
受此啟發,Microsoft研究人員開發了一個框架—— imbuing reinforcement learning,該框架包括一種通過愉悅之類的動機來激勵主體的機製。
該框架包括:
該框架是一種人工智能訓練技術,它利用獎勵來激勵係統朝著目標前進,具有積極的影響。他們認為,這可能會對收集與學習相關的重要經驗方麵很有用。
正如研究人員所解釋的那樣,強化學習通常是通過在達到特定目標時提供政策特定的獎勵來進行
有問題的是,外部獎勵的範圍很窄,難以定義,而內部獎勵是獨立於任務的,可以快速表明是成功還是失敗。
為了追求一種內在的策略,研究人員開發了一個由人類情感所驅動的獎勵係統——采用人類的微笑作為正麵獎勵。
用模擬獎勵的計算機視覺係統以及使用數據解決多項任務的另一個係統,它將人類的笑容視為一種積極的情感。
該框架鼓勵代理在不陷入危險的情況下可以探索虛擬或現實環境,其優點是對任何特定的機器智能應用程序均不可知。
積極的內在獎勵可以預測人類在探索過程中的微笑反應,而順序決策框架則可以學習通用政策。
至於積極的內在情感模型,它會改變動作選擇,從而偏向於提供更好的內在獎勵的動作,最後一個組件使用代理在探索期間收集的數據來構建視覺識別和理解任務的表示。

為了測試這個框架,研究人員收集了5名受試者的數據,這些受試者的任務是用車輛探索一個數字三維迷宮,並用同步鏡頭記錄每個人臉上的表情。參與者僅被告知探索環境,受試過程中由開源算法計算和記錄他們的微笑反應。
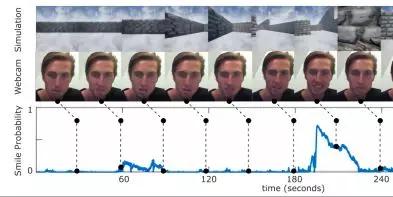
在一次駕駛過程中,微笑反應持續了6分鍾(360秒)。從環境和網絡攝像頭視頻幀顯示作為參考。
基於情感的內在動機模型是使用受試者的數據進行訓練的,其中來自車輛儀表板的圖像幀作為輸入,而微笑概率作為輸出。
實驗結果表明,使用笑容作獎勵機製的學習過程可以帶來更好的效果。與基線相比,研究人員的內在獎勵政策在迷宮中的覆蓋麵積增加了46%,與障礙物的碰撞時間減少了29%。
研究人員表示,他們並不是嚐試模仿人類的情感,而是要證明使用情感作為標記的訓練,可以提升運算效果。
這種受情感機製引發內在獎勵的學習框架,可以更有效提升覆蓋度和減少失敗次數,獲得的經驗可以有助解決不同應用例如深度估算、場景分割以及草圖變圖像等等。
原文鏈接:
https://venturebeat.com/2019/12/27/microsoft-proposes-ai-that-improves-when-you-smile/
視頻點擊預測大賽火熱進行中
3萬元獎金、證書、實習、就業機會已準備就位,快叫上小夥伴一起來組隊參賽吧。
賽題:希望參賽者通過已有的用戶信息、視頻信息以及他們是否觀看過某些視頻,來預測我們推薦給這些用戶的視頻對方是否會觀看。
個人、高等院校、科研單位、互聯網企業、創業團隊、學生社團等人員均可報名。
報名及組隊時間:即日起至2020年2月1日
報名入口:
http://m.turingtopia.com/competitionnew/detail/e4880352b6ef4f9f8f28e8f98498dbc4/sketch
相關資訊
最新熱門應用

coin100交易所鏈接
其它軟件159.09M
下載
歐意交易平台官網蘋果版
其它軟件397.1MB
下載
歐意交易平台app蘋果官網
其它軟件397.1MB
下載
歐意交易所app官方安卓手機版網易郵箱
其它軟件397.1MB
下載
熱幣網交易所app官網版蘋果手機
其它軟件50.42MB
下載
深幣交易所蘋果app
其它軟件223.89MB
下載
中幣交易所官網最新版安卓
其它軟件288.1 MB
下載
交易所appbcone
其它軟件225.08MB
下載
pkex交易所軟件官方app2024安卓版
其它軟件273.24MB
下載
bafeex交易所最新版
其它軟件28.5MB
下載