
人工智能算法重磅微軟提出字符字體轉換和神經風格轉換的統一框架(特約點評:人工智能之(重磅)微軟提出字符字體轉換和神經風格轉換的統一框架對於對風格統一轉移提供了新的思路,這個創新點趣說人工智能必須推薦。來自網友小星的推薦!)
人工智能之(重磅)微軟提出字符字體轉換和神經風格轉換的統一框架簡介:近年來,風格轉換作為深度神經網絡(DNNs)的一個有趣的應用已經引起了研究界越來越多的關注。根據樣式類型,樣式轉換可以分為兩類應用程序:將字符從字體轉移到另一個字符的字符字體轉換,以及旨在將神經圖像轉換為給定藝術風格的神經風格轉移。字符字體轉換通常涉及高頻特征的變化,例如對象形狀和輪廓,這使得字符字體轉移比神經風格轉移更困難。而且,這些字符具有清晰的語義含義,不正確的轉換可能導致無意義的字符。與字符字體轉換不同,神經風格轉移主要是關於紋理的轉移,其中源圖像和目標圖像通常共享物體形狀和輪廓等高頻特征,即內容保持不變。
最早的關於字符字體轉換的研究通常基於人工提取的特征,例如部首和筆劃[18,36,38,40]。最近,一些研究嚐試自動學習基於DNN的轉換,並將字符字體轉換模型作為圖像到圖像的轉換問題。通常情況下,為每個源和目標樣式對建立專用模型[1],[23],使得模型難以歸納為新的樣式,即需要為新樣式培訓附加模型。為了實現字體轉換而不需要再訓練,提出了一種多內容生成對抗網絡(GAN),該網絡可以轉換目標風格中給定幾個字符的英文字體的字體[4]。
最早的神經風格轉移研究通常采用迭代優化機製來生成噪聲圖像中具有目標風格和內容的圖像[11]。由於時間效率低下,為此提出了一種前饋發電機網絡[15],[31]。針對傳輸網絡提出了一組丟失,如像素丟失[13],感知丟失[15],[37]和直方圖丟失[34]。最近,GANs [21],[41]的變體通過向傳輸網絡添加鑒別器來引入,該鑒別器將對抗性損失與傳輸損耗相結合以產生更好的圖像。然而,這些研究旨在明確地學習從內容圖像到具有特定風格的圖像的轉換,並且學習的模型因此不能推廣到新的風格。到目前為止,任意神經風格轉移的工作仍然有限。
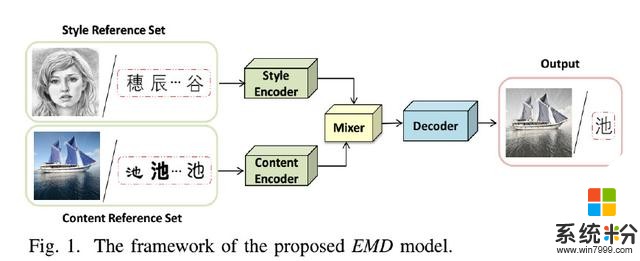
人工智能之(重磅)微軟提出字符字體轉換和神經風格轉換的統一框架貢獻:在本文中,基於我們以前的工作[39],我們提出了一個統一的字體字形轉換和神經風格轉換的樣式轉換框架,使轉換模型可以很好地推廣到新的風格或內容。與現有的樣式轉換方法不同,為每對樣式轉換構建單獨的轉換網絡,所提出的框架使用一小組參考圖像表示每種樣式或內容,並試圖學習樣式和內容的單獨表示。然後,為了生成給定樣式 - 內容組合的圖像,簡單地混合相應的兩個表示。這種學習框架允許在多種風格之間同時進行風格轉移,並且可以被視為一種特殊的“多任務”學習場景。通過獨立的風格和內容表示,框架能夠生成所有風格 - 內容組合的圖像,並給出相應的參考集合,因此可以很好地推廣到新的風格和內容。據我們所知,與我們最相似的研究是Tenenbaum和Freeman [30]提出的雙線性模型,它通過矩陣分解獲得了獨立的樣式和內容表示。但是,為了準確分解新的樣式和內容,雙線性模型需要詳盡列舉一些可能無法用於某些樣式/內容的示例。如圖1所示,所提出的樣式傳輸框架,之後表示為EMD,由樣式編碼器,內容編碼器,混合器和解碼器組成。給定一個或一組參考圖像,風格編碼器和內容編碼器分別用於從風格參考圖像和內容參考圖像中提取風格和內容因子。混合器然後結合相應的風格和內容表示。最後,解碼器基於組合表示生成目標圖像。
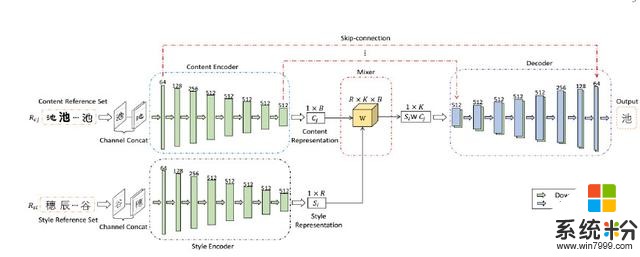
在這個框架下,我們分別設計了兩個單獨的字符字體轉移網絡和神經風格轉移網絡。對於字符字體轉換,為了分離樣式特征和內容特征,我們利用給定圖像的樣式和內容的條件依賴性,並采用雙線性模型來混合這兩個因素。對於神經風格轉移,我們利用先前的知識,即某些層中的特征地圖的統計信息可以表示風格信息,並通過統計匹配將這兩個因子混合。在訓練中,針對所提出的網絡的每個訓練樣例被提供為風格內容對<Si,Cj> 其中Si和Cj分別是樣式和內容參考集,每個由相應樣式Si和內容Cj的r個圖像組成。 對於字符字體傳輸,整個網絡是端對端訓練,加權L1損失,測量生成的圖像和目標圖像之間的差異。 對於神經風格轉移,由於缺乏監督目標圖像,我們通過比較生成圖像的特征圖與風格/內容參考圖像的特征圖來分別計算內容損失和風格損失。 因此,神經風格轉移是無監督的。 而且,由於對於獲得相同內容或樣式的圖像的困難,僅將一個樣式和內容參考圖像用作輸入(即,r = 1)。 廣泛的實驗結果證明了我們的風格轉移方法的有效性和魯棒性。
我們研究的主要貢獻總結如下:
•我們提出了一個統一的樣式轉換框架,用於字符字體轉換和神經風格轉換,它們學習不同的風格和內容表示。
•該框架使得傳遞模型可以推廣到任何看不見的風格/內容,並給出幾張參考圖片。
•在這個框架下,我們分別設計了兩個字符字體轉換網絡和神經風格轉換網絡,這些網絡在實驗驗證中表現出了令人鼓舞的結果。
•這種學習框架允許在多種風格之間同時進行風格轉換,可以被視為一種特殊的“多任務”學習場景。
人工智能之(重磅)微軟提出字符字體轉換和神經風格轉換的統一框架字符字體轉移:1)數據集:為了評估所提出的具有中文字體轉換任務的EMD模型,我們構建了832個字體(樣式)的數據集,每個字體具有1732個常用中文字符(內容)。所有圖像的大小為80 80像素。我們隨機選擇75%的樣式和內容(即624列車樣式和1299列車內容),剩下25%作為新穎的樣式和內容(即208種新穎風格和433種新穎內容)。整個數據集被相應地劃分為如圖4所示的四個子集:D1,具有已知樣式和內容的圖像,D2,具有已知樣式但新穎內容的圖像,D3,具有已知內容但新穎樣式的圖像以及D4,具有已知樣式和內容的圖像新穎的風格和新穎的內容。訓練集從D1中選擇,並且分別從D1,D2,D3和D4中選擇四個測試集。這四個測試集代表了不同級別的風格轉移挑戰。
實現細節:在我們的實驗中,Style Encoder和Content Encoder中卷積層的輸出通道分別是C的1,2,4,8,8,8,8,8倍,其中C = 64。對於混音器,我們在實現中設置R = B = K。解碼器前7個解卷積層的輸出通道分別為C的8,8,8,4,2,1倍。我們將初始學習率設為0.0002,並使用Adam優化方法端到端地訓練模型,直到輸出穩定。
在每個實驗中,我們首先從D1中隨機采樣具有已知內容和已知風格的Nt目標圖像作為訓練實例。然後,我們通過對結構的r圖像進行隨機采樣,為每個目標圖像構建兩個參考集。每行代表一種樣式,每列代表一種內容。目標圖像由隨機分散的紅色“x”標記表示。目標圖像的參考圖像從相應的風格/內容中選擇,如風格參考圖像的橙色圓圈和內容參考圖像的綠色圓圈所示。
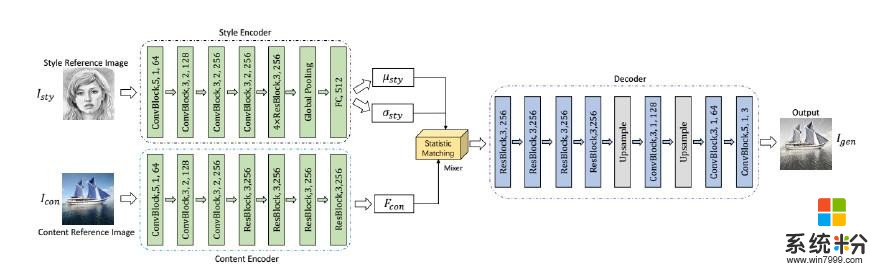
人工智能之(重磅)微軟提出字符字體轉換和神經風格轉換的統一框架:神經風格轉移:1)實現細節:根據以前的研究[12] [15],我們使用MS-COCO數據集[19]作為內容圖像,主要從維基百科[3]收集的繪畫數據集作為樣式圖像。每個數據集大約包含80,000個訓練樣例。該模型使用Adam優化器進行訓練,學習率為0.0001。批量大小設置為8個樣式內容對。我們計算風格使用Relu1 2,Relu2 2,Relu3 3,Relu4 3層VGG-19和使用Relu4 1層損失內容。我們設定λc= 1,λs= 5和λtv= 1e-5。在訓練過程中,我們首先將兩幅圖像的最小尺寸調整為512,同時保留縱橫比,然後隨機裁剪尺寸為256 256的區域。由於Style Encoder中完全連接圖層的大小僅與濾鏡數量有關,因此我們的模型可以在測試過程中應用於任何尺寸的樣式/內容圖像。
2)比較方法:我們將提出的神經風格轉移模型與以下三種類型的基線方法進行比較:
•快速但不靈活的每種樣式每種模式方法,它僅限於單一樣式,不能推廣到新樣式。這裏我們使用最先進的方法TextureNet [32]為例。 TextureNet主要是一個生成器,它將噪聲變量z和內容參考圖像作為輸入,並生成具有目標樣式/內容的圖像•靈活但緩慢的基於優化的方法[11],該方法優化了一個噪聲圖像與目標樣式和內容迭代地在預訓練的VGG網絡的幫助下•靈活且快速的任意風格 - 每模型方法,其可以實現任意樣式傳輸而不需要再訓練。在這項研究中,我們與以下三種方法進行比較:-Patch-based [8]:基於補丁的方法通過交換每個內容特征補丁與最近的樣式補丁來進行樣式傳輸。網絡由卷積網絡,反向網絡和樣式交換層組成。-AdaIn [12]:AdaIn基於自適應實例規範化,AdaIn網絡由編碼器,解碼器和自適應實例規範化層組成,其中編碼器被固定為VGG-19的前幾層.-通用[16]:通用是基於在一係列預編碼的編碼器 - 解碼器圖像重建網絡中嵌入的白化和著色變換而設計的。在在基線方法上方,TextureNet在傳輸質量方麵比其他四種基線方法更令人印象深刻,因此我們將其作為基準。這些基準方法的結果都是通過使用默認配置運行其發布的代碼而獲得的。
人工智能之(重磅)微軟提出字符字體轉換和神經風格轉換的統一框架結論和未來工作:在本文中,我們提出了一種用於字符字體轉換和神經風格轉換的統一樣式轉換框架EMD,它使得轉換模型可以推廣到新的風格和內容,給出一些參考圖像。主要思想是,從這些參考圖像中,風格編碼器和內容編碼器分別提取風格和內容表示。然後,提取的樣式和內容表示由混音器混合並最終饋送到解碼器以生成具有目標樣式和內容的圖像。這種學習框架允許在多種風格之間同時傳遞樣式,並且可以被視為一種特殊的“多任務”學習場景。然後將學習到的編碼器,混音器和解碼器作為共享知識,傳遞神經風格的轉移任務。這兩項任務的廣泛實驗結果證明了它的有效性。
在我們的研究中,學習過程由一係列圖像生成任務組成,我們試圖通過學習高層次的策略來學習一種能夠推廣到新的但相關的任務的模型,即學習風格和內容表示。這類似於“學習學習”計劃。未來,我們將探討更多關於“學習學習”並將其與我們的框架相結合
相關資訊
最新熱門應用

bicc交易所app蘋果
其它軟件45.94MB
下載
香港ceo交易所官網
其它軟件34.95 MB
下載
歐意錢包app
其它軟件397.1MB
下載
aibox交易所app
其它軟件112.74M
下載
btcc交易平台app
其它軟件26.13MB
下載
zb交易平台官網
其它軟件223.89MB
下載
芝麻交易平台官方安卓版
其它軟件223.89MB
下載
易歐交易所app官網安卓蘋果
其它軟件397.1MB
下載
滿幣交易所app
其它軟件21.91MB
下載
天秤幣交易所蘋果app
其它軟件88.66MB
下載