

演講者 | 趙晟、張鵬
整理 | 伍杏玲
出品 | CSDN(ID:CSDNnews)
【CSDN 編者按】9 月 7 日,在CSDN主辦的「AI ProCon 2019」上,微軟(亞洲)互聯網工程院人工智能語音團隊首席研發總監趙晟、微軟(亞洲)互聯網工程院 Office 365資深產品經理,Office 小程序負責人張鵬共同發表《微軟語音AI與微軟聽聽小程序實踐》的主題演講,分享微軟人工智能語音的技術以及微軟聽聽小程序的落地實踐。
詳情如何?我們一起來看看。
以下為演講內容:
趙晟:
小程序是現在移動開發的新生態、新趨勢。語音AI技術跟移動開發是非常有關係的。大家平時開車時不方便用手輸入,可以用語音輸入,開車時想聽一些東西,完全可以用文字轉語音的技術去聽這些內容。基於這些考慮,微軟語音AI和微軟聽聽小程序合作做了些嚐試,今天給大家分享這裏麵的故事。

趙晟

微軟語音AI的技術突破
微軟在30多年前開辦微軟研究院時,已開始投入大量的人力物力在語音和語言上。近幾年來,微軟在語音識別上首先取得突破,在2016年,語音識別的準確度已達到跟人相似的水平。
2018年,在中英機器翻譯上和人類做比較,發現機器翻譯的質量跟專業翻譯人員的結果完全可以相媲美。
2018年9月,微軟首先發布了基於神經網絡的語音合成產品服務,它與人聲的自然度得分的比例達到98.6%,也就是說非常接近人聲。
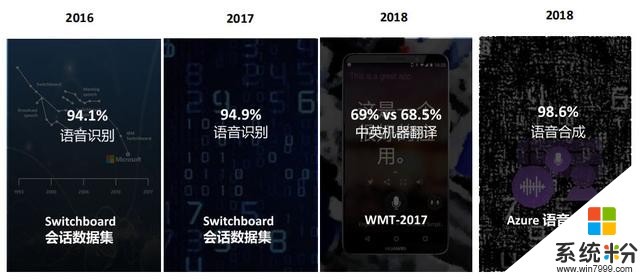
語音識別之路
微軟在語音識別的具體突破有哪些?
語音識別主要核心指標是詞錯誤率,就是詞識別錯誤占多少比例。在SwitchBoard會話數據集上,語音識別錯誤率開始非常高,根本不能用,到2016年,微軟取得了突破,達到5.9%的錯誤率,2017年進一步降低到5.1%的錯誤率,這個錯誤率跟專業人員轉寫錄音的錯誤率是相當的。
大家聽聽這個數據集的例子:電話上有兩個人在交流,語音具有不連續性、噪音、口音,所以識別難度對機器來講是非常大的,微軟使用10個神經網絡技術,比如:CNN、ResNet、VGG等,多模型輸出打分、多係統融合,得到了這個了不起的突破。
機器翻譯的裏程碑
從1980年的傳統機器翻譯,到1990年的統計機器翻譯,再到2010年,深度學習機器翻譯技術開始興起。2018年,微軟首度提出一個任務,把機器跟人在中英新聞翻譯上做比較,讓專業翻譯人員和機器翻譯同樣的句子,翻譯後請懂雙語的老師和學生去對翻譯結果用0-100分進行打分。
可以看到微軟的Human Parity機器翻譯係統已經超過或者接近專業人員的翻譯水平。它的突破用到了新技術比如對偶學習,用大量無標注數據提高現有的翻譯係統。還有推敲網絡,先有一個初始翻譯,再用另外一個網絡進行再一次的修正,同時運用多係統融合技術,最終達到這個突破性的結果。
語音合成技術
我們再看看語音合成技術,文字轉語音這個技術也是非常悠久的語音AI技術。
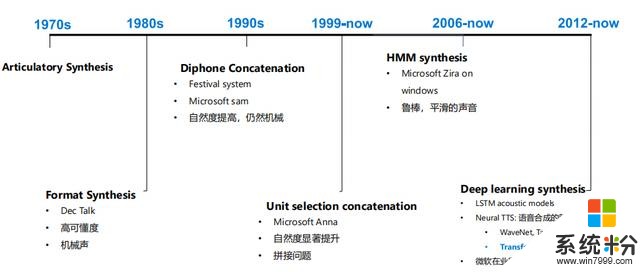
最開始是基於人的發音原理的合成器,然後90 年代用拚接的方法,把一句話分成很小的單元,然後進行拚接,一開始的拚接是小語料庫,自然度一般。在1999年左右,出現基於大語料庫的拚接,這時需要收集到成千上萬的句子,把它們切分開來,用一種選擇策略去選擇最合適的單元拚接在一起,自然度顯著提升,但是帶來新的問題,比如有些拚接不平滑。
2006年左右,基於HMM模型的合成技術興起,它的好處是非常平滑,但是也帶來負作用,就是聲音過於平滑,讓人聽出來覺得不夠具有表現力。深度學習的興起在合成領域也得到了應用,最近兩三年推出的神經網絡TTS,是語音合成技術的突破。穀歌提出來Tacotron, WaveNet這些模型,把語音自然度提升新的水平。
微軟在2018年,2019年提出了Transformer TTS、Fast Speech等高自然度神經網絡TTS模型,並在2018年9月首度推出產品化接近人聲的端到端Neural TTS。
Neural TTS模型
為什麼Neural TTS模型可以接近人聲?
傳統的TTS是一個複雜的流程,每一步都要進行單獨優化,有些模塊需要經驗規則,人工優化權重等等。神經網絡的TTS是將合成流程簡化了,我們可以看到它基本就三段,有一個前端文本分析,一個聲學模型,一個Neural Vocoder聲碼器。神經網絡的聲碼器可以非常接近人的音質。
采用最新的基於注意力的聲學模型去進行建模韻律,更加接近人聲的韻律。兩者疊加起來,就可以到更符合人的韻律和音質的高質量合成語音。當然,帶來的負作用是計算量非常大。
神經網絡TTS的架構非常具有可擴展性,各家都提出不同的聲學和聲碼器模型,有各自的特點,有的計算量大一點,有的計算量小一點,質量也有所不同。
Neural TTS還有一個特點是遷移學習,我們可以提取條件參數,對合成進行控製,比如我們可以先訓練一個多說話人的基礎模型,使用幾十小時到上千小時數據訓練得到一個模型。有了基礎模型以後可以做很多有意思的事情,比如訓練我自己的聲音,或者生成有情感的、多風格的、跨語言的聲音,這些都可以做到。

語音服務概覽
前麵講了語音的新技術突破,可能有人就會問,有這麼多新技術,怎麼在產品裏用它?我給大家介紹語音服務有哪些功能供大家使用。
微軟的語音服務基本都在微軟Azure這個平台上,提供語音轉文字、文字翻譯等標準服務。

Azure語音雲端服務
語音轉文字有很多功能,如實時識別文字、一個人說話、多人對話、會議場景。一個典型場景是大家開會後想看會議內容,可用語音服務把語音轉成文字,並且做一些自動處理的摘要,這樣可快捷地查看會議內容。
目前跟人類接近的文字翻譯係統已上線,神經網絡模型已更新,翻譯質量大幅度提升。
文字轉語音我們提供神經網絡 TTS、4種語言、5個聲音。這些服務都可以用Rest和WebSocket SDK調用。
我們還提供語音到語音的翻譯係統,比如翻譯機場景,把中文語音輸入進去,翻譯成英文,得到語音流,可以直接播放,不用再配置其他服務,簡化開發步驟。這些服務都可以在以下網址訪問使用。
https://azure.microsoft.com/en-us/services/cognitive-services/speech-services/
雲端模型定製服務
前麵我提到的API都是標準模型,所謂標準模型就是微軟幾十年收集的數據做的大模型,大模型適用於大量通用的場景。但是AI有一個特點是對於不同場景相關的數據做一些自適應,可達到更好的效果。
典型的例子是有些公司裏麵有自己的硬件采集語音、有自己的關鍵詞,如果有這些場景數據,可以大幅度提高語音識別準確率。我們在語音識別、翻譯、合成模型上都提供定製功能,提供給各位開發者一起創建生態係統,你可以把數據放進去,打造成行業的模型,提供給客戶使用。
模型定製地址:https://speech.microsoft.com/
Edge 端的語音容器
前麵提到基於雲端的語音服務,雲端模型定製,還有一個很重要的場景是需要把AI放到離線或者私有雲裏麵,這就是常說的Edge計算。因為這些端的計算力得到很大提高,可以跑起來複雜的模型。
包括手機端的Tensorflow都是類似的利用Edge部署的想法。我們語音服務在Edge有一個部署方案,它是基於Docker的容器,這樣帶來很多好處,比如安全可靠、延遲很小,充分利用現有硬件,接口和雲端化部署保持一致,使用起來非常方便。
比如呼叫中心裏有大量的客服語音對話,對此進行分析就可以了解服務的滿意度。我們已形成了解決方案:在呼叫中心裏定製模型,定製後,用於大批量處理錄音,然後使用自然語言處理進行智能分析。在國內我們聯合了聯合利華、中國移動利用容器化的語音服務去完成這些服務。
容器可以在此申請使用:https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-container-howto
Unified Speech SDK
在客戶端SAPI、SpeechFX是Windows係統自帶的傳統開發SDK。我們現在提出了Unified SDK,支持訪問雲端的語音識別、語音合成、語言翻譯等語音服務。這個SDK也支持容器化的語音服務和離線語音引擎,它是真正跨平台的,支持Windows、Linux、安卓、iOS、瀏覽器平台。SDK采用跨平台架構,提供有各種語言的綁定,中間有統一的C API,底層有跨平台的庫,可以快速支持跨平台的遷移。
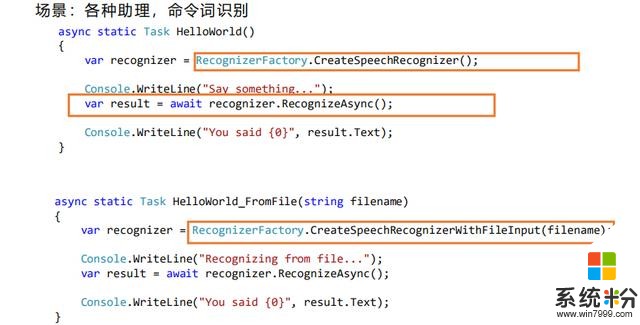
短語音識別代碼
簡單看幾個語音識別例子,各種音箱助理要做識別,這是短句語音識別場景,你可以創建一個語音識別對象,然後異步開始識別,它是從聲卡采集數據進行識別,然後把結果反饋給你。
SDK免費下載使用:https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-sdk

語音合成平台
語音合成平台的使命是讓每個人和組織都有喜歡的數字化聲音。這個語音合成平台是既給內部客戶使用,也給外部客戶使用,內部客戶比如像微軟的語音助理用的就是同樣這個語音合成平台。我們在不斷迭代這個平台,在18個數據中心裏都有部署,真正達到全球化的部署,出海企業可以使用我們國外的數據中心。
接下來看看基於神經網絡TTS的多種風格語音。為什麼要有多風格的語音?因為合成一段語音的話,文字和語音要有一定的匹配,讀新聞時需要正式的聲音,機器人回複的時候需要考慮上下文需要,采取帶有情感的回複。我們提供了風格化的聲音供大家使用,通過輸入的SSML express-as標記進行風格控製,使用起來是非常容易的。
中文上我們也正在開發新的風格,比如有親和力的助理場景,客服場景裏,客服機器人的語氣應該是比較熱心的。有時機器人有需要一些技能,我們這個曉曉也會唱歌。另外新聞場景,需要比較正式的語氣來讀新聞。讀微信公眾號的文章不用那麼正式,但是也要相對要規範。情感故事場景,大家晚上睡覺前可以聽聽心靈雞湯等等。聲音可以千變萬化,我們根據用戶的需求去定製風格,同時也有不同的音色,比如男生、老年人聲音、小孩聲音,這些都可以定製。

語音合成API調用
這是語音合成API調用,創建一個合成器對象,你把文字送給它,它就可以開始合成了,這是合成到聲卡。不同語言也非常類似,學習起來也非常容易。
調用API需要配置語言,我們有很多種語言,所以需要配置一下語言參數。不同的音色,聲音也可以首先配置。輸出格式,把語音輸出到MP3壓縮,也可以通過屬性配置。

合成到文件保存,有時開發服務時需要把音頻合成到一個流裏然後轉發到其他地方,那麼就創建一個PullStream,後麵的合成代碼是一樣的,可以像文件一樣去讀取這個合成的數據。還有一個PushStream,相當於回調的方式,不同的開發人員有不同的喜好,我們提供不同的API,方便大家使用。回調時的數據是通過回調方法來進行處理。
語音合成API也提供一些元數據,比如詞邊界,可以告訴你讀到哪一個單詞了,此外有些場景需要做口形匹配。這時注冊一個事件,你可以得到這些元數據,這個功能在微軟的Edge瀏覽器最新發布的新版本裏已經用到了,朗讀時文字高亮顯示,供閱讀者了解當前的進度。

語音助手合成
我們來看看語音助手的典型解決方案,典型場景有音箱、客服機器人、互聯網車載語音、小程序集成。
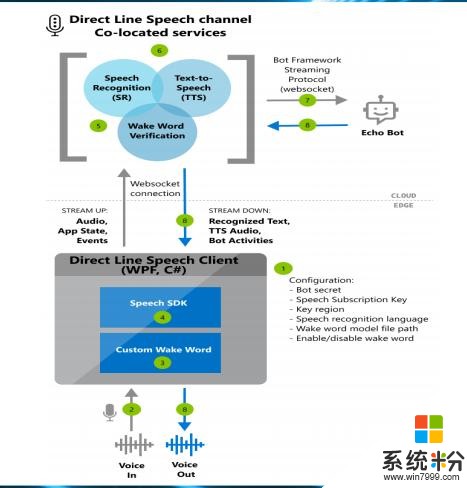
架構圖
這是我們推薦的解決方案或者架構:客戶端可以用語音激活,用自定義的喚醒詞,比如“你好,小娜”,首先把服務喚醒,你可以采集數據通過SDK送到雲端,雲端有喚醒詞校驗,再確認一下這個喚醒是不是真的對,降低誤觸發,然後對音頻流進行識別,識別出的文字送給機器人的服務。
這是實現鬆耦合的好辦法,類似機器人的服務都是自然語言文字進入、文字輸出,所有這樣的服務可以注冊到我們這個框架裏來。回複文字之後回到語音服務,進行語音合成,合成的語音可以通過流式返回客戶端通過SDK播放,這是整個調用流程。這個架構的優點是把雲端語音服務和喚醒詞放在一起,可以減少客戶端調雲端的次數。全雙工對話也可以用類似方法實現,連接的協議是WebSocket。
更多信息可參見: https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/tutorial-voice-enable-your-bot-speech-sdk
在微信小程序裏可以用類似這樣的架構去做,我們在GitHub上提供了示例:
https://github.com/Azure-Samples/Cognitive-Speech-TTS/tree/master/TranslatorDemo

語音內容生產
當前現代快節奏的生活使得信息獲取變得碎片化和多任務化,我們常常遇到一些痛點:傳統的有聲內容製作主要靠聲優的錄音;大量的文本內容正在等待有聲化;有聲內容生成受限於人員,時間,環境等因素,不能最大化產能。
那麼如何提高人們的閱讀效率呢?
一種很好的方式是通過聽的方式消化這些信息,開車時、睡覺前都可以聽一聽,傳統方案由人來讀,這非常受到限製。有了基於神經網絡的TTS,我們在想能不能提供效率更高的方案。
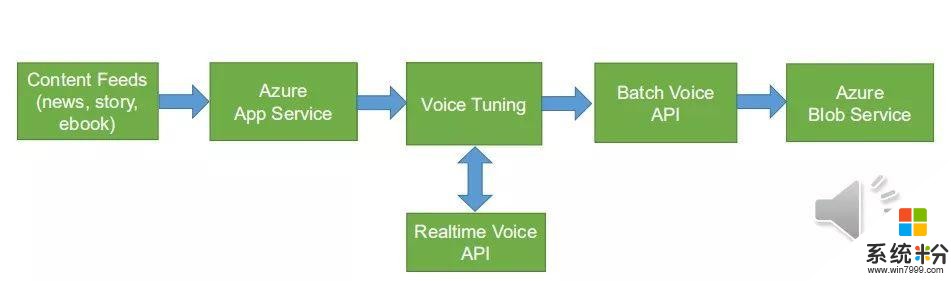
這個方案是這樣工作的,各種信息流可以用雲服務把它整理,送到語音調優服務,你可以選擇調一下比如多音字,批處理合成API把調好的SSML合成為音頻放在存儲服務裏,供你的應用去使用。
舉一個電子書例子,這個電子書聽起來更生動一點,還有角色的變化。前麵說到了調音工具,TTS輸入或者語音合成輸入是SSML格式。我們提供界麵工具可以可視化去調讀音、停頓、背景音樂,一定程度上可以用它調出完全接近錄音的效果。

定製語音
聲音是一個品牌,每個人的聲音都是自己的品牌,我們支持讓每個企業都能定製自己的聲音。定製語音的類型有兩類:
1、自助服務開發人員通過網頁或API操作、訓練、部署聲音,自助完成,麵向個人開發者。支持三類模型的服務:
(1)基礎模型:30-500句語音,比較相似,高可懂度。
(2)標準模型:3000-6000句語音,自然度比較高,接近Windows上標準模型。
(3)高質量模型:6000-8000句語音,自然度非常高,接近JessaRUS。
2、全包服務
全流程定製語音,專家工程師把控最高質量,也支持基於神經網絡的定製,300句可以做到以前6000-8000句的效果。當然,對於神經網絡的定製要非常小心,我們希望AI的技術不要被濫用,太像了之後人們會擔心自己的聲音被別人做了一個TTS,去外麵打騙人的電話等等。所以需要有很嚴格的流程,通過客戶同意才能使用。目前通過商務合作模式進行神經網絡TTS定製,保證技術不被濫用。
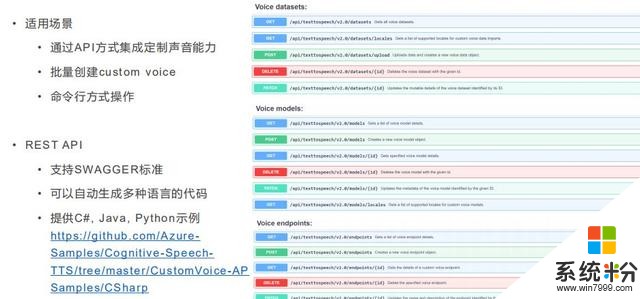
自主服務界麵接口裏,可上傳所有數據,我們自動進行處理,比如對讀音進行檢測,如果發音不標準的話訓練出來的聲音也不標準。數據較好的話可提交訓練,後台會起一個訓練流程在GPU去訓練,訓練之後試聽效果,部署後可通過代碼調用或者在網頁上輸文字實時測試。
模型定製也可調用API,這個API是Rest接口,在微信小程序可以調用,也可在後台調用。代碼支持SWAGGER標準,可以自動生成多種語言代碼。我們提供了管理數據的API,對模型進行管理的API。
做一個好聲音是有技術門檻的,首先要了解你的場景需要什麼樣的風格、需要什麼樣的音色,去選擇合適的風格,然後錄音文本選擇通用文本或者領域相關文本。
錄音也是個技術活,需要盡可能安靜,不要有噪音,保持錄音風格,數據越好出來的質量越高。模型訓練完成之後可以部署到雲端或者容器,可以非常靈活的部署在各個地方。微軟語音AI技術在微信小程序上有不錯的實踐,下麵由張鵬分享聽聽小程序在AI的實踐。

為什麼是語音 AI +小程序?

張鵬
張鵬:
Office 365是一套基於雲平台的服務解決方案,除了大家熟悉的Office編輯工具服務外,還有郵件,社交,會話以及可視化數據與報告等,這些共同構成了一套服務,這套服務我們稱之為Office 365,我們希望把Office 365帶到更多中國用戶使用習慣中去,第一個看重的是微信。
我們為什麼要在微信裏做?
有兩個主要考慮的因素:
第一,微信是月活超過11億的產品,這是任何跨國公司產品進入中國以及本土創新都必須要研究的,微信哪些功能滿足了用戶需求,哪些功能沒有滿足用戶需求,因此Office 365要在中國取得成功,滿足微信用戶的對文檔協作的需求是我們必須要做的事情。。
第二,微信沉澱了極其穩定的社交關係,基於這些社交關係可以看到你的通訊錄裏、各種群裏已經不單是家人和朋友,看看我們微信的各種群,更多的是你的同事、客戶以及上下遊合作夥伴,也就是說很多群是因為工作而產生的,因此在微信裏就有大量的文檔在流轉,我們如何讓這些文檔在微信生態裏可以更高效的被創造出來,可以被安全的被管理,可以更順暢且高效的傳遞,這是我們想在中國探索的一個方向。
第三,小程序2017年1月份誕生,市場上對小程序有各種解讀,有看好的,有不看好的,我覺得任何定義現在下都為時過早。而我們看到的是小程序正在或者將要解決信息孤島的問題,各個App之間信息不通的問題。
Office有同樣的問題,很多文檔內容是留在大家的PC裏或者用戶各種雲盤裏,這些信息並沒有很高效的被協作起來,沒有有效的途徑把有價值的內容做分享。我們認為微信小程序未來正是解決這個問題的解決方案。
基於這幾點,我們2018年投入到小程序裏。
今天分享的小程序叫“微軟聽聽文檔”,“微軟聽聽文檔”探索的第一個問題是PPT在移動端應該是什麼樣子的?如何將信息更好與人協作。
我們有很多群,有很多文檔在流轉,然後這些文檔在群裏是以靜態的形式在流轉,很多情況下用戶都是從PC端拉一個PPT扔到群裏就完了,這種PPT其實是靜態的Word文檔。
如果將PPT下一個定義的話,突出它的主要功能就是怎樣讓大家演講時更有力,提升演講時的演示效果,這是我們移動端的目的。因此,我們打造了“微軟聽聽文檔”。
我們通過在移動端快速地給每一頁文檔做錄音,快速發布,通過微信固有的社交關係去傳播、發布。每頁PPT下麵除了有聲音外,還有各種社交屬性:傳播、、發朋友圈、進群、點讚、打賞,這是我們認為PPT在移動端應該有的樣子。更重要的是有人的聲音,也就是演講者的參與。
今天AI大會上我觀察到有很多人會拍照發朋友圈、發到群裏,這也是一種內容的分享方式,但這種分享方式並不很高效,為什麼?
因為這種分享方式裏缺少了最重要的因素,就是演講者、創作者到底在PPT背後傳遞什麼觀點,通過幾張圖片是很難傳遞出來的,這是我們要打造這個產品的目的。

微軟聽聽小程序
我們做這個探索時,關注點有:
第一,創建。我們可以給每個文檔做錄音,背景音樂可以通過微軟AI技術去學習文字和圖片,自動配背景音樂,不用大家主動去選。
第二,PPT有設計內容,Office365有AI設計靈感,未來在移動端也可以幫大家從手機相冊去選擇圖片去製作演講時,圖片可以自動用設計功能去裁剪、排版,達到更好的效果。
第三,AutoSpeech,大家在移動端錄音時,很多人不喜歡自己的聲音,覺得自己的聲音不好聽,很多人基於環境的限製並不方便錄音,我們基於深度神經網絡可以將聲音完美的匹配文字。
第四,Article聽聽文檔,如果大家在行進路上或者不太方便看文字的情況下,簡單的把公眾號URL鏈接拷貝到裏麵,可以用幾十秒時間迅速製作出來一種可以看、可以聽的文本,是一種新的形式展示給大家,我們有真實企業案例就是這樣用的。
在聽的方麵有哪些和AI結合?讓聽者可以更沉浸式的身臨其境的去聽人的分享。
1、引入字幕,字幕對輔助閱讀很重要,有時大家聽講時開小差就跟不上了,字幕在這裏起到非常關鍵的作用,通過微軟的聲音轉文字,以字幕的形式轉出來。
2、社交,點讚、轉發等等。
3、PPT動畫,把視頻播放的東西引入進來,給大家更豐富的表現方式。
以下是語音文檔的創作過程:
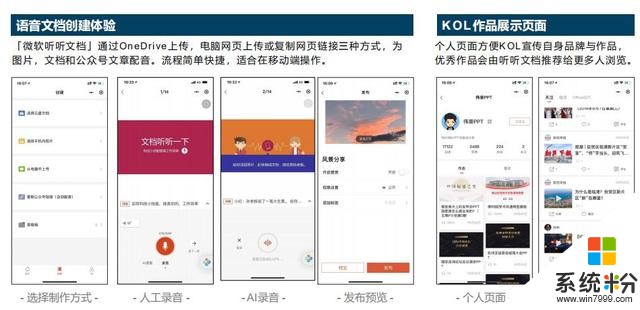
第一步,選擇製作方式。
擁有微軟帳戶後可以選擇文件,可以從電腦端拖一個文件裏進來,也可以從手機相冊裏選,選擇之後進入錄音。
第二步,人工錄音或者AI錄音。
第三步,發布。
可以選擇權限設置,是隻給微信好友看,還是發布給整個互聯網的人看,還是隻給自己看,包括開啟讚賞,如果覺得自己的內容有價值,期望別人打賞的話也可以開啟。
第四步,查看個人頁麵,關注推薦。
發布之後你的作品在作品集,可以知道有多少用戶關注你,知道每個分享有多少人去看去聽,也方便你自己去管理你自己的內容,也可以讓別人找到你去分享。
下麵舉一個真實例子,新民晚報。他們之前有一個問題,每天早上6點,編輯會在1小時內編輯一天24小時的新聞,7點鍾有一個內審,審核通過以後,7點半就在公眾號發布。
這個過程中要反複修改,不可能有人給公眾號錄音或者去修改,。他們現在利用以上的方式可以很快捷的嵌入小程序到公眾號,我們這個小程序的速度非常快,大概十幾秒的樣子。AI的效率在這個場景中得到非常大的發揮和落地。

微軟Office微信小程序布局
未來,微軟Office微信小程序布局本地化策略有三個方向:信息輸入;信息管理;信息輸出。
文檔怎麼被創造出來,怎麼被管理,怎麼輸出協作。這三個方向是我們想去探索的。
在我看來,什麼樣的小程序能夠生命力很強?我們做了很多功能,但是發現反而讓用戶更多時間耗在這裏,這樣工具類的小程序時間長了,慢慢大家就不會用了,因為發現代價很大。所以從生產力小程序角度總結,隻要真正能幫助用戶節省時間、提高效率的生產力小程序都會有更好的生命力繼續傳播下去。最終讓用戶收益才是一切商業邏輯的起點。
大家可以在微信搜索“微軟聽聽文檔”,體驗一下。
嘉賓簡介:
趙晟 ,微軟(亞洲)互聯網工程院 人工智能語音團隊首席研發總監。目前負責微軟Azure語音服務的產品研發工作, 所開發的語音技術服務於微軟Office、Windows、 Azure認知服務,小冰小娜以及廣大的第三方開發者。曾擔任微軟亞洲研究院研究員,微軟小娜資深研發經理。長期從事語音和語言方麵的技術開發,包括語音合成,自然語言處理,語音識別等等,所負責的多語言合成項目也曾經獲得微軟中國傑出工程獎。
張鵬,微軟(亞洲)互聯網工程院 Office 365資深產品經理,Office 小程序負責人 。2013年加入微軟MSN,承擔MSN和必應搜索等產品設計和市場推廣工作。2016年開始至今,負責Office 365在中國創新產品開發,成功發布officeplus.cn,微軟AI識圖,聽聽文檔等產品發布。
【END】
相關資訊
最新熱門應用

oke歐藝app官方
其它軟件397.1MB
下載
比特國際資產交易所app
其它軟件163.20M
下載
環球交易所app
其它軟件47.40MB
下載
比安交易所官網app
其它軟件179MB
下載
熱幣網交易所app官網版安卓
其它軟件287.27 MB
下載
必安交易所app官網版安卓手機
其它軟件179MB
下載
龍網交易所安卓版
其它軟件53.33M
下載
雲幣網交易所蘋果app
其它軟件14.25MB
下載
幣u交易所鏈接
其它軟件150.34M
下載
唯客交易所安卓版
其它軟件59.95MB
下載