
選自arXiv
作者:Xindian Ma、Peng Zhang、Shuai Zhang、Nan Duan、Yuexian Hou、Dawei Song、Ming Zhou
機器之心編譯
參與:王子嘉、一鳴、路
引言
近來,預訓練語言模型在很多 NLP 任務中表現良好。特別是基於 Transformer 的預訓練語言模型,它完全基於自注意機機製,在自然語言處理(NLP)各項任務中取得了突破。
然而,在這些模型中,Transformer 的核心結構——多頭注意力機製限製了模型的發展。多頭注意力本身帶來了大量的模型,這可能使訓練中出現問題,而部署模型、導入龐大數量的參數也需要較高的資源支持。因此,壓縮大型神經預訓練語言模型一直是 NLP 研究中的重要問題。
為了解決這一問題,基於張量分解和參數共享的思想,本文提出了多頭線性注意力(Multi-linear attention)和 Block-Term Tensor Decomposition(BTD)。研究人員在語言建模任務及神經翻譯任務上進行了測試,與許多語言建模方法相比,多頭線性注意力機製不僅可以大大壓縮模型參數數量,而且提升了模型的性能。
論文地址:https://arxiv.org/pdf/1906.09777.pdf
Transformer 的張量化
在 Transformer 中,多頭注意力是一個很重要的機製,由於 Query、Key 和 Value 在訓練中會進行多次線性變換,且每個頭的注意力單獨計算,因此產生了大量的冗餘參數。為了更好地壓縮多頭注意力機製中的參數,目前主要有兩個挑戰:
Transformer 的自注意函數是非線性函數,難以壓縮;壓縮後的注意力模型難以直接集成到 Transformer 的編碼器-解碼器框架中。為了解決這些問題,研究人員提出的方法結合了低秩近似和參數共享的思想,因此實現了更高的壓縮比。雖然可以重建 Transformer 中的自注意力機製(縮放點積注意力),但他們並沒有這麼做,而是選擇了分割三階張量(即多線性注意力的輸出),這樣更利於提高實驗準確率。
研究采用的壓縮方法如圖所示:
在圖 2(左)中,研究人員將多頭注意力重建為一個單塊注意力(Single-block attention),采用的 Tucker 分解是一種低秩分解方法。在圖 2(右)中,為了壓縮多頭注意力機製中的參數,研究人員提出了一種基於 Block-Term 張量分解的多線性注意力機製。這種機製在多個塊之間共享因子矩陣(參數共享)。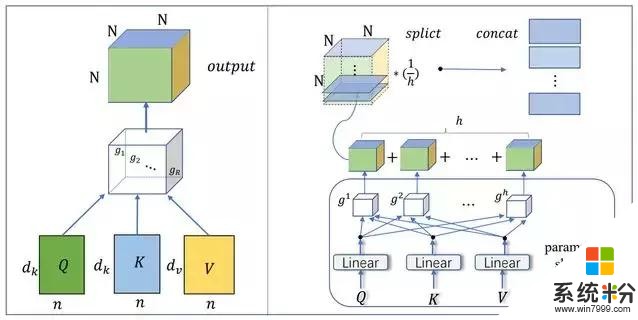
圖 2:模型的壓縮方法:左圖為使用 Tucker 分解構建單塊注意力。右圖則構建了新的注意力機製——多頭線性注意力。
壓縮多頭自注意力
模型壓縮遇到的第一個問題是壓縮多頭自注意力中的參數數量。為了解決這個問題,研究人員首先證明了正交基向量可以線性地表示自注意力機製。然後,通過初始化低秩的核張量,重建新的注意力表示。為了構建多頭注意力機製並壓縮模型,他們使用了 Block-Term 張量分解(BTD),這是一種 CP 分解和 Tucker 分解的結合。Q、K、V 在構建每個三階塊張量的時候共享,因此可以降低許多參數。
圖 2(左)展示了單塊注意機製的結構。首先,Query、Key 和 Value 可以映射成三個因子矩陣 Q、K、V,它們由三組正交基向量組成。然後通過初始化一個可訓練的三階對角張量 G 來構建一個新的注意力機製(單塊注意機製)。在圖 2(左)中,R 是張量的秩,N 是序列的長度,d 是矩陣的維數。利用 Tucker 分解,可以計算出單塊注意力的表達式:
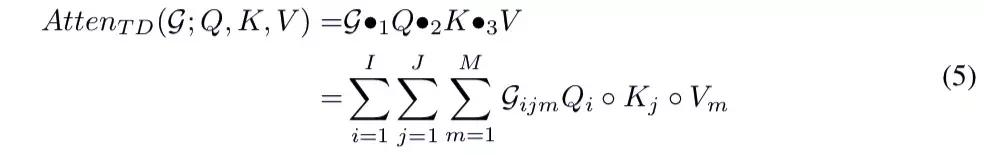
集成多頭線性注意力
為了將壓縮後的單塊注意力張量集成在 Transformer 中,首先,研究人員計算了每個塊張量的平均值。其次,將張量分割為矩陣,然後將這些矩陣級聯,作為 Transformer 中下一層的輸入,這樣就可以集成在 Transformer 的編碼器-解碼器結構中。
在圖 2(右)中,為了完成多頭機製並壓縮多組映射參數的參數,研究人員使用一組線性映射,並共享線性映射的輸出。所學習的線性投影可以將 Query、Key 和 Value 映射到由基向量組成的三個矩陣。在此基礎上,利用 Block-Term 張量分解來建立多頭機製。研究人員將這個模型命名為多線性注意力,可將其表示為:
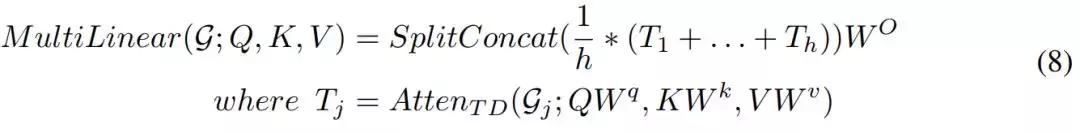
這是一個壓縮模型。在對 Transformer 的多頭注意力進行壓縮後,實現了張量化的 Transformer。多線性注意力可以被融合到 Transformer 中。
實驗結果
為了檢驗在 Transformer 中對多頭注意力所作調整的效果,研究人員在語言建模 (LM) 和神經機器翻譯 (NMT) 兩個任務中進行了實驗。
語言建模
語言建模的任務是預測句子中下一個單詞。研究采用了語言建模的標準設置——根據前一個 token 預測下一個 token。選擇了小型數據集 PTB,中等數據集 WikiText-103 和大型數據集 One-Billion。在預處理中,所有單詞變為小寫。新行被替換為。詞彙表使用的是常見的單詞,未出現的單詞由 [UNK] 來表示。模型的評估基於困惑度(PPL),即每個單詞的平均對數似然。PPL 越低,模型越好。
實驗采用了最新的開源語言建模體係結構 Transformer,並將標準的多頭注意力層替換為多線性注意力層。然後,我們在 PTB、WikiText-103 和 One-Billian 單詞基準數據集上測試不同的模型配置,結果如表 1 和表 2 所示。
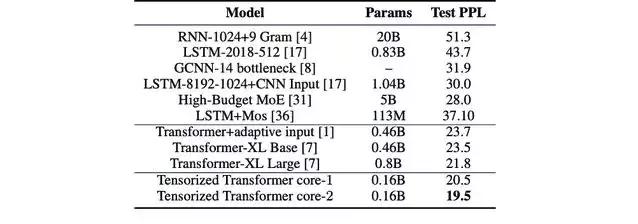
表 1:在 One-Billion 數據集上,模型的參數數量和其困惑度分數。Core-1 表示模型使用了單核張量。而 Core-2 表示使用了兩個塊張量(block term tensor)。
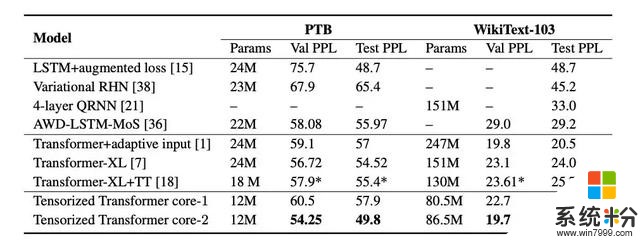
表 2:在 PTB 和 WikiText-103 兩個數據集上,模型的參數數量和其困惑度分數。「-」表示沒有該模型的表現報告。「*」表示為研究人員自己實現的模型結果。
神經機器翻譯
在這個任務中,研究人員在 WMT 2016 英譯德數據集上對 Transformer 模型進行了訓練。在實驗中,使用多頭線性注意力替換了每個注意層。為了評估,使用集束搜索,限定大小為 5,長度懲罰 α= 0.6。結果與 Transformer 進行了比較,如表 3 所示。*表示研究人員自己實現的結果。

表 3:模型參數數量和對應的 BLEU 分數。
相關資訊
最新熱門應用

kbcoin交易所官方版
其它軟件1.93 MB
下載
美幣交易所app蘋果版
其它軟件68.51MB
下載
bkex幣客官網交易所手機版
其它軟件292.97MB
下載
icash交易所
其它軟件223.86MB
下載
比特兒交易所app
其它軟件225.08MB
下載
歐意交易所最新app官網版
其它軟件397.1MB
下載
bnb交易所安卓版
其它軟件179.15 MB
下載
熱幣交易所app官方安卓
其它軟件287.27 MB
下載
芝麻app交易所
其它軟件223.89MB
下載
dash交易所手機版
其它軟件27.87M
下載