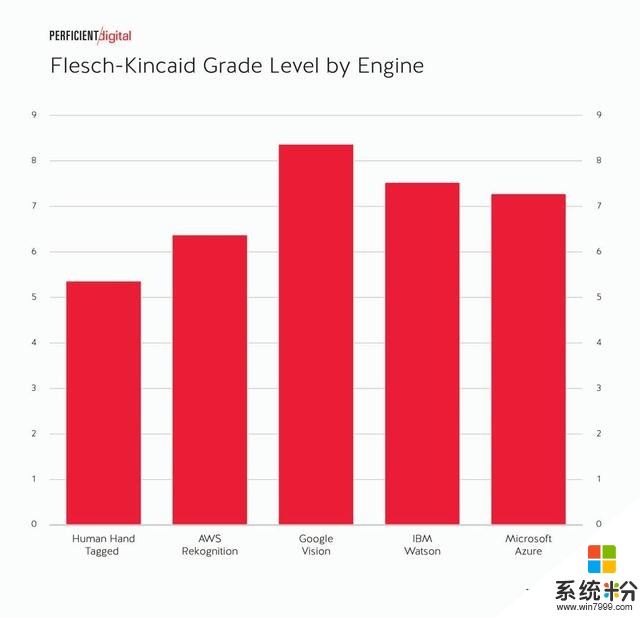
總體看來,所有的引擎距離人類描述圖像的方式還有很大的距離。
其他特征:IBM Watson是“藝術家”,AWS是“時尚達人”
IBM Watson最愛五顏六色:其API具有最獨特的顏色變化組合和最多的顏色種類。
Google Vision和微軟Azure Computer Vision也經常提到“黃色”,但都比不上IBM Watson的“藝術家”氣息。
Microsoft Azure Computer Vision可以描述圖像質量:引擎會返回“模糊”以及“像素級”的結果。
進行時詞彙:IBM Watson有112個回複以進行時“ing”結束,Amazon AWS Rekognition這樣的回複結尾有62個,Microsoft Azure Computer Vision有87個,Google Vision有103個。
IBM Watson喜歡高度描述性的詞語, 並為這些詞彙添加語境:pinetum(鬆樹),牛軛(河),LED顯示屏(計算機/電視),rediffusion(分布),'蔓藤花紋(裝飾),'dado(骰子),'登山杖(攀登裝備)。
實際上,IBM Watson在很多方麵都過於極端地描述了圖像。這可能導致IBM Watson麵臨的一些準確性上的問題。從積極方麵來說,這種對高度描述性詞語的關注應該使用戶更容易找到與其查詢請求相關的圖像。
AWS Rekognition是一個“時尚達人”:亞馬遜AWS Rekognition喜歡服裝。它比其他API更能識別出短褲、褲子和襯衫。
Google喜歡貓,IBM Watson喜歡狗:穀歌更善於識別出貓的品種,IBM Watson更善於識別出狗的品種,並對它們有更具體的了解,甚至可以具體到“德國短毛指針犬”。Microsoft Azure在貓的識別上僅次於Google Vision,位居第二。
總結很明顯,Google Vision是這場比拚中的贏家,在原始精度和與人類描述圖像的一致性上處於領先。
IBM Watson在測試中排名最後,但應該注意到IBM Watson在自然語言處理方麵表現優異,而NLP這不是本研究的重點。它是迄今為止唯一一家為自定義NLP模型創建構建完整GUI的主要AI供應商,Watson平台不僅允許分類,還允許通過該GUI提取自定義實體。
同樣令人興奮的是,當置信度大於90%時,四個引擎中的三個引擎的原始精度得分要高於人類手動標記。 這是圖像識別引擎性能和發展潛力的強有力的證明。不過,從圖像識別引擎以類似人類的方式描述圖像,並以此進行圖像標記的表現來看,未來還有很長的路要走。
原文鏈接:
https://www.perficientdigital.com/insights/our-research/image-recognition-accuracy-study
相關資訊
最新熱門應用

比特幣交易網
其它軟件179MB
下載
雷盾交易所app最新版
其它軟件28.18M
下載
火比特交易平台安卓版官網
其它軟件223.89MB
下載
中安交易所官網
其它軟件58.84MB
下載
中幣交易所appios
其它軟件77.35MB
下載
獨角獸幣交易所手機版
其它軟件223.86MB
下載
9coin交易所官網版
其它軟件28.80MB
下載
中幣交易所蘋果app
其它軟件288.1 MB
下載
avive交易所官網
其它軟件292.97MB
下載
zt交易所iosapp
其它軟件219.97MB
下載