

作者 | Corby Rosset
譯者 | 劉暢 責編 | Just
出品 | AI科技大本營(ID:rgznai100)
BERT和GPT-2之類的深度學習語言模型(language model, LM)有數十億的參數,互聯網上幾乎所有的文本都已經參與了該模型的訓練,它們提升了幾乎所有自然語言處理(NLP)任務的技術水平,包括問題解答、對話機器人和文檔理解等。
更好的自然語言生成模型可以在多種應用程序中實現自如的轉化,例如協助作者撰寫內容,彙總一長段文本來節省時間,或改善自動客服助理的用戶體驗。
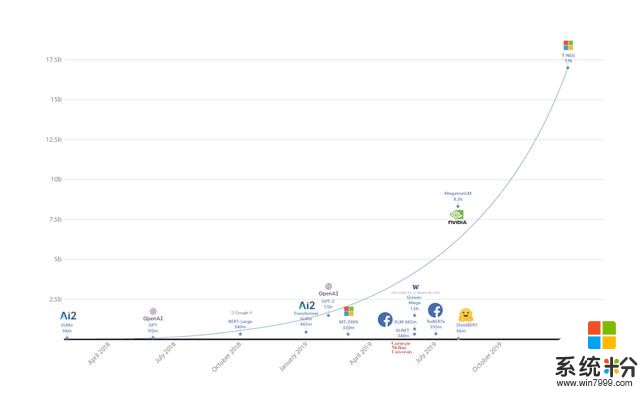
基於使用更大自然語言模型可以帶來更好結果的趨勢,微軟推出了Turing自然語言生成(T-NLG)模型,這是有史以來規模最大的模型,其參數有170億,在各種語言模型任務的基準上均優於最新技術,並且在應用於許多實際任務(包括概括和問題解答)時也很出色。
這項工作得益於在DeepSpeed庫(與PyTorch兼容)的ZeRO優化器方麵的突破。
我們正在向學術界的一小部分用戶發布T-NLG的演示視頻,包括生成自由格式,問題解答和概要功能,以進行初步測試和反饋。

T-NLG:大型生成語言模型的優勢
T-NLG是一個基於Transformer的生成語言模型,這意味著它可以生成單詞來完成開放式的文本任務。除了補充未完成的句子外,它還可以生成問題的答案和文檔的摘要。
T-NLG之類的生成模型對於NLP任務很重要,因為我們的目標是在任何情況下都盡可能與人類直接,準確和流暢地問答。以前,問題解答和概要係統是依賴於從文檔中提取現有內容,把這些內容用作備用答案或摘要,但它們通常看起來不自然或不連貫。借助T-NLG模型,就可以很自然的總結或回答有關個人文檔或電子郵件主題的問題。
我們已經觀察到,模型越大,預訓練數據需要越多樣化和全麵,在泛華到其它任務時也會表現得更好。因此,我們認為訓練大型集中式多任務模型並在眾多任務中共享其功能比單獨為每個任務訓練新模型更為有效。

訓練T-NLG:硬件和軟件的突破
任何超過13億參數的模型都無法裝入單張GPU(甚至一個具有32GB內存的電腦),因此該模型本身必須在多個GPU之間並行化或分解。我們利用了幾項硬件和軟件的突破來訓練T-NLG:
1.我們利用NVIDIADGX-2硬件設置和InfiniBand連接,使GPU之間的通信比以前更快。
2. 在NVIDIAMegatron-LM框架上,我們使用張量切片技術在四張NVIDIAV100 GPU上分割模型。
3. DeepSpeed with ZeRO庫使我們可以降低模型並行度(從16降低到4),將每個節點的批處理大小增加4倍,並將訓練時間減少3倍。DeepSpeed可以使用更少的GPU訓練更大的模型,從而提高效率,並且僅使用256個NVIDIA GPU就可以實現512 batchsize的訓練,而單獨使用Megatron-LM則需要1024個NVIDIA GPU。DeepSpeed與PyTorch兼容。
最終的T-NLG模型具有78個Transformer層,其隱藏層的節點大小為4256,並包含28個注意力頭。為了使結果可與Megatron-LM相媲美,我們使用了與Megatron-LM相同的超參數對模型進行了預訓練,
我們還比較了預訓練T-NLG模型在標準語言任務(例如WikiText-103(越低越好)和LAMBADA下一個單詞預測準確性(越高越好))上的性能。下表顯示,我們在LAMBADA和WikiText-103上都達到了最新的技術水平。Megatron-LM是NVIDIA Megatron模型公開發布的結果。
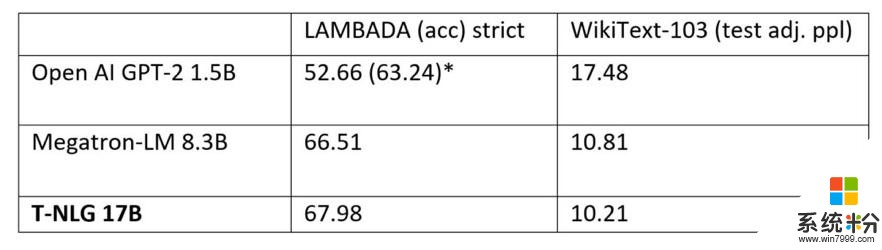
Open AI使用了額外的處理(停用詞過濾)以實現比單獨實現模型更高的數量。Megatron和T-NLG均未使用這種停用詞過濾技術。
下麵圖1顯示了與Megatron-LM相比,T-NLG在驗證perplexity方麵的表現。
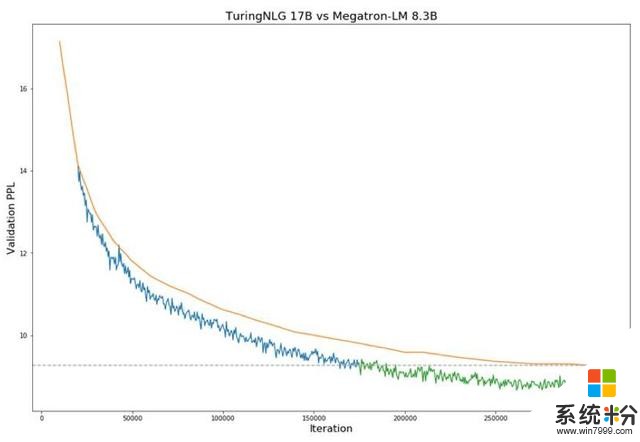
訓練期間Megatron-8B參數模型(橙色線)與T-NLG 17B模型在驗證困惑度方麵的比較(藍線和綠線)。虛線表示當前SOTA技術模型達到的最低驗證損失。圖中從藍色到綠色的過渡表示T-NLG在性能上超過了SOTA水平。

直接問答和Zero-shot提問功能
許多網絡搜索用戶習慣於在問問題時看到答案直接顯示在頁麵的頂部。這些頁麵大多數會在其所屬段落的上下文中顯示一個答案句子。我們的目標是通過直接回答他們的問題來更明確地滿足用戶的信息需求。例如,大多數搜索引擎在顯示全文時會突出顯示名稱,如“Tristan Prettyman”(請參見下麵的示例)

相反,T-NLG將直接用完整的句子回答問題。在Web搜索之外,此功能更為重要,例如,當用戶詢問有關個人數據的問題(例如電子郵件或Word文檔)時,此功能可使AI助手智能響應。
該模型還能夠實現“zeroshot”問題解答,這意味著無需上下文即可進行回答。對於下麵的示例,沒有給出模型的段落,僅給出了問題。在這些情況下,模型依賴於在預訓練過程中獲得的知識來生成答案。

由於ROUGE分數與真實答案相符,無法反映其他方麵,如事實正確性和語法正確性,因此我們要求人工標注者為我們之前的基準係統(類似於CopyNet的LSTM模型)和當前的T NLG模型進行評判。

我們還注意到,較大的預訓練模型僅需要較少的其它任務樣本就可以很好地學好。
我們最多隻有100,000個問題-消息-答案三元組的樣本,即使僅進行了數千次訓練,我們的模型仍優於訓練了多次的LSTM基準模型。
由於收集帶標注的監督數據非常昂貴,因此這種觀察到的現象會產生實際的業務影響。

不需監督的摘要總結
NLP文獻中的摘要有兩種類型:提取-從文檔中獲取少量句子作為摘要的代名詞,抽象-用NLG模型像人類一樣生成摘要。
T-NLG的目標不是複製現有內容,而是為各種文本文檔(如電子郵件,博客文章,Word文檔,Excel工作表和PowerPoint演示文稿)編寫類似於人類的抽象摘要。
這其中主要的挑戰之一是在所有這些情況下都缺乏監督訓練數據:因為人類並不總是會明確地總結每種文檔類型。T-NLG的強大功能在於,它已經非常了解文本,因此無需太多的監督即可勝過我們之前使用的所有技術。
為了使T-NLG盡可能通用,以彙總不同類型的文本,我們在幾乎所有公開可用的彙總數據集中以多任務方式微調了T-NLG模型,總計約有400萬個訓練樣本。我們給出了ROUGE分數,以便與另一種最新的基於Transformer的語言模型(稱為PEGASUS)和以前的最新模型進行比較。
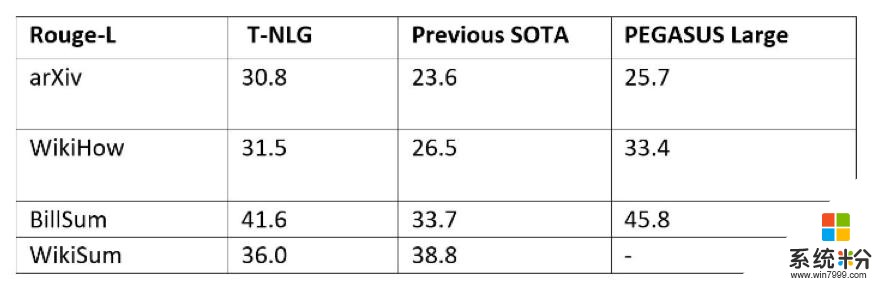
以多任務方式訓練T-NLG,同時使用所有數據集對其進行訓練。眾所周知,由於ROUGE評估在彙總任務方麵存在缺陷,因此我們在下麵提供了一些公開可用文章的輸出摘要,以供比較。


T-NLG未來的應用
T-NLG在自然語言生成方麵已經取得了優勢,為微軟和客戶提供了新的機會。
除了通過彙總文檔和電子郵件來節省用戶時間之外,T-NLG還可以通過為作者提供寫作幫助並回答讀者可能對文檔提出的問題來增強MicrosoftOffice套件的體驗。
此外,它為更流暢的聊天機器人和數字助理鋪平了道路,因為自然語言生成可以通過與客戶交談來幫助企業進行客戶關係管理和銷售。
原文:https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
本文為 CSDN 翻譯,轉載請注明來源出處。
相關資訊
最新熱門應用

幣團交易所
其它軟件43MB
下載
必安交易所官網
其它軟件179MB
下載
bicc數字交易所app
其它軟件32.92MB
下載
比特國際網交易平台
其它軟件298.7 MB
下載
熱幣交易所app官方最新版
其它軟件287.27 MB
下載
歐昜交易所
其它軟件397.1MB
下載
vvbtc交易所最新app
其它軟件31.69MB
下載
星幣交易所app蘋果版
其它軟件95.74MB
下載
zg交易所安卓版app
其它軟件41.99MB
下載
比特幣交易app安卓手機
其它軟件179MB
下載