
1 新智元報道報道:聞菲
[新智元導讀]業界公認人臉識別“世界杯”的微軟百萬名人識別競賽 MS-Celeb-1M 結果出爐:百萬名人識別子命題,Panasonic-新加坡國立大學合作奪得第一,CIGIT和中科院合作隊伍與美國東北大學位列第二第三。MS-Celeb-1M 數據集有效填補了工業界跟學術界的空白,通過有針對的評估指標設計,競賽實現了人臉“端到端”識別,有助於參賽模型投入現實應用。最後,競賽識別單一訓練樣本的名人子命題的冠軍團隊成員分享了他們的思路方法和參賽經驗。
2016 年 6 月,微軟向公眾發布了大規模現實世界麵部圖像數據集 MS-Celeb-1M,含有 10 萬個名人的約 1000 萬(10M)張臉部圖片,鼓勵研究人員開發先進的人臉識別技術。
同時宣布的還有 MS-Celeb-1M 百萬人臉識別挑戰賽。參賽者需要根據(但不限於)挑戰賽提供的數據集作為訓練數據,開發圖像識別係統,從臉部圖像中識別 100 萬個名人。
今天,競賽結果公布,其中:
百萬名人識別子命題,
無限製類(可以自由使用外部數據),Panasonic-NUS(新加坡國立大學)獲得第一名,中科院重慶綠色智能技術研究院(CIGIT)與中科院合作團隊第二,美國東北大學第三;
有限製類(隻使用競賽提供數據),第一名是 Beijing Orion Star Technology Co., Ltd.
識別單一訓練樣本的名人子命題,
無限製類(可以自由使用外部數據),第一名是 NUS-Panasonic
有限製類(隻使用競賽提供數據),第一名是美國東北大學
優勝團隊在技術上都采用了基於深度學習的方法,以及網絡大數據。從中可以看出,網絡大數據是發展趨勢,多模型融合是現在各個比賽得獎的利器。
微軟百萬名人識別競賽 MS-Celeb-1M:填補學術界與工業界的空白
人臉識別競賽有很多,微軟的百萬名人識別挑戰賽與已有的競賽有什麼不同?
據微軟技術與研究院(Microsoft Technology and Research)首席研究員/研究經理張磊博士介紹:首先,MS-Celeb-1M 的目標是識別百萬人臉,是計算機視覺內最大規模的分類問題,並且其中一個人物對應一個 entity,綁定了知識庫,並且知識庫中提供了每個人的職業,性別等等豐富的信息,從而解決了人物重名的問題,可以從識別達到認知。“最開始我們是麵向學術界做的這個數據集,”張磊告訴新智元:“但後來很多工業界的同行也表示我們的數據集對他們的研究工作很有幫助。”
深度學習算法的進步使視覺識別在過去幾年中取得了很大的進步。但是,學術上的創新和實際投入生活使用的智能服務間仍然存在巨大差距,主要因為:
(1)學術研究缺乏現實世界的大規模數據,從而阻礙了有效訓練和評估算法;
(2)缺乏公開透明的平台進行公正、高效的評估,使識別結果可複現,容易獲得。
目前,幾個主要的人臉識別數據集,公開獲取的(下圖綠色)有:
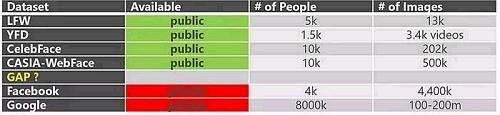
LFW 是美國馬薩諸塞大學的一個數據集,規模在萬這個級別(13k);
YFD 是耶魯人臉數據集,由耶魯大學計算視覺與控製中心創建,有不同的光照、表情和姿態的變化,但數量較少;
CelebFace 含有 20 多萬張圖片;
CASIA WebFace 是中科院自動化研究所的幾種數據集,裏麵包含掌紋、手寫體、人體動作等 6 種數據集;需要按照說明申請,免費使用。
接下來,Facebook 和穀歌的數據集規模雖大,但都無法公開獲取。
這些無不體現了存在於學術界和產業界之間的一道明顯的鴻溝。
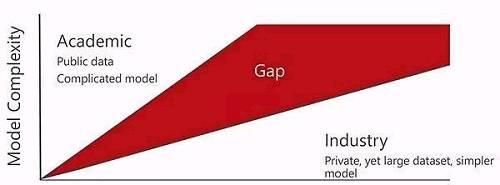

競賽指標設計:實現端到端識別,有助於現實應用
在競賽指標設置方麵,微軟的 MS-Celeb-1M 也針對現有競賽做了填補。
目前,數據能夠公開獲取的比較著名的人臉識別競賽有 LFW 和 MegaFace。LFW 的規模在萬這個級別,由於訓練數據不共享等原因,近年來已經呈現出容易過擬合的趨勢,而且微軟的研究人員發現,LFW 的最佳算法往往難以完全複現。此外,LFW 競賽是比對兩張圖像的相似度,距離實際應用還有一定距離。
MegaFace 是美國華盛頓大學發布的數據集,內容是幾十位互聯網明星照片加上普通人的一百萬左右的圖片的幹擾數據。但是,MegaFace 的目標設定有所不同,相比“識別”,更傾向於“在大噪聲情況下的人臉驗證”(face verification)。具體來說,MegaFace 競賽的目標則是在上百萬人中識別出特定的幾十人。幾十個人對人臉識別性能評估作用很難非常全麵,與實際應用尚有一些距離。此外,MegaFace 的測試數據沒有經過人為標注,含有噪聲。測試數據的噪聲在衡量高性能的模型時幹擾很嚴重。

“我們這個任務是端到端的任務,具體的說,任務是從圖像到知識庫中的名人識別碼。這樣的話,很自然而然引入了很多有價值的研究問題,比如如何有效從網絡有效獲取數據(我們允許自己增加訓練數據),如何利用好有噪音的標注訓練數據(規模巨大,超過人工標注的成本核算),如何處理海量數據(目標一百萬人,千萬級別的圖),當有些人的數據特別少,數據不均衡的時候怎麼辦等等,這些都是 CV 裏麵有意思的問題。”郭彥東說。
參賽隊伍的目標是識別出混百萬人中的 1000 個人,但具體是哪 1000 人參賽者並不知道。因此,為了實現盡可能高的召回率和準確度,參賽模型需要覆蓋盡可能多的人,乃至全部百萬規模。這就對模型提出了很高的要求。此外,微軟的研究團隊非常仔細地人工標注了測試集合,在測試集合上保證了非常高的準確度,這樣對衡量高性能模型以及模型在幾乎 100% 的準確率下的表現(recall@high precision)就非常有效。

在這裏,參賽隊伍需要從 2 萬 1000 人中識別 1000 人。但是,這 1000 人都每個人都隻有 1 張用於訓練的圖片。在很多情況下,比如公安人臉識別,犯罪嫌疑人隻有 1 張模糊的或有遮蓋的圖片,要將其在茫茫人海中找出來,就屬於小樣本學習。
這在一定程度上倡導了當今人工智能的另一個垂直方向:從有限樣本中學習視覺概念。
冠軍團隊技術分享:Low-shot Learning 環節
競賽結果公布後,新智元采訪了 Low-shot Learning 競賽冠軍新加坡國立大學與新加坡鬆下研究院合作團隊,成員趙健作為代表分享了他們的思路方法和參賽經驗。
冠軍隊伍:NUS-Panasonic,成員:趙健(NUS),程禹(Panasonic),王哲燦(NUS),徐炎(Panasonic),Karlekar Jayashree(Panasonic),Shen Shengmei(Panasonic),馮佳時(NUS)。
新智元:為什麼要參加微軟 MS-Celeb-1M 百萬名人識別競賽?
NUS-Panasonic:微軟百萬名人識別競賽是業界公認的人臉識別年度“世界杯”。本次競賽由微軟研究院主辦,借助計算機視覺領域頂級會議 ICCV 2017的平台,級別之高、難度之大備受矚目。全世界人臉識別的頂尖團隊都希望能夠在這次比賽中一展身手、顯露頭角。本屆競賽既包括了與上屆類似的大規模人臉識別競賽(Hard Set 及Random Set),同時也提出一個全新的、更具挑戰性的 Low-Shot Learning 競賽。主辦方希望參賽隊伍既能夠做到大規模人臉的精準識別,同時也能夠有效解決稀缺人臉訓練樣本的精準識別難題。
NUS LV 組由顏水成教授創建、由馮佳時教授領軍,是目前各大學術機構在深度學習與計算機視覺領域的頂級團隊之一。其人臉識別團隊一直是LV組中不可或缺的頂梁柱,屢創佳績——在 LFW 人臉識別數據集首次達到 99.7% 的識別精度、在 NIST 2017 IJB-A 人臉匹配與識別兩項競賽中與新加坡鬆下研究院合作一起奪得冠軍。我們選擇參加本屆(2017)微軟百萬名人識別競賽希望能夠在人臉識別的最高平台上證明自己,並助推大規模人臉識別技術的長足進步與發展。
新智元:從技術的角度講,參賽得到的最大啟發是什麼?
NUS-Panasonic:本次競賽得到的最大啟發是精準高效的人臉識別係統設計通常需要將一個複雜問題進行模塊化,從數據收集、清理、預處理,到模型設計、訓練、測試,再到不同模型的融合、度量學習、性能評估,每個模塊都不斷去嚐試一些新的想法和不同的策略,將每個模塊的效果調試到最優後,再進行係統級接合。
新智元:能介紹一下你們的思路、方法和獲勝的原因嗎?
NUS-Panasonic:Low-Shot Learning 重點考察參賽隊伍能否有效解決稀缺人臉訓練樣本的精準識別難題。Low-Shot Learning 比賽分別提供兩個數據集——Base Set 和 Novel Set。其中,Base Set共包含 20k 個名人,每個名人提供 50-100 張樣本數據;Novel Set 共包含 1k 個名人,每個名人僅提供 1 張樣本數據。在測試時,主辦方提供的測試集中會混合 Base Set 與 Novel Set 的名人數據,並重點考察算法在 Novel Set 稀缺人臉訓練樣本的表現。
為了解決這一難題,我們基於大規模人臉識別競賽提供的 100k 名人的訓練數據,移除掉其中包含的 Novel Set 中 1k 個名人的數據來構建一個“增強版”數據庫,訓練幾種不同結構的網絡模型,使得網絡學到的特征具有足夠的區分度、魯棒性以及泛化性能,不同的網絡模型學到的特征也具有互補效應。我們采用特征檢索的方法對每個模型進行測試,在測試時通過交叉驗證的方法確定了一些有效的策略。
相比於其他參賽隊伍的方法以及傳統 Low-Shot Learning 的解決辦法而言,我們的主要改進在於符合比賽規定的額外數據的使用與構建、多模型的度量學習、啟發式投票融合以及測試階段的數據增強。
比賽取得的好成績也依賴於新加坡鬆下研究院充足的硬件設備,比如大規模的 GPU 集群和最新的 DGX。新加坡鬆下研究院一支數據標注團隊也在這次比賽中發揮了很大作用。
新智元:比賽中遇到的最大困難是什麼?如何解決的呢?
NUS-Panasonic:百萬名人識別的難點如何高效利用已有數據高效訓練效果最優的模型。為了解決稀缺人臉訓練樣本的難題,我們基於大規模人臉識別競賽提供的 100k 名人的訓練數據,移除掉其中包含的 Novel Set 中 1k 個名人的數據,構建一個“增強版”數據庫,訓練幾種不同結構的網絡模型。訓練過程中,網絡最後一個全連接層(FC)的神經元數量與分類類別數量相等,大量級的訓練參數往往導致網絡很難直接訓練,損失函數波動震蕩不降。我們在這裏進行了一些調整,將整個訓練過程分為兩個階段,首先訓練網絡來區分 1/10 樣本類別,在網絡趨於收斂後,將最後一個 FC 層替換掉,並進行第二階段的訓練和調優,從而解決大樣本類別的網絡高效訓練難題。
新智元:你們提出的算法有什麼實際應用?
NUS-Panasonic:我們所提出的算法能夠有效解決稀缺人臉訓練樣本的精準識別難題,這對於安防係統、智能家居係統、無人駕駛以及人機交互等領域具有很高的應用價值和商業前景。我十分看好未來算法的落地,如可以結合人臉識別算法研究、網絡壓縮技術和FPGA相關技術進行係統級設計,為人們的生產生活提供更多便利。
雖然目前人臉識別的準確率已經很高,但大多主流技術和算法需要以預定姿態或條件為前提,如正臉或近似正臉,圖像清晰無遮擋,表情、背景單一等。未來的真正意義上的智能人臉識別將可以很好地解決上述問題,並在大規模、非限製條件以及稀缺訓練樣本的人臉識別問題中不斷取得新的突破。
新智元:祝賀你們取得好成績,最後分享一下獲勝感受吧。
NUS-Panasonic:通過 NUS LV 組與 Panasonic 的竭誠合作,曆經三個月的共同努力與奮鬥,我們終於成功拿下微軟名人人臉識別三項競賽(Hard Set, Random Set, Low-Shot Learning)的冠軍。很慶幸能夠成為冠軍團隊的一員,能夠取得這樣的成績,離不開 NUS 與 Panasonic 兩個單位的竭誠合作,離不開團隊每名成員的齊心協力、共同拚搏。感謝我的導師馮佳時教授、顏水成教授的培養、指導和信任,感謝中科院自動化所興軍亮老師的幫助與指導,感謝國防科技大學和中國留學基金委的資助,我會繼續努力,希望能夠在人臉識別領域再創佳績,助推相關技術發展和進步。
相關資訊
最新熱門應用

小猿口算app安卓最新版
辦公學習71.96MB
下載
樂速通app官方最新版
生活實用168.55MB
下載
墨趣書法app官網最新版
辦公學習52.6M
下載
光速寫作軟件安卓版
辦公學習59.73M
下載
中藥材網官網安卓最新版
醫療健康2.4M
下載
駕考寶典極速版安卓app
辦公學習189.48M
下載
貨拉拉搬家小哥app安卓版
生活實用146.38M
下載
烘焙幫app安卓最新版
生活實用22.0M
下載
喬安智聯攝像頭app安卓版
生活實用131.5M
下載
駕考寶典科目四app安卓版
辦公學習191.55M
下載