
選自arXiv
作者:羅人千、田飛、秦濤、劉鐵岩
機器之心編譯
參與:高璿、路
近期,來自微軟和中國科學技術大學的劉鐵岩等人發表論文,介紹了一種新型自動神經架構設計方法 NAO,該方法由三個部分組成:編碼器、預測器和解碼器。實驗證明,該方法所發現的架構在 CIFAR-10 上的圖像分類任務和 PTB 上的語言建模任務中都表現強勁,在計算資源明顯減少的情況下優於或持平於之前的架構搜索最佳方法。
從幾十年前 [13, 22] 到現在 [48, 49, 28, 39, 8],無人幹預的神經網絡架構自動設計一直是機器學習社區的興趣所在。關於自動架構設計的最新算法通常分為兩類:基於強化學習(RL)的方法 [48, 49, 37, 3] 和基於進化算法(EA)的方法 [42, 35, 39, 28, 38]。在基於 RL 的方法中,對架構組件的選擇被看作是一個動作。一係列動作定義了神經網絡的架構,其開發集準確率被用作獎勵。在基於 EA 的方法中,搜索是通過架構組件的變異和再組合來進行的,性能更優的架構會被篩選出來繼續進化。
可以很容易觀察到,基於 RL 和 EA 的方法本質上都是在離散的架構空間中執行搜索。因為神經網絡架構的選擇通常都是離散的,例如 CNN 中的濾波器大小還有 RNN 單元中的連接拓撲(connection topology)。然而,在離散空間中直接搜索最優架構是很低效的,因為隨著選擇的增加,搜索空間會呈指數增長。本研究提出一種優化網絡架構的新方法,將架構映射到一個連續的向量空間(即網絡嵌入),利用基於梯度的方法在該連續空間進行優化。一方麵,與自然語言的分布式表示類似,架構的連續表示在表示拓撲信息時更加緊湊和有效; 另一方麵,由於更加平滑,在連續空間中進行優化比在離散空間內直接搜索容易得多。
研究者將這種基於優化的方法稱為神經架構優化(NAO),如圖 1 所示。NAO 的核心是一個編碼器模型,負責將神經網絡架構映射到一個連續表示(圖 1 左側藍色箭頭)。在連續表示上建立一個回歸模型來逼近架構的最終性能(如開發集上的分類準確率,圖 1 中間黃色部分)。這裏值得注意的是,回歸模型類似於之前研究中的性能預測器 [4, 27, 11]。新方法與之的區別在於如何利用性能預測器:之前的研究 [27] 使用性能預測器作為啟發來選擇已生成的架構,以加速搜索過程,而新方法直接優化模塊,並通過梯度下降獲得更好網絡的連續表示(圖 1 中間底部黑色箭頭)。然後利用優化的表示來產生預測性能更好的新神經網絡架構。為了實現這一點,NAO 的另一個關鍵模塊被設計成解碼器,從連續表示中恢複離散架構(圖 1 右側紅框箭頭)。解碼器是配備了注意力機製的 LSTM 模型,可以實現精準恢複。這三個組件(即編碼器、性能預測器和解碼器)在多任務設置中接受聯合訓練,這有利於連續表示:恢複架構的解碼器目標能進一步改善架構嵌入的質量,更有效地預測性能。
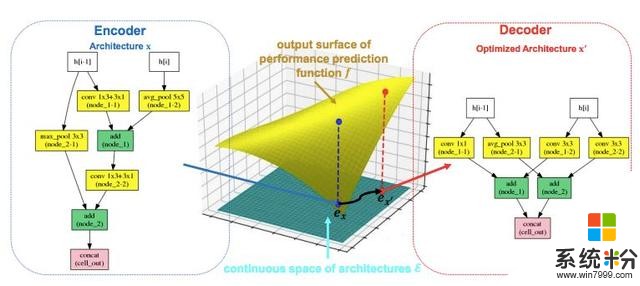
圖 1:NAO 的總體框架。原始架構 x 通過編碼器網絡映射到連續表示 e_x。然後通過最大化性能預測器 f 的輸出將 e_x 優化為 ex',然後使用解碼器網絡將 ex'轉換為新架構 x'。
研究者進行了大量實驗來驗證 NAO 在圖像分類和語言建模任務上的有效性。使用之前研究 [48, 49, 37, 27] 常用的架構空間,通過 NAO 找到的架構在 CIFAR-10 上達到了 2.07% 的測試集誤差率(使用了 cutout 正則化 [12])。此外,在 PTB 數據集上,該架構實現了 55.9 的困惑度,也超過了神經架構搜索方麵的之前最優方法。此外,研究者還展示了:使用最近 [37] 提出的 ENAS 中的權重共享機製來減少子模型參數空間中的較大複雜度,該方法可以提高發現強大的對流和循環架構的效率,例如,在 1 個 GPU 上花費不到 10 小時。研究者將很快發布代碼和模型。
論文:Neural Architecture Optimization

論文鏈接:https://arxiv.org/abs/1808.07233
摘要:自動神經架構設計非常有助於發現強大的神經網絡結構。現有的方法,無論是基於強化學習(RL)還是進化算法(EA),都是在離散空間中進行架構搜索,效率非常低。本文提出了一種基於連續優化的自動神經架構設計方法。這種新方法被稱為神經架構優化(NAO)。該方法有三個關鍵部分:(1)編碼器,將神經網絡架構嵌入/映射到連續空間;(2)預測器,將網絡的連續表示作為輸入,並預測其準確率;(3)解碼器,將網絡的連續表示映射回其架構。性能預測器和編碼器使我們能夠在連續空間中執行基於梯度的優化,以找到潛在的準確率更高的新架構嵌入。然後將這個更優的嵌入使用解碼器解碼到網絡。實驗表明,該方法所發現的架構在 CIFAR-10 上的圖像分類任務和 PTB 上的語言建模任務中都表現強勁,在計算資源明顯減少的情況下都優於或持平於之前的架構搜索最佳方法。其中 CIFAR-10 圖像分類任務的測試集誤差率為 2.07%,PTB 語言建模任務的測試集困惑度為 55.9。在兩個任務中發現的最優架構可被成功遷移到其他任務,如 CIFAR-100 和 WikiText-2。此外,結合最近提出的權重共享機製,我們在計算資源都很有限的情況下(在一個 GPU 上 10 小時)在 CIFAR-10 和 PTB 上發現了功能強大的架構,前一個任務上的最優模型誤差率為 3.53%,後一個任務上的困惑度為 56.3。

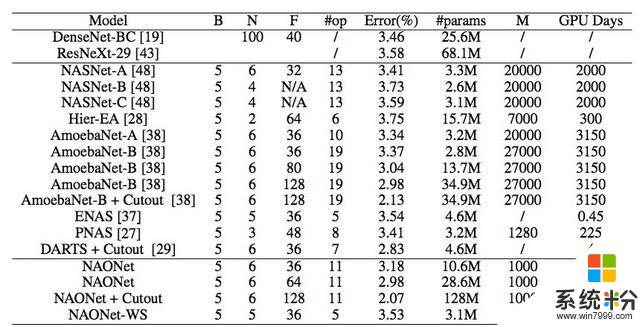
表 1:CIFAR-10 數據集上不同 CNN 模型的表現。
B 是單元內的節點數。N 是發現的正常單元(normal cell)被展開形成最終 CNN 架構的次數。F 表示濾波器大小。#op 是對單元中一個分支的不同操作數,是自動架構設計算法的架構空間尺度指標。M 是經過訓練以獲得所需性能的網絡架構總數。/ 表示該標準對特定算法無意義。NAONet-WS 表示 NAO 發現的架構和權重共享方法。
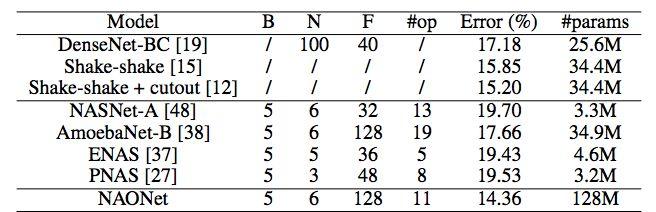
表 2:CIFAR-100 數據集上不同 CNN 模型的表現。NAONet 代表 NAO 在 CIFAR-10 上發現的最優架構。
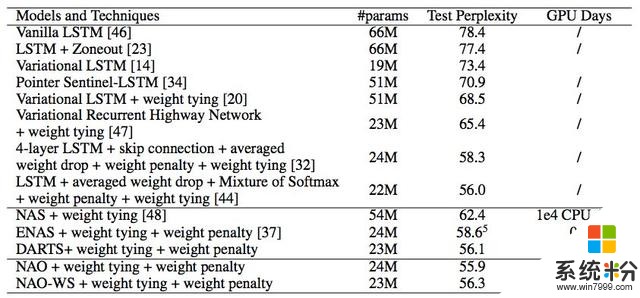
表 3:PTB 數據集上不同模型和技術的表現。與 CIFAR-10 實驗類似,NAO-WS 代表具備權重共享機製的 NAO。
表 4:WT2 數據集上不同模型和技術的表現。NAONet 代表 NAO 在 PTB 上發現的最優架構。
本文為機器之心編譯,轉載請聯係本公眾號獲得授權。
✄------------------------------------------------
加入機器之心(全職記者 / 實習生):hr@jiqizhixin.com
投稿或尋求報道:content@jiqizhixin.com
廣告 & 商務合作:bd@jiqizhixin.com
相關資訊
最新熱門應用

幣團交易所app
其它軟件43MB
下載
歐幣網交易所官網安卓
其它軟件397.1MB
下載
safe交易所安卓版
其它軟件3.64MB
下載
中幣交易所官網app蘋果
其它軟件288.1 MB
下載
zb交易所app最新官網2024
其它軟件225.08MB
下載
派網量化交易所app
其它軟件136.21 MB
下載
bitstamp交易所app
其它軟件33.27MB
下載
v8國際交易所app蘋果手機
其它軟件223.89MB
下載
雷達幣交易所官方網站軟件安卓版
其它軟件292.97MB
下載
歐意交易所官網蘋果手機
其它軟件397.1MB
下載