
前不久,Intel公布了網格互連(Mesh Interconnect)總線,提升多核CPU的效率和性能表現,取代QPI和環形總線。
相似的,AMD在今年的EPYC霄龍處理器上也使用了Infinity Fabric互連架構。

之所以要升級互聯(連)架構,其實就是向摩爾定律的再挑戰。如果僅僅是用“膠水”的方式拚接核心,帶來的是大量的帶寬和效率損失,而且芯片也會越來越大,甚至超越製程工藝本身進步。
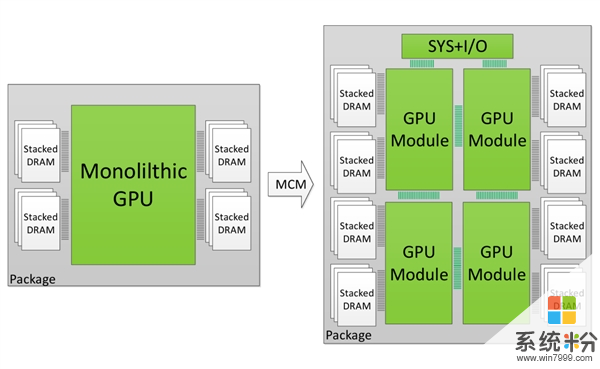
NVIDIA研究人員近日展示了自家的MCM(多芯片封裝)技術,用於將CPU/GPU/存儲器/控製器等整合,最直觀的作用就是提高流處理器數、減少通訊層級和鏈路長度、縮小芯片麵積。
我們知道,今年基於Volta架構的Tesla V100是NV史上最大的核心,麵積達到815平方毫米,而且流處理器數隻有5376(84組SM)。換言之,盡管換用了更先進的工藝,但Volta芯片麵積比上一代的GP100核心(610平方毫米)還大。

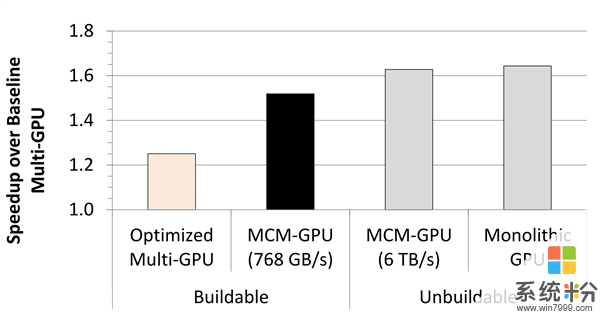
新的MCM技術允許多個GPU模塊與顯存、控製器等在更小的麵積內封裝,按照NV的紙麵模擬,一組256SM的新技術顯卡可以做到16384個流處理器,比用傳統手段搭建的28組SM多芯顯卡性能提升45.5%,比同樣流處理器數的多卡提升26.8%。
按照NV的設計思路,每個GPM(GPU模塊)比目前的大核心都要小40%~60%之多,如果配合10nm/7nm工藝,可以在更小的體積中發揮更大的性能。
相關資訊
最新熱門應用

bicc數字交易所app
其它軟件32.92MB
下載
比特國際網交易平台
其它軟件298.7 MB
下載
熱幣交易所app官方最新版
其它軟件287.27 MB
下載
歐昜交易所
其它軟件397.1MB
下載
vvbtc交易所最新app
其它軟件31.69MB
下載
星幣交易所app蘋果版
其它軟件95.74MB
下載
zg交易所安卓版app
其它軟件41.99MB
下載
比特幣交易app安卓手機
其它軟件179MB
下載
福音交易所蘋果app
其它軟件287.27 MB
下載
鏈易交易所官網版
其它軟件72.70MB
下載