
選自MBML book
參與:蔣思源
PRML 大神、微軟劍橋研究院院長 Chris Bishop 與 John Winn 的機器學習新書 Model Based Machine Learning(基於模型的機器學習)不久之前剛剛公布。本書從實際案例出發,每一章節都著重從頭解決一個問題,本書從最基礎的概念開始,一步步帶領讀者體會機器學習建模解決問題的思路。本書現有 5 個章節,其他章節將陸續推出。
項目地址:http://mbmlbook.com/toc.html

近年來,機器學習已經走到了科技世界的中心位置。今天,成百上千的科學家和工程師們正在將機器學習的各類方法應用到越來越多的領域裏。然而,在實踐中有效利用機器學習是一項艱巨的任務,特別是對於新領域而言,以下是使用機器學習解決現實世界問題麵臨的一些主要挑戰:
「我正被機器學習方法和技術的海洋所淹沒,有太多的方法了!」
「我不知道該用哪個方法,不知道為什麼這個方法在我的問題中表現更好。」
「我的問題看起來不能用任何標準算法解決。」

機器學習對於入門者而言是令人畏懼的
在本書中,作者從一個新的視角審視機器學習,即基於模型的機器學習。從這個視角來看,我們會更係統、清晰地了解創建高效機器學習解決方案的過程。本教程適應於全方位了解機器學習技術和應用,並有助於大家構建成功的機器學習解決方案。
什麼是基於模型的機器學習?
在基於模型的視角中,我們不需要轉換我們的問題而去擬合一些標準算法,我們隻需要精確地設計我們自己的機器學習算法而擬合我們的問題。
在基於模型的機器學習中,核心觀點即所有問題域的假設都可以在特定形式的模型中表達。實際上,模型就是對問題作出一係列假設,並用十分精確的數學形式表達出來。例如在第一章中,我們嚐試構建一個模型而解決簡單的謀殺問題。在這個任務中,模型的假設就包括一組犯罪嫌疑人、可能行凶的武器、不同犯罪嫌疑人對不同武器的偏好等,然後我們再對這些不同的假設采用具體的機器學習算法完成模型。基於模型的機器學習是一種廣義目的方法,因此我們不需要學習巨量的機器學習算法和技術。
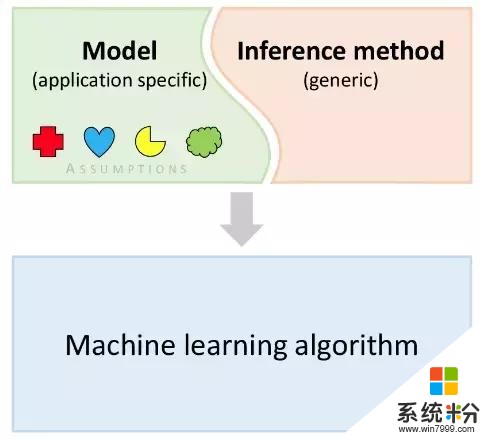
模型和算法
從基於模型的機器學習角度來看,模型是組合一係列假設以在問題域中尋找解決方案。為了從模型獲得一組預測,我們需要收集數據並計算那些我們希望知道的變量值。而這一計算的過程就稱之為推斷。我們將在本教程中討論幾種常見的推斷技術,而模型和推斷過程的結合如下所示就可以定義成一個機器學習算法。
目標讀者
本教程並不是尋常的機器學習教科書,因此我們也不會一一介紹不同的機器學習算法。我們會通過一係列現實案例介紹各種算法的關鍵概念。案例學習在本教程中起到了極其重要的作用,因為我們隻有通過案例才能真正理解不同的建模方法和算法。因此每一章主要隻討論一個案例,並且將嚐試使用基於模型的方法解決該案例所出現的問題。因此本教程非常適合機器學習入門者快速了解機器學習的核心思想和方法。
本教程每一個章節(或一個案例)將分為多個小節,因此初學者可以在閱讀完每小節後消化該小節的內容再進入下一小節的內容。
當前章節內容

第一章:破密神秘謀殺任務
在破解謀殺秘密中,我們將使用各種常見的概率方法跟著作者一步步找出隱藏在幕後的凶手,本章節涉及到概率的意義、隨機變量和概率分布等核心概念。
概率:即衡量隨機事件不確定性程度的數值,其取值範圍從 0 到 1。其中 0 代表不可能發生,1 代表必定發生。
隨機變量:即數值存在不確定性的變量。
標準化約束:即對概率分布的限製,一個隨機變量在所有情況下出現的概率和為 1.
概率分布:即一個函數,該函數給定了隨機變量每一個可能的值和概率。
抽樣:抽樣是一種推論統計方法,它是指從目標總體中抽取一部分個體作為樣本,通過觀察樣本的某一或某些屬性,依據所獲得的數據對總體的數量特征得出具有一定可靠性的估計判斷,從而達到對總體的認識。
伯努利分布:伯努利分布又名兩點分布或者 0-1 分布,是一個離散型概率分布。若伯努利試驗成功,則伯努利隨機變量取值為 1。若伯努利試驗失敗,則伯努利隨機變量取值為 0。
均勻分布:均勻分布表示隨機變量等可能出現。在實際問題中,當我們無法區分在區間 [a,b] 內取值的隨機變量 X 取不同值的可能性有何不同時,我們就可以假定 X 服從 [a,b] 上的均勻分布。
第二章:評估人才技能
在這一章節中,我們將學會使用真實的數據構建模型。這一部分主要的概念如下:
概率密度函數:連續型隨機變量的概率密度函數是一個描述這個隨機變量的輸出值,在某個確定的取值點附近的可能性的函數。
β 分布:Β分布也稱貝塔分布,是指一組定義在 (0,1) 區間內的連續概率分布,有兩個參數α和β。
對數概率(似然函數):似然函數是一種關於統計模型中的參數的函數,表示模型參數中的似然性,似然函數在統計推斷中有重大作用。
真正類率(true positive rate):預測為正且實際為正的樣本占所有正樣本的比例。
假正類率(false positive rate):預測為正且實際為負的樣本占所有正樣本的比例。
後麵第三章、第四章和第六章已經完成,而剩下的章節還沒有更新。第三章主要是構建遊戲玩家匹配係統,即使用 Xbox Live 數據構建一個可以匹配遊戲玩家的係統,我們希望能使相匹配的玩家擁有相近的技能。第四章主要是構建郵件過濾係統,因為我們的郵件非常多,有些重要郵件會因為源源不斷的新郵件而被覆蓋掉,那麼該章節就叫我們怎樣利用機器學習方法減少這種信息負載。第六章則更深入到了醫學場景中,因為兒童哮喘病近來比較嚴重,而我們更好地理解哮喘和過敏間的關係有助於幫助醫生檢測和診斷哮喘病,那麼我們是不是可以利用機器學習解決該問題。
相關資訊
最新熱門應用

光速寫作軟件安卓版
辦公學習59.73M
下載
中藥材網官網安卓最新版
醫療健康2.4M
下載
駕考寶典極速版安卓app
辦公學習189.48M
下載
貨拉拉搬家小哥app安卓版
生活實用146.38M
下載
烘焙幫app安卓最新版
生活實用22.0M
下載
喬安智聯攝像頭app安卓版
生活實用131.5M
下載
駕考寶典科目四app安卓版
辦公學習191.55M
下載
九號出行
旅行交通133.3M
下載
全國潮汐表官方app最新
生活實用31.83M
下載
閃送一對一急送app安卓版
生活實用50.61M
下載