

出品 | AI科技大本營(ID:rgznai100)
近日,由阿裏巴巴達摩院語言技術實驗室研發的 Multi-Doc Enriched BERT 模型在微軟的 MS MARCO 數 據評測任務,Passage Retrieval Task(文檔檢索排序)和 Q&A; Task(開放域自動問答)中雙雙刷新記錄,均取得榜首(截止 2019 年 6 月 26 日)。
MS MARCO 挑戰賽是 AI 閱讀理解領域的權威比賽,包含 100 多萬問題和近千萬篇文檔,參賽機構提供的 AI 模型需要從這些文檔中找出 100 萬個問題的正確答案。參與此次評比的還有微軟、Facebook 等公司。
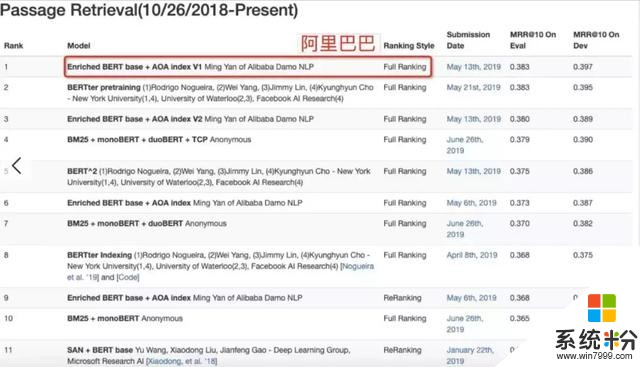
與斯坦福大學發起的 SQuAD 挑戰賽不同,MS MARCO 數據集模擬了搜索引擎中的真實應用場景,其難度更大,是機器閱讀理解領域最有應用價值的數據集之一。MS MARCO 挑戰賽需要參賽者提交的模型具備理解長文檔多段落,並回答複雜問題的能力。對於每一個問題,MS MARCO 提供多篇來自搜索結果的網頁文檔,AI 需要通過閱讀這些文檔來回答用戶提出的問題。但是,文檔中是否含有答案,以及答案具體在哪一篇文檔或段落中,都需 AI 自己來判斷解決。
更難的是,有一部分問題無法在文檔中直接找到答案,需要 AI 自由發揮做出判斷。這對機器閱讀理解提出了更高要求,需要 AI 具備綜合理解多文檔信息、聚合生成問題答案的能力。
阿裏的突破在於提出了基於“融合結構化信息 BERT 模型”的“深度級聯機器閱讀模型”, 可以模仿人類閱讀理解的過程,先對文檔進行快速瀏覽,判斷,然後針對相應段落進行精讀,並根據“自己的理解”回答問題。 其中,阿裏巴巴自研的算法成果——“深度級聯機器閱讀模型”已被 AAAI 2019 收錄。
這是繼 2018 年《Multi-granularity hierarchical attention fusion networks for reading comprehension and question answering》(ACL 2018)在單文檔閱讀理解(斯坦福 SQuAD 挑戰賽)取得的成果後,阿裏巴巴研究團隊在機器閱讀理解領域的又一次突破。
機器閱讀理解模型需要的輸入是,業務應用中,枚舉所有Document,計算並排序答案後給出最終答案顯然不實際;另一方麵,設計完全的 IR+MRC 的端到端(End2End)模型, 並輔以 Joint Trainning 在線上部署和實際使用時也會遭遇模型過大導致的性能瓶頸。因此,采用 Question 相關文檔選擇及文檔中段落裁剪,並將有限且相關的備選段落交給 MRC 模型的方案是兼顧 Effectiveness 和 Efficiency 的核心策略。
阿裏巴巴研究團隊在 MS MARCO 上提交的 Multi-Doc Enriched BERT 模型,正是為了解決上述問題。團隊先於2019年初提出了級聯學習框架《A Deep Cascade Model for Multi-Document Reading Comprehension》(AAAI 2019),設計出深度級聯機器閱讀框架,該方案可有效降低召回階段延時,並最大化答案準確率,算法在召回和排序上逐步從文檔級別,段落級別演化,並在最後有限的備選段落中進行答案提取工作。
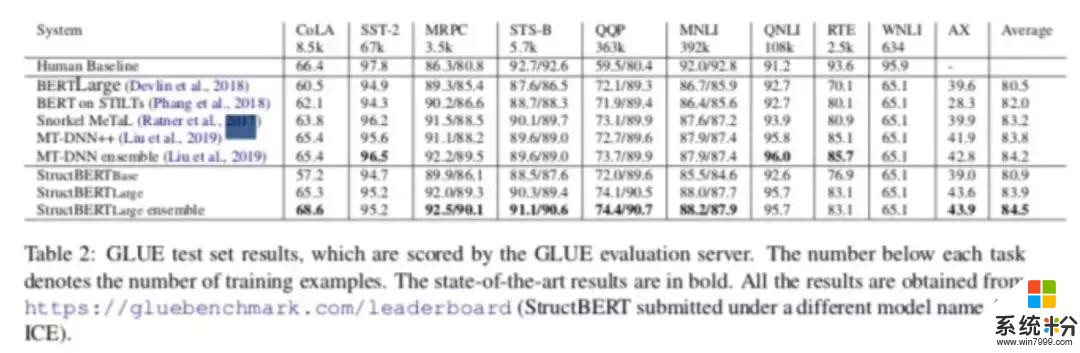
隨後,研究團隊提出了 Enriched BERT 模型,配合 Deep Cascade Model 框架,在多文閱讀理解上超過了之前廣泛使用的 IR Based MRC 模型。其中,負責提供語義表征的 Enriched BERT 模型除了在 MS MARCO 上作為語言模型幫助取得雙料冠軍外,在國際公認的自然語言理解標準數據集 GLUE Benchmark 上也取得了 Top3 的成績(相關技術近期公開)。
特別在 MS MARCO Q&A; Task 上,阿裏方麵稱,較之前最先進的模型有 1.5% 的 Rouge-L 絕對提升。此外,在 MS MARCO Passage Retrieval Task 上,他們自研的 Enriched BERT Base 模型領先於其他模型。
阿裏方麵介紹,阿裏 AI 可以像人類一樣在閱讀並理解後快速應對天馬行空的問題。比如阿裏 AI 可以在毫秒內讀完 2 億字的巨著, 相當於 5 本《大英百科全書》,並根據自己的理解快速回答 100 多萬個不同領域的不同問題。例如 2014 年足球世界杯的冠軍是誰?哈利波特在哪裏上學的?什麼是宇宙中最強的磁場?阿裏 AI 可以分別迅速給出答案,這一研究水平可以應對高中英語閱讀理解試題。

(這一AI能力已應用在阿裏電子商務平台中)
對人類而言, 閱讀是獲取知識、不斷進步的重要途徑;對機器而言,同樣如此。阿裏 AI 這一成果揭示了機器在理解大量複雜材料以及回答現實生活中複雜問題方麵的潛力。
據阿裏方麵介紹,這一技術已經開始大規模應用,例如去年在 Lazada 一次線上促銷活動前, 阿裏 AI 僅僅花了 30 毫秒就學會 25 個在印尼促銷品銷售中的所有規則,並成功應用到聊天機器人中,在活動中回答問題方麵的準確率達到了 96%。
圍繞電商服務、導購及任務助理為核心的智能人機交互產品,在活動,規則,指南等場景中替代人工構建知識,降低人工成本,提升認 知智能能力,為海量的活動規則谘詢提供解答服務。在近年來的雙 11,雙 12 場景及最近的 618 大促中維護效率提升 50%,相比通用方案解決率提升 10%。同時,這一技術也活躍在政務場景如市 ⺠辦事谘詢中,基於浙江省百萬級辦事指南庫,”身份證到哪裏換“這類谘詢從等待人工回複時⻓ 2.5 天提升到了秒級響應。
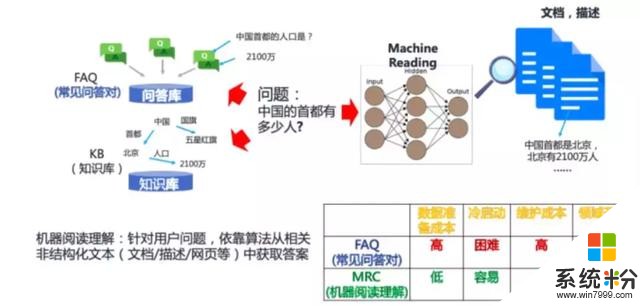
以多文檔開放問答場景的機器閱讀為代表的語言理解技術是自然語言處理的基礎能力之一,在這些基礎能力之上,阿裏巴巴可圍繞該技術構建一係列問答類應用。在產業落地方麵,問答平台及聊天機器人產 品等會伴隨這項技術豐富其自身能力,降低人力成本提高效率;對於消費者來說,智能客服以後可以幫助 消費者在購物時有更好的體驗。
當前,無論是在工業界還是學術界,各方研究團隊都在機器閱讀理解上投入大量精力。未來,除了對話和問答場景,在搜索場景中,搜索引擎將不僅僅是返回用戶相關的鏈接和網⻚,而是通過對互聯網上的海量資源進行閱讀理解,直接得出答案返回給用戶。
附:級聯機器閱讀理解模型詳解
阿裏方麵提供的資料顯示,級聯學習可以通過在不同階段采用不同的特性選擇和樣本篩選策略達到效果和性能的平衡,阿裏巴巴提出的多文檔機器閱讀模型首先利用簡單特征和排序模型過濾掉與問題無關的樣本和段落,並得到一組候選文本,供後續從中提取答案。然後將生成的段落傳遞給基於注意力的深層 MRC 模型(不同於傳統多層 MRC,阿裏巴巴研究團隊在近期公布的 Google BERT 進行了進一步的創新優化,並設計了基於 Enriched BERT 的新 MRC 模型),該模型用於提取單詞級別的實際答案跨度。
為了進一步提升模型效果,該模型使用文檔提取和段落提取作為輔助任務,以快速減少搜索空間的範圍。重要的是,這三個任務在統一的深層 MRC 模型中共享同一個底層語言模型(Enriched BERT),這不僅可以實現粗到細的演繹過程,還可以通過迭代有效地學習更好的模型。
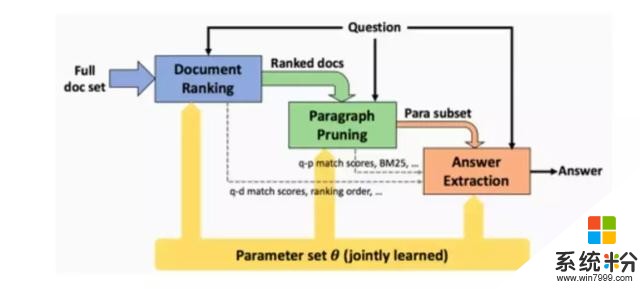
如上圖所示,係統架構由三個核心模塊組成,分別負責文檔檢索、段落檢索和答案提取。對於前兩個功能中的每一個功能,都定義了一個排序函數和一個提取函數。排序函數用於無關內容的過濾(Efficiency)。提取函數將文檔提取和段落提取作為輔助任務並與最終答案提取模塊(機器閱讀理解) 聯合優化,以提高性能(Effectiveness)。所采用的方案與以前的方法相比,關鍵的改進是每個模塊的本地排序功能在成本和複雜性上逐步增加,在整個計算過程中保持效率和有效性競爭因素之間的平衡。
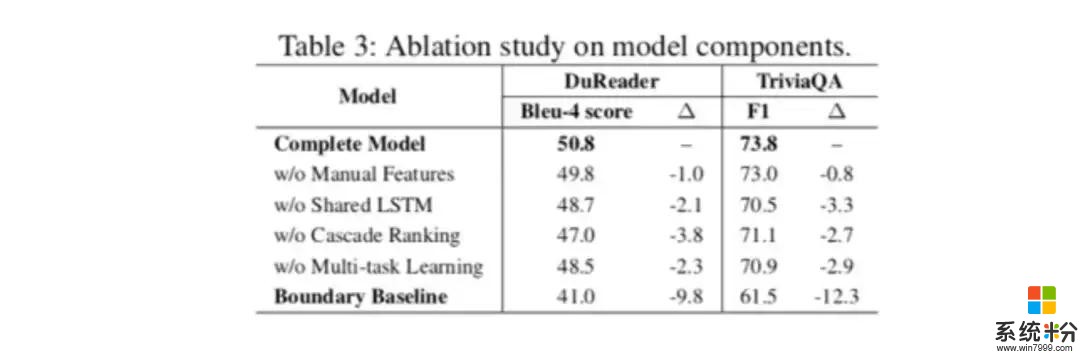
在實驗中(備注:AAAI 2019 的實驗中不包含 Enriched BERT 結果,後續公布),模型開發人員首先用 TriviaQA Web 和 DuReader 基準數據集驗證了在離線測試中的有效性,這兩套數據集通常被用作多文檔 MRC 評測的標準數據集。該基準數據的結果表明,研究人員所提出的模型明顯超過了以前最先進的模型, 在每個包含兩個段落四個文檔集的場景中性能最佳;此外,通過額外的輔助任務在初期排序中消除不相關的文檔和段落,時間成本被證明是可以降低的,可以在不顯著影響最終答案提取效果的情況下完成。
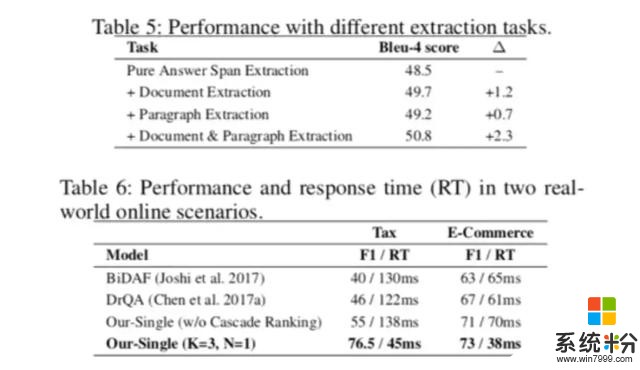
經過驗證,團隊使用阿裏小蜜客服機器人係統進行了在線環境測試,該係統旨在幫助阿裏巴巴集團電子商務平台解決每日約 200 萬名訪問者提出的問題。這些測試表明,該模型能夠以低於 50 微秒的速度滿足請求,同時也提高了有效性標準。
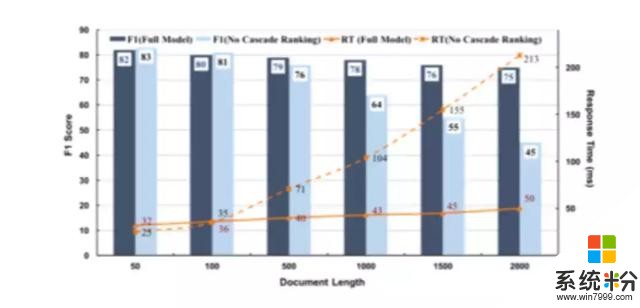
上述結果表明,通過減少無關內容的“噪聲”,該模型可以大大改善現有的最先進在線答疑係統標準, 同時更好地平衡提取過程各個階段效率和有效性。
相關鏈接:
http://m.msmarco.org/leaders.aspx
https://gluebenchmark.com/leaderboard/
(*本文為 AI科技大本營整理文章,轉載請聯係 1092722531)
相關資訊
最新熱門應用

虛擬幣交易app
其它軟件179MB
下載
抹茶交易所官網蘋果
其它軟件30.58MB
下載
歐交易所官網版
其它軟件397.1MB
下載
uniswap交易所蘋果版
其它軟件292.97MB
下載
中安交易所2024官網
其它軟件58.84MB
下載
熱幣全球交易所app邀請碼
其它軟件175.43 MB
下載
比特幣交易網
其它軟件179MB
下載
雷盾交易所app最新版
其它軟件28.18M
下載
火比特交易平台安卓版官網
其它軟件223.89MB
下載
中安交易所官網
其它軟件58.84MB
下載