
陳樺 編譯整理
量子位 出品 | 公眾號 QbitAI
昨晚,外媒都在用誇張的標題報道IBM的人工智能又立功了,例如說IBM的速度快得很“抓馬”雲雲。到底怎麼回事,量子位把IBM Research的博客全文搬運如下,大家感受一下IBM這次的捷報……

深度學習是一種被廣泛使用的人工智能方法,幫助計算機按照人類的方式理解並提取圖像和聲音的含義。深度學習技術有望給各行各業帶來突破,無論是消費類移動應用,還是醫學影像診斷。然而,深度學習技術的準確性,以及大規模部署能力仍存在技術挑戰,模型的訓練時間往往需要幾天甚至幾周。
IBM研究院的團隊專注於為大型模型和大規模數據集縮短訓練時間。我們的目標是,將深度學習訓練的等待時間從幾天或幾小時縮短至幾分鍾或幾秒,同時優化這些人工智能模型的準確率。為了實現這一目標,我們正在將深度學習部署至大量服務器和英偉達GPU,解決“大挑戰”規模的問題。
最熱門的深度學習框架可以支持在單台服務器上的多個GPU,但無法支持多台服務器。我們的團隊(包括Minsik Cho、Uli Finkler、David Kung和他們的合作者)編寫了軟件和算法,對這種規模龐大、非常複雜的並行計算任務進行優化,實現自動化。這種並行計算任務分布在數十台服務器的數百個GPU加速處理器上。

我們的軟件可以完全同步地進行深度學習訓練,且通信開銷很低。因此,當我們將規模擴大至100s英偉達GPU集群時,對ImageNet-22k數據庫中750萬張圖片的識別準確率達到創紀錄的33.8%,高於此前的最高紀錄,即來自微軟的29.8%。
4%的準確率提升是巨大的飛躍,以往的優化通常隻能帶來不到1%的準確率提升。我們創新的分布式深度學習(DDL)方法不僅提高了準確率,還利用10s服務器的性能實現了在短短7小時時間裏訓練ResNet-101神經網絡模型。這些服務器配備100s的英偉達GPU。
此前,微軟花了10天時間去訓練同樣的模型。為了實現這一成績,我們開發了DDL代碼和算法,克服在擴展這些性能強大的深度學習框架時固有的問題。
這些結果采用的基準設計目標是為了測試深度學習算法和係統的極限,因此盡管33.8%的準確率聽起來可能不算很高,但相比於以往已有大幅提升。給予任何隨機圖像,這個受過訓練的人工智能模型可以在2.2萬種選擇中給出最高選擇對象(Top-1精度),準確率為33.8%。
我們的技術將幫助其他人工智能模型針對特定任務進行訓練,例如識別醫學影像中的癌細胞,提高精確度,並使訓練和再訓練的時間大幅縮短。
Facebook人工智能研究部門於2017年6月在一篇論文中介紹了,他們如何使用更小的數據集(ImageNet-1k)和更小的神經網絡(ResNet 50)來實現這一成果:“深度學習需要大型神經網絡和大規模數據庫才能快速發展。然而,更大的網絡和數據庫會造成更長的訓練時間,不利於研究和開發進度。”
諷刺的是,隨著GPU的速度越來越快,在多台服務器之間協調和優化深度學習問題變得越來越困難。這造成了深度學習的功能缺失,促使我們去開發新一類的DDL軟件,基於大規模神經網絡和大規模數據集運行熱門的開源代碼,例如Tensorflow、Caffe、Torch和Chainer,實現更高的性能和精確度。
在這裏,我們可以用“盲人摸象”來形容我們試圖解決的問題,以及所取得的初步成果的背景。根據維基百科上的解釋:“每個盲人去摸大象身體的不同部位,但每個人隻摸一部分,例如側麵或象牙。然後他們根據自己的部分經驗來描述大象。對於大象是什麼,他們的描述完全不同。”
盡管最初有分歧,但如果這些人有足夠多的時間,那麼就可以分享足夠多的信息,拚湊出非常準確的大象圖片。
類似地,如果你有大量GPU對某個深度學習訓練問題並行處理幾天或幾周時間,那麼可以很容易地同步這些學習結果。
隨著GPU的速度越來越快,它們的學習速度也在變快。它們需要以傳統軟件無法實現的速度將學到的知識分享給其他GPU。這給係統網絡帶來了壓力,並形成了棘手的技術問題。
基本而言,更智能、速度更快的學習者(GPU)需要更強大的通信方式,否則它們就無法同步,或是不得不花大量時間去等待彼此的結果。如果是這樣,那麼在使用更多、學習速度更快的GPU的情況下,你就無法加快係統速度,甚至有可能導致性能惡化。
我們利用DDL軟件解決了這種功能缺失。當你關注擴展效率,或是在增加GPU以接近完美係統性能時,優勢表現得最明顯。我們在實驗中試圖了解,256個GPU如何“對話”,以及彼此學習了什麼東西。
此前對256個GPU的最佳擴展來自Facebook人工智能研究部門(FAIR)。FAIR使用了較小的學習模型ResNet-50以及較小的數據庫ImageNet-1k,後者包含約130萬張圖片。這樣做減小了計算的複雜程度。基於8192的圖片批量規模,256個英偉達GPU加速集群,以及Caffe2深度學習軟件,FAIR實現了89%的擴展效率。
如果利用ResNet-50模型以及與Facebook同樣的數據集,IBM研究院的DDL軟件基於Caffe軟件能實現95%的效率,如下圖所示。這一結果利用了由64個Minsky Power S822LC係統組成的集群,每個係統中包含4個英偉達P100 GPU。
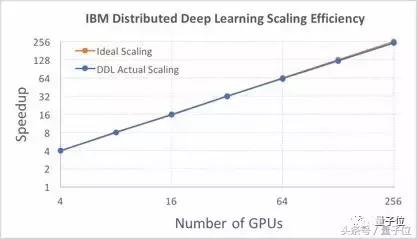
如果使用更大的ResNet-101模型,以及ImageNet-22k數據庫中的750萬張圖片,圖片批量規模選擇5120,那麼我們實現的擴展效率為88%。
此外,我們還實現了創紀錄的最快絕對訓練時間,即50分鍾,而Facebook此前的紀錄為1小時。我們用ImageNet-1k數據庫訓練ResNet-50模型,使用DDL將Torch擴展至256個GPU。Facebook使用Caffe2訓練類似的模型。
對開發者和數據科學家來說,IBM研究院的DDL軟件提供了一種API(應用程序接口),每個深度學習框架都可以掛接並擴展至多台服務器。技術預覽版已通過PowerAI企業深度學習軟件第4版發布,任何使用深度學習技術去訓練人工智能模型的企業都可以使用這種集群擴展功能。
我們預計,通過將這種DDL功能提供給人工智能社區,隨著其他人利用集群性能去進行人工智能模型訓練,我們將看到準確性更高的模型運行。
—— 完 ——
活動報名
8月9日(周三)晚,量子位邀請三角獸首席科學家王寶勳,分享基於對抗學習的生成式對話模型,歡迎報名 ▼
誠摯招聘
量子位正在招募編輯/記者,工作地點在北京中關村。期待有才氣、有熱情的同學加入我們!相關細節,請在量子位公眾號(QbitAI)對話界麵,回複“招聘”兩個字。量子位 QbitAI
վ'ᴗ' ի 追蹤AI技術和產品新動態
相關資訊
最新熱門應用

雲比特交易所app
其它軟件14.54 MB
下載
芝麻app交易平台官網安卓
其它軟件223.89MB
下載
薄餅交易所app地址中文版
其它軟件287.34 MB
下載
gate.io蘋果交易平台
其它軟件287.34 MB
下載
ambc交易所app
其它軟件34.95 MB
下載
hopoo交易平台
其它軟件18.98MB
下載
比特國際數字交易所app
其它軟件163.20M
下載
安幣交易所app最新版官方
其它軟件178.1M
下載
v8國際交易所app
其它軟件223.89MB
下載
中幣交易app蘋果版
其它軟件223.89MB
下載