

整理:白柯、黃菀
校對:李君
[導讀]本文整理自微軟亞洲研究院“城市計算”領域負責人鄭宇博士近期在清華大數據講座上的分享內容。鄭宇主持研發的Urban Air首次利用大數據來監測和預報細粒度空氣質量,該服務覆蓋了中國的300多個城市,並被中國環境保護部采用。2016年,他主持了城市大數據平台的設計和實施,並成功在中國大數據示範基地貴陽市部署。2013年他被《MIT科技評論評》評為全球傑出青年創新者,並作為現代創新者代表登上了《時代》周刊,2016年被評為美國計算機學會傑出科學家(ACM Distinguished Scientist)。
本文將演講內容配合PPT發布如下
演講正文:
今天與大家分享我們在城市計算領域的進展,並圍繞城市中人工智能如何發揮作用、大數據如何解決難題展開討論。
現代化的生活帶來了交通擁堵、環境惡化、能耗增加等問題。要解決這些問題,以前因為城市的複雜設置而幾乎不可能。現在由於各種傳感器技術的成熟以及雲計算單位的成熟,我們有了社交媒體、交通流量、氣象、地理等多種大數據。通過組合這些數據,我們就能發現問題,並進一步解決。基於這樣的機遇,我們在2008年提出了城市計算的願景。它包括以下四個層麵:
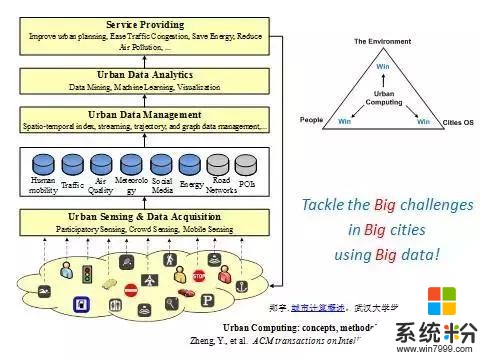
從最下麵的城市數據的感知和獲取到城市數據的管理,到城市數據的分析和挖掘再到服務和提供。這四個層麵連成一個環路,不斷地、自動地在不幹擾人生活的情況下,用大數據解決城市的大挑戰。今天,我帶著大家把每個層麵簡單梳理一下。
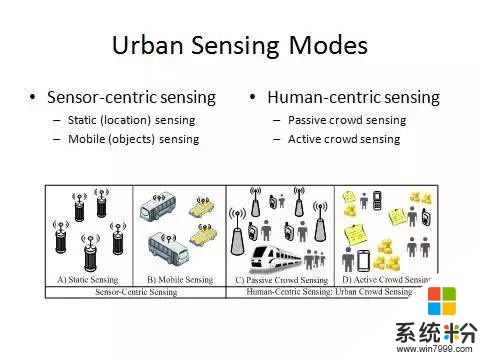
首先,城市數據的感知基本上可以分為兩大方法:一類以人為中心的感知,一類是以傳感器為中心的感知。以傳感器為中心的感知可以進一步細分為固定感知和移動感知。不管哪一種方法,部署傳感器以後,人都不參與數據的收集,數據會自動傳到後台。而以人為中心的感知則是每個人作為一個傳感器去感知他周邊的信息,然後彙聚在一起,來整體解決一些問題。
這裏麵分成被動方法和主動方法。被動是指我們在不知情的情況下被收集的數據。比如打電話的記錄可以用來改善蜂窩網的通信質量,上下車的刷卡記錄可以改進城市規劃。主動式參與感知是指我們清楚什麼樣的數據,在何時、何地、以何目的而貢獻的。我們可以有選擇的參加或退出,有時還有激勵機製。
在城市感知環節我們還會遇到來自四個方麵的挑戰。
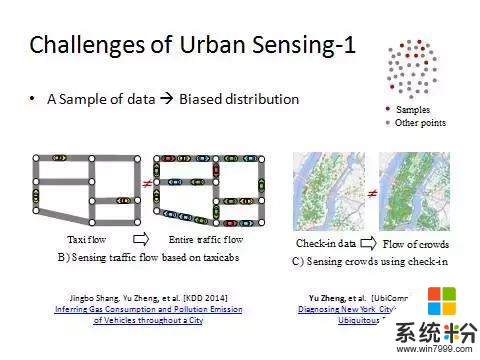
第一,我們拿到的數據往往隻是一個采樣。某些屬性在這個采樣上的分布跟它在整體數據上的分布有很大差異。比如我們可以拿到一些出租車的GPS軌跡,但不能估計出整個城市裏麵所有的車流量。不能因為采樣裏的出租車跟私家車的比例是一比五,就用出租車乘以五得出城市裏私家車數量,因為在某些路段上有很多出租車卻沒有什麼私家車,反過來同理。我們的采樣很多時候存在偏差,怎樣在有偏差的數據裏麵把真實的信息反應出來,這是一個難點。

第二,我們往往隻有有限的傳感器采集有限的數據。比如在北京我們隻有35個空氣質量檢測站點,無法根據這35個站點的數據把整個城市的信息估計出來,這就是稀疏數據的問題。

第三,我們有數據缺失的問題。通信故障或者傳感器故障都會導致數據缺失。
第四,我們需要用有限的資源獲取更多的數據。這個問題的難點第一在於很難從眾多候選集中選出我們需要的數據。舉個例子,假設我們要在北京布幾個充電樁,在哪些路口布充電樁可以使服務的人數最大化?第二在於好或不好很難判定。比如說現在北京要布四個新的空氣質量檢測站點。布這個站點之前你並不知道這個地方空氣質量如何,所以你無法判斷對整個城市空氣質量檢測效果是好還是壞。這四個方麵構成了城市計算在感知層麵的挑戰。
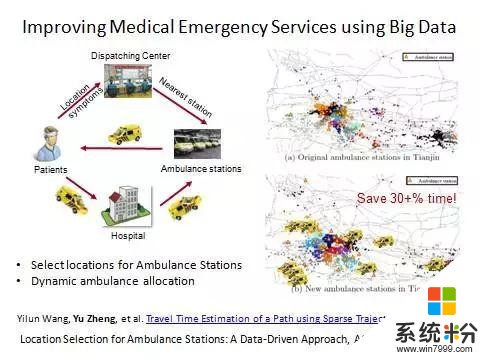
下麵看一下我們用大數據和人工智能的方法優化的救護車搶救係統。我們聯絡急救中心,急救中心派出救護車,將病人送到醫院,再返回救護車站。因為醫療救護係統跟醫院不是一個體係,也因為我們要求任何一個用戶的急救電話都能在規定時間內響應,所以救護車站點要分布在不同地方,也不能都在醫院裏麵。
上麵這個是天津市以前的救護車站布局圖,每個三角形表示一個救護車站點。以前選站點基本就是根據一些人口數量或者道路房屋密度決定的。但是人的急救需求的影響因素是複雜的。現在我們可以根據真實的120求救信號數據和救護車搶救病人的GPS軌跡等數據對站點進行重新布局來優化平均搶救時間,就可以救更多的病人。另外車輛如何在各個站點之間動態調度,使得係統運力最大化是我們第二步解決的問題。就是要找到一個使得很多人到此的彙聚時間最優化的點。不僅選址救護車站是這個問題,所有以速度優先級最高的應用都可以考慮這個選址模型。
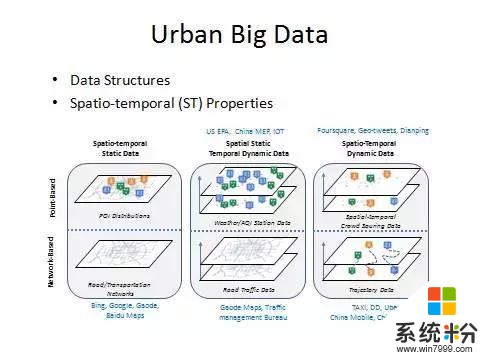
看完城市感知以後我們看一下城市數據管理。數據管理要注意三個因素。第一,我們是時空數據而非一般的文本。第二,我們要用增強型的雲平台管理。第三,我們要設計合理的索引算法和查詢算法。城市中所有數據根據數據結構可分為兩種:點數據與網絡結構數據。另外根據每種數據關聯的時空屬性可以分成三類。因此共六種數據,我給大家一一解釋一下。
點數據中,一旦建成後任何屬性都不會變動的是空間和時間都靜態的點數據。位置不變,但是每個小時的讀數不斷變化的是空間不變但是時間屬性在不停變化的數據。在摩拜單車裏麵,不同時間有不同的人在不同地方發出請求,這就是一個時空多變的數據。網絡結構中,路網就是一個靜態的網絡結構。把路網疊加了交通流量信息以後就變成空間不變時間變化的數據。最複雜的是軌跡數據,時間和空間都在變,並且點和點之間有連續的關係。
定義好這六種數據結構模型以後,我們就可以針對特定的模型設計特定的算法,提高係統的利用率。
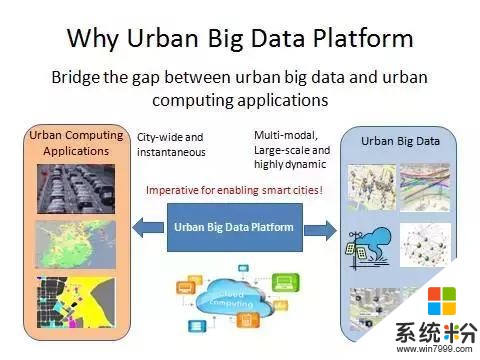
講完數據以後講平台。
一方麵,城市數據涉及到異構、多模、多源這三個領域。多源是說這個數據來自於不同領域。異構是指數據有的是結構化的有的是非結構化的。多模是說它有文本視頻和語音。另一方麵,我們是給整個城市提供服務,對整個城域做推斷、預測,這個運算量非常大,而且要求實時。所以數據和我們的應用之間有個GAP,就需要一個平台來橋接推這個GAP(間隙)。
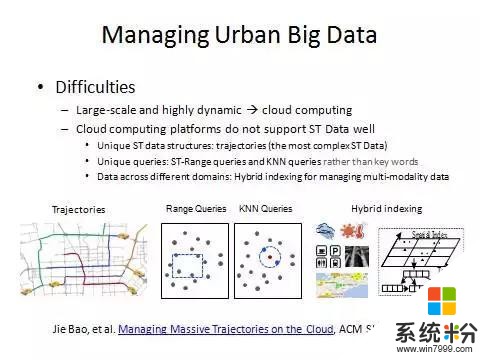
很遺憾現在任何一家公司的雲計算平台都不能很好地支持我們的時空大數據。一是因為時空數據的結構與一般數據不一樣。比如一個軌跡在車開的過程中長度不停增加,而兩個點的順序是不能任意交換的。
二是我們查詢時空數據的方式也不一樣。在文本查詢中會根據給出的關鍵詞進行檢索。但是在時空數據查詢裏麵,通常是查詢一個空間範圍加時間範圍,這種查詢方法在我們的雲計算平台裏麵都不能很好地直接支持。
三是我們真正做城市計算的時候絕對不是隻用一種數據。需要把多種數據做融合。這就提出了做混合式索引的需求來支持上麵的分析和挖掘。
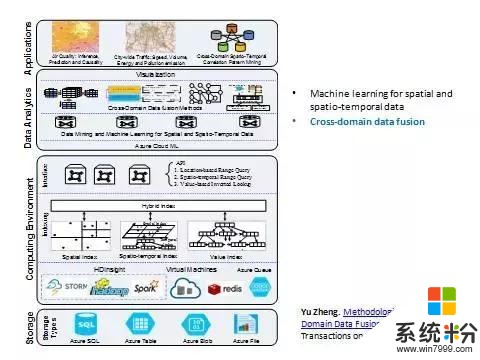
講完這個以後,大家可以理解為什麼智慧城市、雲計算很難落地。其實雲計算平台並不是我們說的城市大數據平台,它不能很好地支持這些因素。基於這樣的挑戰,我們在貴陽市設計和落地了第一個真正的城市大數據平台。它首先定義了六種數據模型,然後利用了已有的微軟的雲計算平台的存儲資源。接著我們做了一層中間件,針對不同的數據結構設計了時空索引算法,並針對不同數據設計了混合式索引算法。然後把時空索引集成到hadoop、Spark和Storm等分布式計算環境中。
這裏麵不光有分布式計算環境,也有時空索引算法,兩者的結合把數據的訪問和管理存儲變得非常高效。最後向上層的機器學習和人工智能算法提供API,使得我們的機器學習算法能夠快速訪問下麵的一些數據。想象一下,如果沒有這一層的話很多機器學習算法根本不能上線,根本不能做大規模的訪問和應用。
給大家講一個真實的例子。
在貴陽市我們根據大規模的出租車GPS軌跡來為充電樁做選址設計。假設我們希望在某個範圍之內建五個充電樁,我們應該放在哪五個路口使得覆蓋的不重複的出租車的GPS軌跡數量最大化。以前這樣一個複雜度非常高的計算量需要花5個小時到一天左右。現在很快可以算出來。追求高效是因為我們知道真正做充電樁選址的時候絕對不是覆蓋的人群最大化就可以了,還要看這個地方是不是別的條件都滿足。如果這個地方不合理的話,便由專家將其刪掉,或者進行補充。然後我們的算法回去再算,就變成了一個迭代式的交互挖掘。
現在機器學習已經變成了人機學習,通過這樣的途徑可以把專家的知識、行業知識跟數據科學結合在一起。而要交互的話就不能太慢,不然沒有人願意跟這樣的係統進行交互。通過剛才講的那種把分布式計算環境跟索引方法結合在一起的平台,可以使算法完成時間從幾個小時變成幾秒鍾,這就是平台強大的力量。
這也是一個通用的選址模型。比如你們在城市裏麵經常看到很多大廣告牌立在馬路旁邊,它們應該放在什麼位置使得覆蓋的群體最大化、廣告效益最好,是同樣的問題。銀行選址,銀行的自動取款機也是這一類的問題。這些問題都涉及到行業知識和數據科學的交互,涉及到人工智能裏麵Maximum k-coverage的問題,也需要通過交互可視分析的方法來完成。
講完了數據管理層麵,我們看一下數據分析和挖掘,這也是今天的重點。我們在城市數據分析層麵會遇到四個方麵的挑戰。
第一個方麵,我們以前很多做機器學習的人,他們提出算法的時候往往都是在video、graphic、text中,現在要把這些算法adapt到時空數據上來。如何將它轉換過來是一個難點。
第二個方麵,在於多元數據的融合。以前做數據挖掘的時候,往往隻是挖掘單一數據。現在我們發現做一個應用需要把多個數據的知識融合在一起。這是一個新的難點,我認為也是大數據裏麵,相對來說比那個“大”更加有意思更加難的問題。
第三個方麵,我們以前做database和machine learning的人是兩撥人,相互之間的交集比較少。但是隻有將data base以及machine learning的方法有機地融合在一起,做得又快又好才能把係統落地。第四個難點,以前做挖掘的時候往往是一個單向過程,就是簡單靜態挖掘。現在變成了交互可視挖掘,英文叫做interactive visual data analytics,就是交互可視分析。剛才所講就是一個例子,把人帶進去交互可視,人機交互,把人的智能也融合進去。
上麵是邏輯的框架,再回到實際平台。
我們定義了平台的下半部分,中間是一個分布式係統加上我們的時空索引方法,再往上還有中間數據分析的層麵。這裏麵分成三個子層麵。第一個是大家熟知的最簡單的一些機器學習算法,包括線性回歸這些最普通的方法。再往上我們構造了一些專門針對時空數據的機器學習算法。再往上我們還設計了時空數據融合的方法,尤其是後麵會重點講到的多元數據融合方法。
多元數據融合的方法按照已有的工作可以分成三大類。第一類是階段性的方法,先用一種數據再用一種數據。第二個是基於特征拚接的方法。我們所熟知的深度學習方法,還有傳統的特征串聯加上一些正則化方法,都是屬於這裏麵的分支。相對於第二個方法來說,第三類是基於語義信息融合的方法。這裏麵包括了多視角、基於概率學模型的方法、基於相似度的方法、以及遷移學習的方法。在這一方法裏麵我們要搞清楚每一緯特征是什麼含義,以及特征和特征之間的關聯關係、它們的語義信息。在做特征融合的時候則不必。另外這方法是根據人的思維方式設計的類人思考的方法。所以說是基於語義信息的方法。
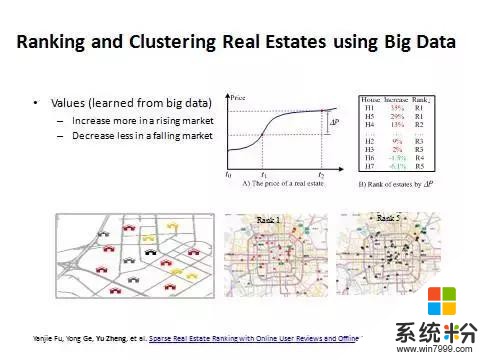
先講一個房價的例子來說明這種方法。
這裏麵我不去預測房屋的價格,而去預測高價值的房子,也就是漲的時候漲得更快,跌得時候跌得更少。同樣一個環境裏麵我們摒棄自然因素和政策因素,房屋的漲幅除以它的基數就是漲幅比,然後按照漲幅比排序。根據這個值做一個量化把北京的房子分成五等。
可以看到有時候一類房和五類房隔得很近。所以房屋的價值是由什麼決定的?
李嘉誠說過,房屋的價值第一看地段,第二看地段,第三還看地段。
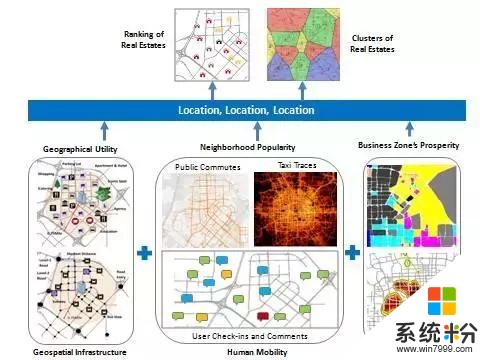
這個地段其實可以用數據量化。第一個地段就是周邊的各類設施水平,這個可以通過POI和路網數據得到。但同樣是學區,好學區和壞學區對房子價值拉動有明顯區別。
所以還要看第二個數據:popularity。這裏麵我們又參考了好幾個數據。比如社交媒體上對這個地方的點評,以及人們出行的規律等。人們的出行規律一般是不能說謊的,這往往反映了地域的價值。第三個地段,就是你所在的商圈。比如你在望京的話,對你的房子有拉動作用,但並不是望京所有的房子都好,還要看前麵兩個因素。所以第一個地段、第二個地段、第三個地段可以用六到七種數據量化。
我們可以從每一種數據裏麵都抽取特征,再進行計算。對於這些特征,以前的方法是簡單拚成一個向量然後做一些回歸。比如說最簡單的方法是做線性回歸,歐米伽是係數,X是向量,後麵是誤差。這種方法不是很有效,因為特征之間不是完全獨立的。
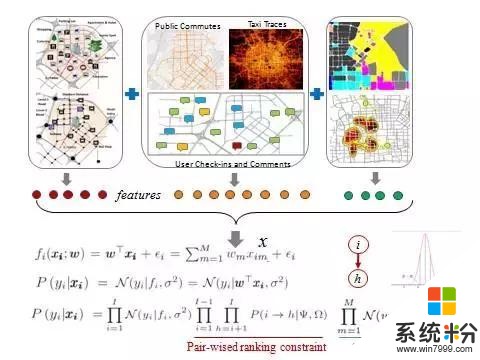
因此我們又加了兩個約束。
第一個約束是加上pair-wised constrain,把它變成一個Learing to rank的問題,即排序學習.我們不光希望每個房子單獨預測要準,還希望兩個房子之間的順序不要搞錯,這在機器學習裏麵叫排序學習。這邊簡單用兩個房屋的漲幅比做差,再通過一個Sigmoid函數變換到(0,1)之間的數值。如果A真的排在B前麵的話,那麼A本身應該漲得比B多,那麼它減出來的值是正的,函數的話是這樣值通過Sigmoid函數作用後,輸出值比較大,而且越大越接近於1,相當於對正確排序的一個加分。反之,如果A排在B的前麵,但B的單點預測值卻大於了A,那麼A-B的預測結果就是負值,通過Sigmoid函數變換後,就會產生一個小值,而且越小越趨近於零。相當於對錯誤排序的一個懲罰。
第二個約束,我們對歐米伽有約束,我們剛才說很多歐米伽可能是冗餘的,就是這個特征可能是不發揮作用的,我們希望這些冗餘的特征權重特別小,所以對歐米伽加上約束,是希望它的歐米伽分布符合均值為零且方差非常小的高斯分布,這樣大部分歐米伽在零的附近,我們也允許個別的歐米伽以比較小的概率取得比較大的權重。在這一計算中我們還發現一個有趣的現象,就是真正的高端房子有沒有地鐵不在乎,但是希望交通很便利開車上下班。這個東西怎麼驗證呢?我們用2013和2014年的數據做學習來訓練模型,然後我們預測2014年房屋漲幅排序,等到2014年結束以後我們就可以知道這個結果對不對。
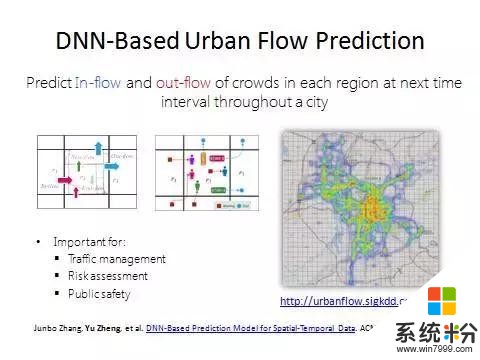
接下來介紹第二個方法,涉及到深度學習。
聽到深度學習的話題後以後很多媒體都來找我們,因為這個項目也是深度學習在時空數據上第一個真正在頂尖國際會議上發表的工作。我們把城市分成均勻的網格,可以預測每個格子所對應的區域中未來會有多少人進和出。可以想象這是一個非常通用的模型。它包括預測區域內出租車的進出;包括預測有多少人需求摩拜單車;包括預測未來有多少人在這個區域裏麵會點餐;包括預測到未來多少人要送快遞。這個模型做完以後可以滿足很多應用。最開始做這個工作是因為上海的踩踏事件。事後第一時間我發了微博,說這個安全問題可以由大數據和人工智能的方法做一些分析和預測,做到提前分流,甚至能做到在人們的起點就告訴他你不要去了。
我發了微博以後,網上的輿論分成兩派,一部分說很好這個確實是可以做的,也有一部分認為我都知道晚上肯定很多人會去了,根本不需要你預測。同樣政府肯定是知道有很多人去的,所以它會加派警力。但是政府不知道“多”的程度,也無法知道人群的數量達到峰值的具體時間。而要知道什麼時候是高峰點,每個單位時間進出是多少
才能做決策。所以這些是政府真正需要的。
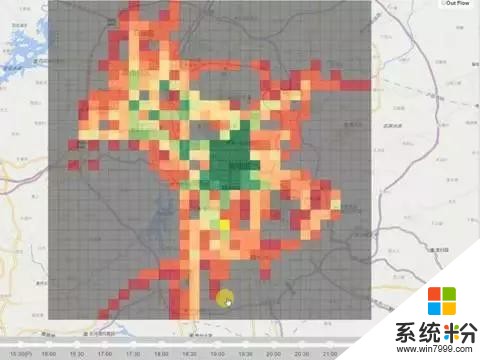
北京市地鐵站也有這個需求,它希望做到對人流的預知和把握。這個不僅關係到列車調度,也關係到人民的生命安全。這個模型在貴陽市已經實施了。貴陽市劃分成一公裏乘一公裏的格子,我們去預測每個格子裏麵未來會有多少出租車進和出。這裏麵綠色的是預測的,黑色的是過去的值,藍色的是昨天同一時刻對應的值。人流預測是非常困難的事情,因為這個區域過去一個小時多少人進出,周邊有多少人進出,還有很遠地方的人的進出都會影響到這個區域未來有多少人進出。這跨領域的研究是很缺失的。另外,天氣和事件也是影響因素。
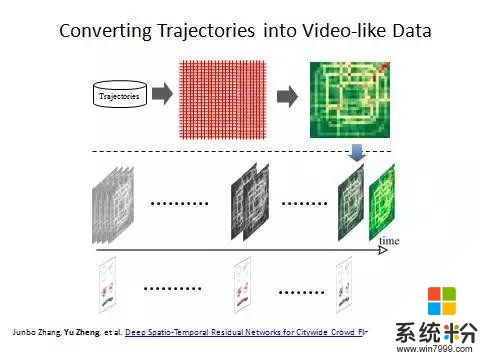
這裏強調一點,我們做的是時空數據,它跟視頻、圖象、語音是不同的。這也導致傳統的深度學習模型不能直接拿來用。首先,時空數據有空間屬性,包括兩方麵,一個叫空間的距離,一個叫空間的層次。所謂空間距離,根據地理學第一定律很容易理解。另外空間有層次。比如一個城市包括幾個區,幾個區包括幾個街道,每個層次都有特別的語義信息。不像象素裏麵,雖然有四個象素合並成一個象素,但在四個象素合並成一個象素的時候並沒有明確的語義信息。
第二個,時間屬性。有三個方麵的不一樣。第一,時間有平滑性,就是這個小時的交通量跟上個小時的比較接近。
第二,時空數據有周期性,交通流量、人群流量都會有周期。這種周期性在視頻、語音和文本裏麵都沒有。比如說今天早上八點鍾的交通流量可能跟昨天早上八點鍾的交通流量很像,但跟今天中午12點鍾的交通流量就很不像,隔得遠的反而像,這打破了第一點的約束,導致很多算法不能應用。
第三,趨勢性。周期絕對不是固定的。隨著天亮的時間越來越早,大家出門的時間也越來越早,因此早高峰來臨的時間越來越早。早高峰來得時間會有一個趨勢性的上揚的過程,這個趨勢、周期是很特別的,所以空間加時間這些因素導致了時空數據跟普通的文本、視頻不同。我們把城市分成均勻的網格,然後把過去和實時收到的車子GPS軌跡信息投影到網格裏麵,去計算每個格子裏麵多少人進出,將其轉化成一個矩陣,矩陣中每個單位是一個二元組,進和出,相當於每個象素有RGB一樣,它就變成了一個二維的熱力圖,越紅的地方人越多。如果我們有很多不同時間的數據就構成了這樣一個像視頻流的strain,並且加上事件和天氣信息。這是數據的輸入。
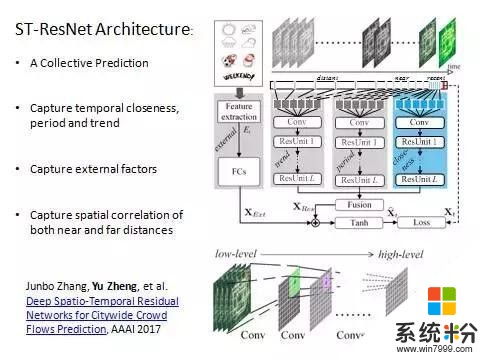
數據的應用,則是首先把相鄰幾個小時的數據放到一個深度卷積神經網絡裏麵,來模擬相鄰時間的時序的平滑性。然後把幾天內一時刻對應的數據輸入到一個相同結構的深度卷積神經網絡裏麵,來模擬周期性。再把更大時間範圍內同一時間點對應的數據做一個輸入,來模擬趨勢性。然後這三個數據先做一個融合,融合的時候引入權重係數,因為三個因素的輸出結果並不是在每個地方都一樣。比如有的地方周期性特別強,像這種主幹道。有的地方周期性不是那麼強,它的時間臨近性就比較重要。
其次需要考慮外部的因素,比如氣象事件。把這些數據融合以後,我們去反饋學習下一幀的數據,所以我們要預測下一幀這個時刻的狀況。它是一個整體預測,不是分開預測。因為格子和格子之間一定有相關性,我們是同時一下預測出來每個區域有多少人進出。另外是抓住了時空的屬性。時間臨近性、周期性、趨勢性都被抓住了,然後在內部通過深度卷積網絡抓取空間性。卷積網絡通過一次卷積可以把一個區域的值卷積到一個點上麵,描述近距離的空間的局部相關性。經過多次卷積以後可以把越來越遠的地方卷積到一起,描述距離較遠的空間的相關性。當深度卷積網絡比較深的時候它的訓練效果就變得很差。
為了解決這一問題,我們引入深度殘差神經網絡,整個架構稱為時空殘差網絡。這個比較新的模型相對於以前LSTM的模型,不需要進行連續的數據輸入,隻需要抽取關鍵幀。這樣的結構大大優化了網絡結構,隻需要用幾十幀就達到原先的模型裏幾百幀、幾千幀的效果,甚至更好。這種深度時空殘差網絡,在人口流動的預測上有很大的應用前景。

下麵看一下空氣問題。現在環境問題非常嚴重,這與每個人都相關。政府建了很多的空氣質量監測站點在城市裏麵。然而因為成本問題,子站不能無限量放置。並且城市大範圍內空氣質量非常不均勻。

這是一個真實數據的回放,每一個圖標表示一個真實的站點。上麵的數字是AQI汙染指數,可以看到同一時刻不同地方的空氣質量讀數差別非常大,有時候隻差一兩個街區讀數可以差幾百。因為空氣汙染指數是由很多複雜因素決定的,包括地麵交通流量、周邊是不是有廠礦、周邊的擴散條件等。這些因素在城市裏麵都是非線性、非均勻變化的,所以整個城市的空氣質量不可能是均勻的。也就是說,如果這個地方沒有建空氣站點,測出汙染指數,因為汙染指數不可能通過周邊幾個站點做一個線性差,它是非線性的,所以差別會變得很大。
所以我們用大數據的方法來做實時細粒度空氣質量分析。實時是每個小時做一次,細粒度是一公裏乘一公裏範圍這麼細的狀況。用了兩部分大數據,一部分是已有站點的實時和曆史空氣質量讀數,另外一部分分為五個數據源,包括氣象比如風速、風向、濕度,以及車的平均速度、速度方差,人的移動性,單位時間多少人進出,區域的POI的數目,有多少酒吧、多少餐飲、多少廠礦以及房屋的密度,以及道路結構有多少高速路多少紅綠燈路口等。然後采用機器學習算法來建立一個地方空氣質量跟這個地方周邊對應的這些數據的關係。
在模型建好以後便以這個模型推斷其他地方的空氣質量。即便這個地方沒有建站點,因為這些數據在城市裏已經全部有了,不需要額外建任何傳感器。
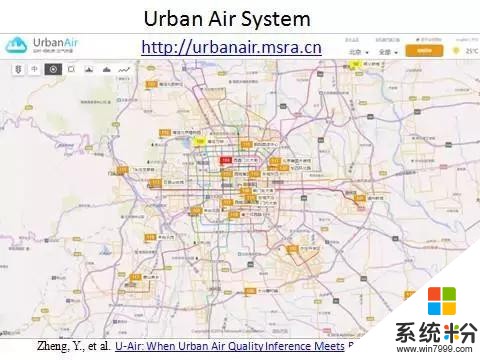

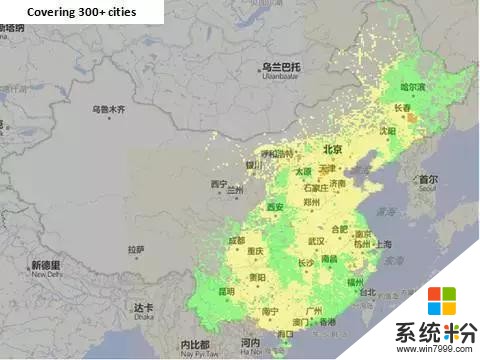
這是一個真實的係統,現在已經部署在環保部內部係統供300多個城市使用。我們可以看到把京津冀、長三角、珠三角、東北、華東分成片區大範圍地、細粒度的推斷。之所以要做大範圍,因為有時候光看北京是看不出問題來的。這種情況需要知道每次空氣質量從好到壞的過程中區域的先後順序,所以國家要求做到細粒度,甚至希望結果做得更細到500米。通過這個例子可以看出,大數據落地要跟行業結合。
這裏麵每個白圈是政府已有的站點,該區域的空氣質量是已知的,藍色圈是要預測的地方的空氣質量是多少,是未知的。平行四邊形表示時間點。首先一個地方的空氣質量有時序相關性,用縱向的箭頭表示,也就是說如果這個小時空氣質量不好會影響到下個小時空氣質量。第二,不同地方的空氣質量有空間相關性,用紅色箭頭表示,因為汙染物會傳播飄散。一個好的空氣質量模型一定能夠同時對一個地方的空氣質量的時序相關性以及不同地方的空氣質量的空間相關性進行建模。
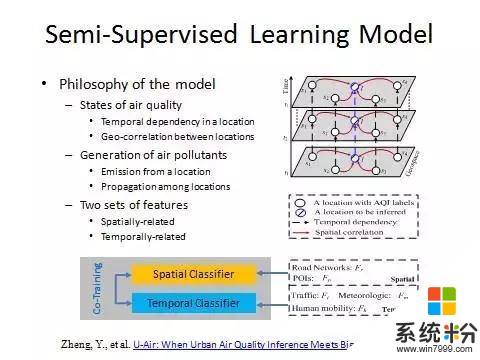
這裏有一個空間分類器和時間分類器。空間分類器可以通過周邊的值來計算中心值,而時序預測則根據它自己的讀數預測它未來的數值。因為汙染物的來源有三:一是外部進入,二是本地排放,三是外部進入的汙染物和本地排放在一定的環境因素下麵發生了二次化學汙染。這三個因素相當於上麵提到的空間相關性、時序相關性以及它們兩個時空分類器的一個迭代學習的過程。
從汙染物成因的角度講,因為有空間傳播和本地排放,所以既要有行業知識也要有數據科學知識,完美結合以後才能定製一個模型讓兩方麵的人都認可。汙染物有物理傳播過程也有化學過程,原來的方法單一的物理過程或者單一的化學過程都不能解決問題。現在通過數據分析的方法同時考慮到物理過程和化學過程以及它們之間的交互,所以能夠把這個問題解決得很好。這個工作在2013年發表論文以後,2015年在環保部落地。

2015年以後我們又做了新的預測未來的工作。按照環保部裏的要求是三步走,第一是搞清現狀,第二是預測未來。所謂預測未來是知道每個站點未來48小時在不同時間區間裏麵的預測。這是一個空間細粒度加時間細粒度的預測。不同於預測明天北京有霧霾或者沒有霧霾,這個很容易做。第一,霧霾是種天氣狀況,而不是一個空氣質量。隻是因為霧霾導致了空氣汙染物不利於擴散,所以才會出現空氣質量變差。當然空氣質量還取決於很多別的因素。所以我們做的空氣質量預測比霧霾預測要難。
第二個是粒度要細。不是說大範圍的整個北京明天大概多少,而是說到某一個站點怎麼樣。細到這個粒度在空間和時間上都非常難做。
另外,在空氣汙染物中有一個拐點,就是當出現極端天氣狀況的時候,空氣汙染指數可能會從500瞬間變成50。這個拐點是一個小樣本事件,因而預測非常困難。而拐點會直接影響到國家的決策。比如APEC期間為保證空氣質量,要以北京為圓心關閉一個圈裏麵所有的工廠,造成的損失可能上百億。若知道明天是拐點,就可以避免損失。我們要做的一是能夠做空氣質量預測,第二能夠做時空細粒度的預測,第三能夠做拐點的預測。現在全國300多個城市都已經用上我們的工作成果,跟環保部的二期已經簽完,現在已經部署。

最後一個工作,跟我們的交通、環境、規劃、人員都有關係。是對整個城市裏麵每條路上的速度、流量、油耗以及尾氣排放進行實時計算。排放包括PM2.6、PM10、二氧化氮、二氧化硫,一部分GPS軌跡做輸入,這邊用的是貴陽市的出租車做輸入,再加上POI路網還有天氣,所以還是一個多元數據融合的問題。
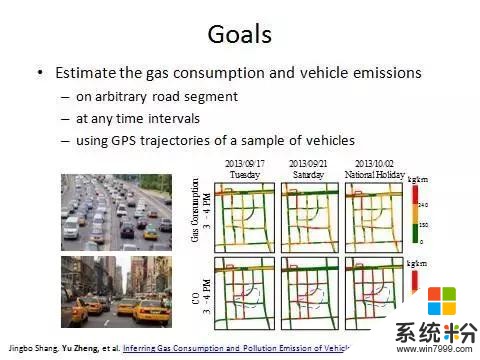

下麵展示一個真實的係統(見上圖)。這個是在貴陽市落地的真實的全國交通流量圖。關於流量可以通過一個問題去理解:交通流量比較大的時候速度是快還是慢?如果一個地方都堵死了,單位時間內每輛車都過不去,那流量是趨近與零的。流量大一定是速度快密度也不小的時候才能形成交通流量大。交通管控以及算油耗、算排放等很多事情都是基於流量來做的,規劃也是基於流量做的。所以貴陽市落地了中國第一個交通流量圖。
根據流量圖後麵可以算實時,每個路段上麵車的PM2.5排放量是多少。有了這個數據以後再把車的排量量跟空氣質量監測站點的讀數結合在一起就可以更加準確地分析出車的尾氣排放到底在空氣中PM2.5的占比是多少。這個係統在貴陽商用化了。所以說大數據是能夠做到既推動社會的進步,學術價值也能夠被認可,最後還能獲得收入,是三贏的。
最後跟大家分享一個觀念。什麼是數據科學家?很多公司招聘數據科學家其實都不是招真正的數據科學家,而是數據分析師。數據分析師是什麼概念?他有明確的任務,數據明確、任務明確、結果也明確,他會用一些工具去跑一些報表,然後提交結果。
數據科學家完全不一樣。一個很簡單的例子,銀行發信用卡,我們有用戶提交的表格,上麵有各種信息,我們拿個人的信用記錄去訓練一個模型然後做分配器,決定是否發信用卡。這就是數據分析師。
最近北京市建副中心在通州,政府需要知道北京的政府搬到通州以後對北京整個的經濟、環境、交通有什麼影響。沒有具體問題也沒有具體數據,這就是數據科學家應該解決的問題。而這還是比較好的情況,多半的時候我們跟政府談政府不知道要幹什麼,所以數據科學家要自己找題目。所以最高境界的數據科學家甚至要自己想好。先做出模型,政府覺得好就會實施。
所以,數據科學家首先要懂得行業問題,比如說他要知道霧霾跟什麼因素相關,從別人的方法裏麵怎麼吸取經驗來定義模式設計特征,也從別人的方法中吸取教訓,還要知道怎麼去跟行業的人溝通。要知己知彼百戰不殆。
第二,在你知道這個行業問題之後,你要知道用什麼數據解決這個問題,要懂得數據背後的隱含信息。比如說路麵上出租車的GPS軌跡不光反映了路麵的交通流量信息和速度,它也反映了人們的出行規律,人們的出行規律進一步反映了這個地方的經濟環境和社會功能。隻有經過這樣的關聯和聯想才能把領域A的數據拿來解決領域B的問題。你會發現在大數據時代我們真的不再缺數據了,缺的是我們的思維不夠開放。隻有你的思維夠開放、對這個問題理解夠深刻以後才能把別的數據背後的知識拿過來做融合,這個很關鍵。
第三,你要對各種模型都很清楚,要懂得把它們組合在一起。還要對雲計算平台有一定的了解。好的數據科學家是站在雲平台上麵看問題、想數據、關聯模型,把這些模型有機組合起來部署到雲平台上麵,產生鮮活的知識,解決行業問題,這個才是大數據。
要做到這三點才是大數據科學家。很多時候項目推動不了不是人數不夠,而是因為缺乏中間靈魂的頭腦。培養這樣的人其實是非常困難的。以我個人的經驗至少七到十年才能培養出這樣一個可以解決很多問題的真正的數據科學家來。所以我鼓勵大家,你至少讀一個五年PHD加兩年的實戰經驗,基本上可以來做這樣的事情。
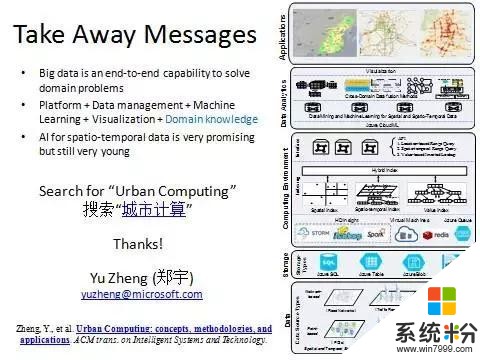
最後總結一下。今天我們在數據科學院還是要講講大數據。大數據在我看來是一種從數據的采集、管理、分析、挖掘到可視化這種端到端的服務,解決行業的一種能力。它需要平台的支撐,也需要各種算法,包括數據管理和挖掘分析算法、機器學習算法,還有行業知識,跟行業結合。最後我相信,人工智能在我們的城市領域在我們的時空大數據領域還大有作為,謝謝大家。
相關資訊
最新熱門應用

bicc交易所app蘋果
其它軟件45.94MB
下載
香港ceo交易所官網
其它軟件34.95 MB
下載
歐意錢包app
其它軟件397.1MB
下載
aibox交易所app
其它軟件112.74M
下載
btcc交易平台app
其它軟件26.13MB
下載
zb交易平台官網
其它軟件223.89MB
下載
芝麻交易平台官方安卓版
其它軟件223.89MB
下載
易歐交易所app官網安卓蘋果
其它軟件397.1MB
下載
滿幣交易所app
其它軟件21.91MB
下載
天秤幣交易所蘋果app
其它軟件88.66MB
下載