
AI科技評論消息,2017年10月19日微軟亞洲研究院 聯合 哈爾濱工業大學共同在哈爾濱市舉辦了第19屆“21世紀的計算” 大型國際學術研討會(21CCC 2017)。
“二十一世紀的計算”學術研討會是微軟亞洲研究院自創立之初便開始舉辦的年度學術盛會,每年都吸引著無數計算機科學領域學者們的目光。作為中國及亞太地區規模最大、最具影響力的計算機科學教育與研究盛會之一,該大會已在中國、日本、韓國、新加坡等多個國家和地區成功舉辦了18屆。

本次大會的主題為“人工智能,未來之路”,並邀請了包括圖靈獎獲得者John Hopcroft在內的多位世界級計算機領域專家分享他們在AI領域的研究和觀點。現場有超過1500名高校師生參與。

下麵內容為記者根據幾位嘉賓的現場報告和微軟亞洲研究院資深研究員秦濤博士的解讀整理而成,附加有現場拍攝的PPT,以饗諸位。
Peter Lee:Artisanal AI(人工智能的手工性)
Peter Lee認為,雖然目前人工智能已經到達了一種前所未有的科技高度,但是創造和部署這樣的人工智能應用並非易事,需要大量的專業知識和手動設計的解決方案。所以目前AI開發還嚴重依賴經過訓練的AI“手工藝人”或者“工匠”。因此,在這個意義上,可以說我們還正處於“手工AI”的時代。
Peter提到十九世紀歐洲工業設計領域工藝美術運動的創始人William Morris,William認為所有的人都應該可以接觸到美好的東西,但是創作過程對手工藝人的依賴又阻礙了藝術的普及化。正如中國古代的絲綢、玉器一樣,正是由於熟練工匠的缺乏導致這些東西價值不菲。
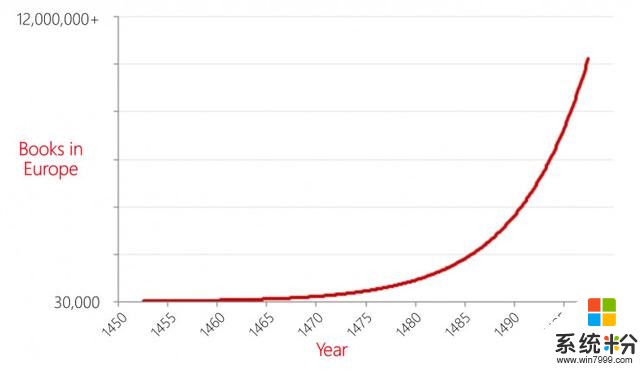
Peter以活字印刷為例。在這項發明之前,歐洲的書籍都以手抄的形式傳播。隨著中國的這項技術傳入歐洲,在十五世紀中期,在短短的50年中,整個歐洲的書籍數量就從3萬本增長到一千兩百萬本。這一變化對當時的社會製度是破壞性的。教堂無法繼續壟斷書籍,新的知識表現形式層出不窮,而人們對教育的期望也從根本上發生了改變。Peter認為,從某種意義上來說,我們麵臨的AI對人類社會的當前結構也將是破壞性的,AI將和活字印刷機一樣改變人類曆史。但是我們還需要從“手工AI”的時代往前走,創造出人人皆可用的AI技術。
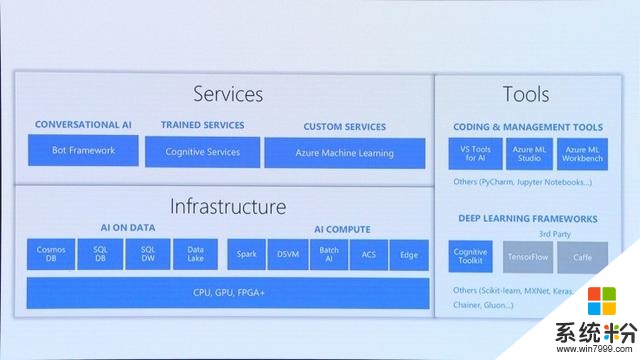
Peter介紹,微軟當前正在著手這樣的工作,以讓更多的人便捷地使用AI技術。他向大家展示了微軟搭建的基於雲的AI平台。其中The Bot Framework可以幫助開發者便捷地搭建聊天機器人,Cognitive Services讓開發者方便地將AI嵌入到每個APP中,Azure Machine Learning則可以幫助你從零開始進行數據研究以及創建AI應用。這個平台有較為先進的數據服務以及最新的硬件設備,支持所有主流開源的機器學習框架,具有良好的擴展性。
John Hopcroft:The AI Revolution(AI 革命)
在本演講中,康奈爾大學計算機係教授、1986年圖靈獎獲得者John Hopcroft帶領大家回顧了機器學習的基礎知識,並分享了一些深度學習領域中比較有趣的研究問題。
John從最簡單的線性分類器(感知器)算法講起。隨後介紹了在數據線性不可分情況下把樣本映射到更高維空間的研究,包括核函數等,這種情況下支持向量機的出現極大地促進了這方麵的研究。在支持向量機之後,機器學習的下一個大的發展就是深度學習。隨著深度神經網絡的引入,特別是卷積神經網絡(卷積神經網絡,由卷積層、池化層、全連接層組成,最後是softmax輸出每個類別的概率)的引入,圖像分類等方麵的錯誤率逐年下降,在2015年微軟亞研院提出的152層深度殘差網絡(ResNet)在圖像分類中超過了人的識別水平。

但是在這方麵還有很多問題值得研究,例如每個門學習的是什麼、怎樣讓第二層的門與第一層的門學習不同的信息、怎樣讓一個門學習的內容隨時間演化、用不同的初始權重門學習的是否是相同的內容、用不同的圖像集訓練兩個網絡早期的門學習的是否相同等等。

此外,在訓練一個深度網絡時,可能會有許多局部極小值,有些極小值可能會比其他的好。如何保證我們在訓練的過程中能夠找到一個好的局部極小值呢?訓練深度網絡往往會花費很長的時間,我們是否可以加速訓練呢?這些也都是非常有意義的研究方向。

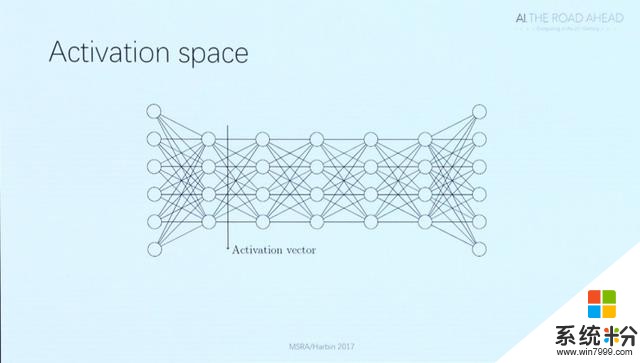
隨後John考慮了當訓練兩個網絡時會出現什麼有趣的研究。對於兩個網絡,我們可以同時訓練,也可以一先一後。

這兩種情況,兩個網絡在激活空間裏是否共享相同的區域呢?

一個當前比較火的例子就是生成式對抗網絡(GAN),這個網絡屬於一先一後的情況。

最後John提出了一個問題:人工智能是真的嗎?他認為,現在的人工智能隻是高維空間中的模式識別,AI還不能提取出一個事物的本質或者理解它的功能。在John看來,要想實現這一點,隻是需要另外40年的時間。

他還說到,其實很多現在看來是智能的任務其實都不是AI,有些隻需要強大的計算以及大數據就足夠了,例如棋類比賽。計算機正在做越來越多的人們以為需要智能的事情,實際上有些並不是AI。所以我們在從事人工智能相關的工作時要想一想,這個問題的核心的是AI嗎?還是僅僅需要大計算而已?
Lise Getoor:Big Graph Data Science(大圖數據分析)
圖數據是 Lise Getoor教授一直以來的研究對象。Lise Getoor教授認為,我們正處於數據爆炸的時代,圖數據無處不在。然而,數量並不代表質量,大數據分析的挑戰之一就在於如何能夠合理利用大型、異構、不完整且帶有噪音的集成數據進行合理推論。

在演講中,Lise Getoor教授首先給我們介紹了一些圖數據所需的常見推理模式。

例如為缺失標簽的節點做標簽預測的協同分類(collective classification),給出數據裏隱含的連接節點的邊的連接預測(link predictions),以及判斷兩個節點是否為同一實體並進行合並的實體分辨(entity resolution)。

隨後她像我們介紹了用於解決這些重要問題的一種工具——概率軟邏輯(probabilistic softlogic ( PSL ),psl.linqs.org)。
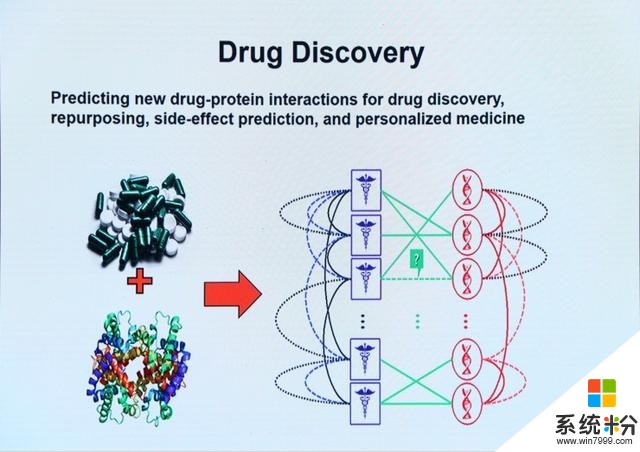
最後她向我們展示了PSL應用的一些案例,例如政治辯論立場分類、混合推薦係統、藥物研究、垃圾郵件檢測等。
Raymond Mooney:The Deep Learning Revolution: Progress, Promise, and Profligate Promotion(深度學習革命)
首先Raymond教授簡單回顧了機器學習的曆史,從單層神經網絡到符號AI和知識工程,到多層神經網絡和符號學習,到統計學習和核方法,再到近年來的深度學習。

1957年,弗蘭克•羅森布拉特(Frank Rosenblatt)提出感知器算法。感知器就是一個最簡單的神經網絡,隻有輸入層和輸出層,沒有隱藏層。感知器利用爬山法從訓練樣本中進行學習更新參數。隻有當樣本線性可分的時候,感知器才能進行學習;很多分類的函數感知器並不能學習,例如XOR。
1969年,馬文•明斯基(Marvin Minsky)和西摩爾•帕普特(Seymour Papert)發表了《Perceptrons: An Introduction to Computational Geometry》,書中描述了簡單神經網絡也就是感知器的局限性。此後七十年代到八十年代初期,神經網絡方麵的研究陷入了低穀。
上個世紀80年代中期連接主義的興起導致了神經網絡的複興,這一時期反向傳播算法被用來訓練3層神經網絡(包含輸入層輸出層以及一個隱藏層)。但是,通用反向傳播算法並不能很好的推廣到更深的網絡,並且其方法也缺乏理論基礎,因此1995-2010這15年間神經網絡的研究陷入了第二次低穀,這一時期機器學習研究的興起轉移到概率圖模型和以支持向量機為代表的核方法。

2010年以後,隨著更好的深度神經網絡訓練方法的提出,神經網絡又卷土重來。深度學習“革命”,Raymond用“革命”一詞來形容深度學習的影響之大。深度學習在幾大方麵取得了成功,包括計算機視覺(主要歸功於卷積神經網絡CNNs)、機器翻譯和語音識別(主要歸功於循環神經網絡RNNs)以及視頻和棋牌遊戲(得益於深度強化學習)。

近年來深度學習的推動力除了前麵提到的更好的訓練算法和模型,還有兩個方麵:大規模有標注的訓練數據和強大的計算力(如GPU)。大數據、大模型、大計算是深度學習成功的三大支柱因素,但它們同時也為深度學習的進一步發展和普及帶來了一些製約因素。現在深度學習麵臨一些新的挑戰,包括(1)如何從無標注的數據裏學習,(2)如何降低、壓縮模型大小,(3)全新的硬件設計、算法設計、係統設計來加速深度神經網絡的訓練和使用,(4)如何與知識圖譜、邏輯推理、符號學習相結合像人一樣從小樣本進行有效學習,(5)如何在複雜的動態係統裏進行博弈機器學習。
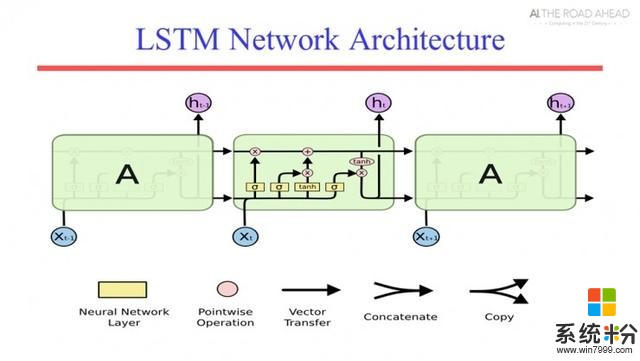
隨後Raymond教授簡單介紹了卷積神經網絡、循環神經網絡以及深度強化學習的基本內容,並分析了為什麼在人工智能領域,科學家總是熱衷於讓AI跟人類下棋,玩遊戲?

從簡單的跳棋、五子棋,到更加複雜的中國象棋、國際象棋,以及最近非常熱門的圍棋和德州撲克,每次AI在某個智力遊戲上成功地擊敗人類選手,便會讓大家唏噓不已,慨歎AI會在不久的將來取代人類。而科學家之所以樂於選擇棋類遊戲,一方麵是因為它們自古以來就被認為是人類智力活動的象征,模擬人類活動的AI自然要以此為目標。成功達到人類甚至高於人類水平,可以吸引更多人關注並投身於人工智能的研究和應用中來。另一方麵,棋類也很適合作為新的AI算法的標杆(Benchmark)。棋類遊戲的規則簡潔明了,輸贏都在盤麵,適合計算機來求解。理論上隻要在計算能力和算法上有新的突破,任何新的棋類遊戲都有可能得到攻克。一個會下棋的AI也並非科學家的終極目標,其更積極的意義在於,AI算法在研究棋藝的過程中不斷精進和提升,會帶來更多設計上的創新,從而在根本上提升人工智能算法的能力和適用範圍。

Raymond教授認為機器學習、神經網絡等有著悠久的曆史,深度學習也取得了很多成績,並且還將取得更多成績,但現在深度學習的能力被過度誇大了,其有著明顯的局限性,還不能真正解決AI問題。Raymond認為我們不能過於滿足和誇大當前的成績,AI的核心問題尚未解決,未來的路還很長。
滕尚華:Scalable Algorithms for Big Data and Network Analysis(大數據和網絡分析的可擴展算法)
身處大數據時代,我們對高效算法的需求比先前任何時候都要突出。滕尚華教授指出,大數據將我們帶入我們先驅者所設想的漸近世界,但問題規模的爆炸式增長也對經典算法的有效性提出挑戰:根據多項式時間表征,以前被認為有效的算法可能不再適用,有效的算法應該是可擴展的。換句話來說就是,問題的複雜性就問題的大小而言,應當是線性的或近似線性的。因此可擴展性應該被提升為用於表征高效運算的中心複雜性概念。而設計具有可擴展性的算法,需要借助一些技巧,例如拉普拉斯範式。這類技巧包括局部網絡探索、高階抽樣法、稀疏化以及圖分割等。此外還包括譜圖理論方法,如用於計算電流和在高斯-馬爾可夫隨機場中取樣等。這些方法體現了網絡分析中組合、數值和統計思維的融合。滕尚華教授在演講中,通過一些基本的網絡分析問題解釋了這些技巧的應用,特別是在社會和信息網絡中確定重要的節點和連貫的社區中的應用。
注:由於此時記者正在采訪其中一位嘉賓,沒能聆聽滕尚華教授的報告內容,深表遺憾。
洪小文:探索機器和人類學習的方式
在本演講中,洪小文博士將介紹微軟亞洲研究院在幫助機器學習方麵取得的最新成果,例如對偶學習和自生成數據學習。此外,他還強調了機器學習目前麵臨的一些重要挑戰。

洪小文博士表示近年來,機器學習在計算機視覺、語音和自然語言處理等領域取得了長足的進步。隨著人工智能對社會的影響越來越大,更多挑戰需要人們去研究、去攻克,因此無論是對人類還是機器來說,我們都進入了持續學習的時代:從“無所不知”到“無所不學”。
對偶學習對於計算機而言,學習需要時間、數據和老師,而深度學習則需要大規模的標記數據。數據標記的成本非常高,並且在很多應用場景中,獲取大量標記數據已是難題(例如罕見疾病、少數民族語言等)。為了降低對大規模標注數據的依賴性,微軟亞洲研究院的研究員提出了一種新的學習範式——對偶學習。

很多人工智能的應用涉及兩個互為對偶的任務。例如,機器翻譯中從中文到英文翻譯和從英文到中文的翻譯互為對偶,語音處理中語音識別和語音合成互為對偶,圖像理解中基於圖像生成文本和基於文本生成圖像互為對偶等等。這些互為對偶的任務可以形成一個閉環,使從沒有標注的數據中進行學習成為可能。
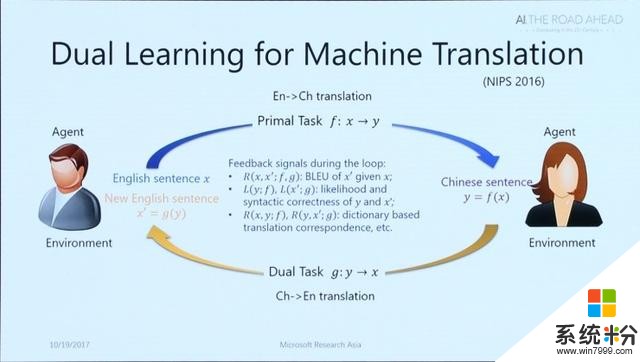
對偶學習的最關鍵一點在於,給定一個原始任務模型,其對偶任務的模型可以給其提供反饋。同樣的,給定一個對偶任務的模型,其原始任務的模型也可以給該對偶任務的模型提供反饋,從而這兩個互為對偶的任務可以相互提供反饋,相互學習、相互提高。
洪小文博士表示除了機器翻譯,對偶學習還可以用於訓練圖像分類生成、情感分析等多個研究領域。
自增強學習介紹完對偶學習,洪小文博士開始探討在多個領域展示出優勢的卷積神經網絡CNN是否同樣適用於3D圖形領域。和其他學習任務一樣,訓練CNN需要大規模的數據,保證大量的圖片輸入和與之對應的材質屬性。而數據采集需要非常多複雜的設備支持、相對更長的采集時間,同時要求大量的手工工作,這其中的成本是相當高昂的。

為了利用這些海量的未標定的照片來進行機器學習,我們設計了自增強訓練的方法(Self-augmented training)。自增強訓練采用了一種特殊的CNN訓練方式,區別於傳統利用標注的輸入輸出對作為訓練數據的訓練方法,自增強訓練利用當前尚未訓練好的CNN來對未標定的數據進行測試。
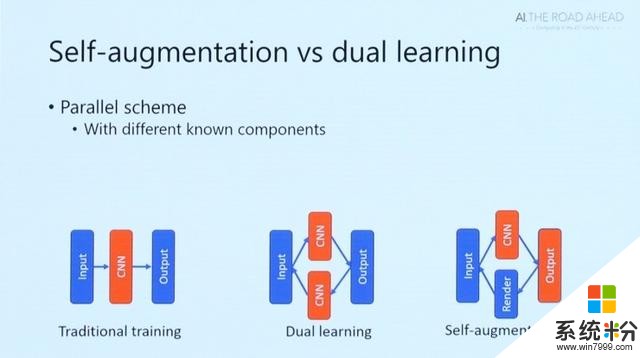
當然,由於現在CNN還沒有訓練好,測試結果肯定不能作為正確的標定用來訓練。但是,我們對材質屬性估計這個問題的逆問題,具有完整的知識。因此,可以用這個中間測試結果得到的材質屬性,配合現有的材質渲染程序,生成一個當前中間結果的材質屬性和其對應的渲染結果(照片)的數據對,這一數據對是完好保持紋理照片和紋理屬性這一對應關係的“正確標定數據對”,因此我們就可以放心地利用這一自增強出來的數據來進行訓練。
AI 創造除機器進行自身學習以外,人類同樣需要提升自己的技能。

洪小文博士表示機器還可以在多方麵幫助人們學習,例如提供學習建議和案例,作為語言學習的輔助手段。AI還可以有藝術創造力:創作詩歌、歌詞以及音樂,對圖片進行風格轉換等。
微軟小英
首先,洪小文博士介紹了微軟小英。它可以幫助初學者快速建立日常英語溝通能力,幫助英語學習者完善發音,熟練口語。微軟小英融合了語音識別、語音合成、自然語言理解、機器翻譯、機器學習、大數據分析等人工智能前沿技術。
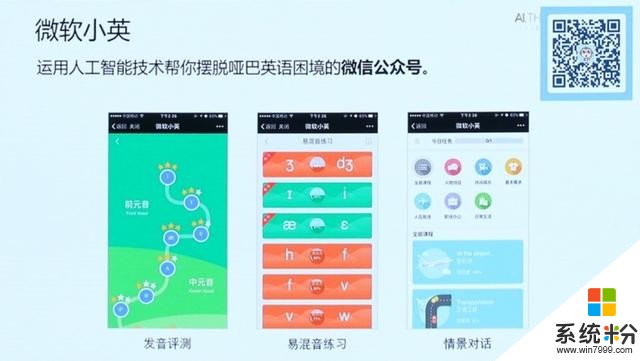
小英的口語評測係統搭建在一個由機器學習訓練成的神經網絡的語音識別係統上,基本處理流程是利用語音識別模型,根據跟讀文本對用戶的錄音進行音素層級的切分。每一個小單元再和其相應的標準發音模式進行匹配,發音越標準則匹配越好,得分也越高。係統中各個標準發音的模型是深層神經網絡在幾百個發音標準的美式英語數據庫中訓練而成的。
微軟小冰
隨後,在AI的藝術創造方麵,洪小文博士介紹了微軟小冰的寫詩能力。據介紹,小冰寫詩,主要是運用了生成式對抗網絡(GAN)。
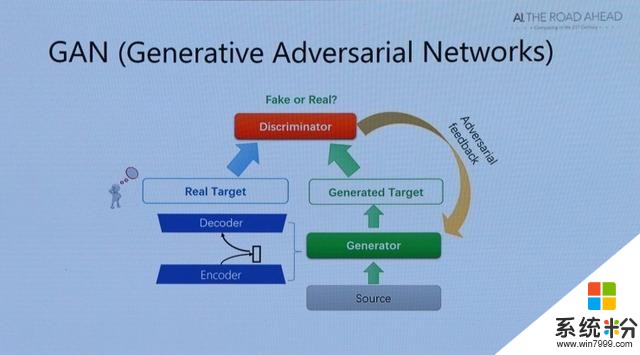
簡單來說就是,有一個詩歌生成模型(generator),它的目標是生成一首接近於人類創作的詩歌;與此同時我們有一個詩歌判別模型(discriminator),它的目標是能夠正確判別一首詩是機器生成出來的還是人類寫的。詩歌生成模型和判別模型之間進行博弈,直至生成模型與判別模型無法提高自己——即判別模型無法判斷一首詩是生成出來的還是真實的而結束。小冰於今年出版了第一本現代詩集《陽光失了玻璃窗》,洪小文博士現場展示了小冰創作的詩 。



除了作詩,她還能根據詩詞譜音,創作一首歌曲。


風格遷移
此外,洪小文博士還介紹了深度學習運用到圖片風格遷移的研究。他們利用卷積神經網絡分解內容圖片和風格圖片的特點,然後加以融合。微軟亞研院的研究員在CVPR 2017上發表了一種新的風格遷移算法,該算法對圖像的風格提供了一種顯式的表達“風格基元”(styleBank),通過對不同風格的圖片使用不同的“風格基元”,再用簡單的自解碼器模型(auto-encoder)便可以實現不同風格的遷移。目前這項風格遷移技術已經被應用到最新的相機應用Microsoft Pix iOS版, 允許用戶將照片的紋理、圖案和色調轉化成所選定的風格,使之成為一件獨特的創作作品。

洪小文博士補充道,除上述算法以外,微軟亞洲研究院的研究員們還提出了一個端到端 ( end-to-end ) 的在線視頻風格遷移模型 ( Coherent Online Video Style Transfer )。

這個模型在處理相鄰幀的連續性的做法是:對於可追蹤的區域,用前一幀對應區域的特征以保證連續性,而對於遮擋區域,則用當前幀的特征,最後得到既連續又沒有重影的風格化結果。

而對於更為精確和精致的視覺特征轉化,需要建立圖像間的語義對應。微軟亞研院的研究員們提出了一種新的算法,結合圖像對偶技術(Image Analogy)和深度神經網絡(DNN),為內容上相關但視覺風格迥異的兩張圖像之間建立起像素級的對應關係,從而實現精確地視覺特征遷移。

最後洪小文博士總結到:人類和機器都進入了持續學習的時代:從“無所不知”到“無所不學”;學習過程永遠需要時間、數據和老師,而在學習過程中,機器和人類將一同共進化;對偶學習等新的方法讓缺乏大量標記數據的機器學習成為可能;Encoder-decoder DNN 以及 GAN等神經網絡讓機器有了藝術創造力;人類可以利用機器更好地學習。
相關資訊
最新熱門應用

必安交易所官網手機版安卓
其它軟件179MB
下載
通證交易所app安卓
其它軟件44.12MB
下載
幣鋒交易所
其它軟件223.89MB
下載
富比特交易平台app鏈接2024安卓版
其它軟件276 MB
下載
全球幣交易所app官方版安卓
其它軟件34.95 MB
下載
熱幣全球交易所app最新版蘋果手機
其它軟件38.33MB
下載
matic交易所
其它軟件225.08MB
下載
比特可樂交易所鏈接
其它軟件7.27 MB
下載
defi去中心化交易所
其它軟件166.47M
下載
易歐數字app官網安卓手機
其它軟件397.1MB
下載