

導讀:出自微軟亞洲研究院的Graph Engine(原名Trinity)是一個基於內存的分布式大規模圖數據處理引擎,能夠幫助用戶高效地處理大規模圖數據,且更方便地構建實時查詢應用和高吞吐量的離線分析平台。自2015年發布以來,Graph Engine受到了來自學術界和工業界的廣泛關注。點擊【閱讀原文】訪問Graph Engine 的GitHub頁麵(https://github.com/Microsoft/GraphEngine)。
今天,我們邀請了Graph Engine的主要設計者與開發者之一,微軟亞洲研究院機器學習組副研究員李亞韜為大家詳解Graph Engine,並演示一些快速上手的實例。
(以下文字整理,內容略有精簡)
首先,我們來回顧一下NOSQL中一種很重要的係統——鍵值存儲器 (Key-Value stores)。Key-Value stores是一個字典形式的索引存儲係統,裏麵所有數據都按照Key去索引,每個Key對應一個唯一值。這就像是各種語言,如Python、Java中的Dictionary或者Map。
比如MemCached,就是NOSQL中一個很早出現且非常流行的鍵值存儲器(Key-Value stores)係統。它是一個分布式、多線程的緩存係統。為什麼叫緩存係統?因為它其實並不知道用戶存儲的數據結構是什麼樣的,隻是把數據當成一個個blobs,像二進製的數組一樣。這裏的例子就是說,當給定一個Foo ID,我們利用MemCached,可以得出一個能夠識別的對象(Object)。但實際上MemCached本身無法識別我們這個東西,在它那裏其實就是一個二進製的數組。
這所帶來的問題是,一個係統如果不知道用戶存的是什麼東西,那麼所有的計算就必須在客戶端進行。因為如果係統不知道數據的屬性,那就沒有辦法操作裏麵的數據。比如我有一個很大的對象,若要更新其中的一個部分,就需要把整個對象從客戶端輸入,然後進行一些操作再寫回去。當兩個人同時寫一個東西時,就可能會導致一個人的改動被另一個人的衝掉。
Redis係統比MemCached出現得晚一些,它支持幾種簡單的數據結構。係統中每一個Key對應的值可以是一個數據結構——列表、集合或是字典。每一個值對應著一個小的容器,並且在這個容器上,它所有的操作都保持了原子性並支持事務。
但是在實際使用的過程中,我們會發現,很多時候數據沒有辦法簡單的用列表或字典這些簡單的數據結構來表示(因為它不能嵌入)。我們的數據有時候是層次結構的(Hierarchical)的,所以我們必須用某種層次化的數據結構,例如JSON、XML等去表示。在這種時候,Redis就沒有辦法很好地表達這些數據結構。實際上,業界很多用法都是用JSON模型先把它序列化成一個字符串,然後再輸入Redis。但這樣就會把Redis又變回MemCached,因為Redis不知道裏麵存的是什麼東西,所以所有的計算操作又回到客戶端。
談到數據建模(DataModeling),我們不妨從另外一個角度,用圖數據庫去解決這種問題。在圖數據庫裏,我們存儲的是實體間的關係。
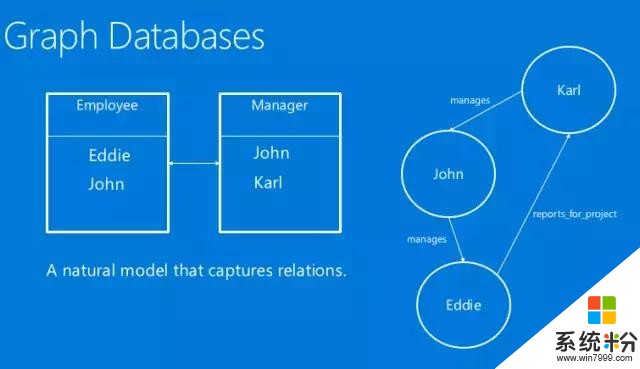
舉個例子,左邊是一個表,右邊是和它等價的圖中的關係。我們可以看到這裏有三個人,有老板,也有員工。老板會管理員工,員工也會為了某個項目向老板報告,這種數據模型最核心的數據結構就是圖。
圖由節點和節點間的邊構成。但這裏的圖和教科書上講的圖有點不一樣,我們可以在點或者邊上添加一些數據,這種圖叫做“帶屬性圖”(Property Graph),即它的點上能夠存儲數據,比如說一個人的年齡、名字等等。在這種數據模型下,我們可以有一些在圖上的查詢方法,它能夠做到在SQL中很難表達的一些事情。
也正是因為這種靈活的特性,我們在實現圖數據庫時,會遇到一些挑戰。主要的問題是在查詢時,會有很多的隨機存取。因為在圖上查詢時,很多是利用遍曆實現的。雖然一個點走到另外一個點的代價不是很高,但是如果從一萬個點走到它周圍的兩萬個點,再走到周圍的四萬個點,這樣一層一層擴散出去的話,問題就會變得越來越嚴重。如果把數據放在磁盤上,就會有很高的時延,因為我們沒有辦法很好地預測一個點的下一步會決定往哪邊遍曆。
為了解決這個問題,有幾個主要的優化手段。一個就是不要像SQL裏,同一個實體需要在不同的表裏麵查找,更多的是直接把一個點上所有相關的信息組織在一起。所以隻需查找一次,就能索引到其中的一個實體。另一個方法是,我們要盡可能多的把數據放在內存裏,這樣隨機存取的性能會提高很多。
我們在做圖遍曆時,如果是單機係統,利用廣度優先算法BFS或者深度優先算法DFS都可以。但如果是分布式係統,由於不能跨機器執行單機算法,所以我們需要用消息傳遞(Message passing)實現圖遍曆的功能。
圖數據模型下對應的查詢語言和傳統的SQL查詢語言會有一些不一樣。傳統上,如果在多個表裏查詢數據,我們會用聯結操作(join operator)把數據連在一起。但是在圖查詢語言裏,我們更多的是直接從一個點遍曆到它的鄰居,再從中篩選出符合條件的數據,做操作。
此外,在圖查詢語言裏還可以使用一些特殊的操作符。比如,給定兩個點,然後可以查詢數據庫,找兩點之間的最短距離。我們還可以做一些特殊的便利操作,比如從一個點走出去,走過一個三角形,又回到這個點,這樣就可以找到這個點周圍的所有三角形。以及,告訴係統一直沿著某個條件走下去,就好像正則表達式一樣,直到遇到一個停止條件才停下來,我們把這個叫做“閉包”操作。

接下來我們看一個“閉包”的具體例子。假設Karl是部門的大老板,他會管理一些中層幹部,這些中層幹部會管理一些基層員工;而基層員工可能會在做一些項目,他們需要直接向Karl彙報。現在在Karl管理的部門中,要找到所有向Kark直接彙報的人,應該怎麼找?
這裏的問題是,我們不能確定管理的鏈條有多長。因為可能是A管著B、B管著C、C管著D,D又向H報告。如果用SQL,就需要把所有的兩跳、三跳、四跳以及等等的操作都做一遍,最後再把結果綜合。但是在圖裏麵,由於有“閉包”操作,所以我們可以從Karl這個點出發,沿著管理這條路線走,這樣走下去一定是報告和管理的關係,而終止條件是找到一個點,它不再管理其他人,或者是它連回了一條邊,比如Karl這條報告的邊。
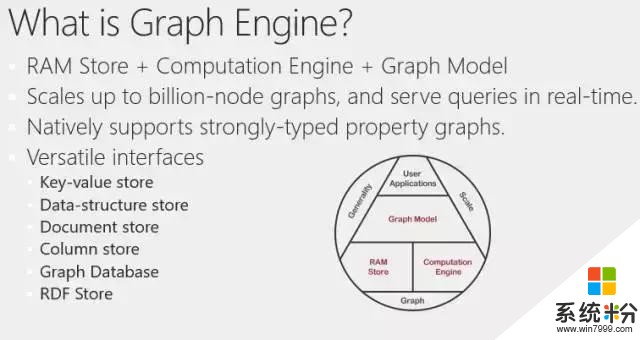
剛才介紹了內存中係統以及Graph model怎麼為數據建模,並且簡單介紹了圖數據庫上的查詢語句以及它是怎麼做計算的。將這些內容結合,我們做了一個係統,就是Graph Engine,用於處理以上工作。
這裏有一個係統結構示意圖,中間這個三角形是係統的基礎架構。最底層是一個內存中的鍵值存儲器(Key-Value stores),以及計算引擎。計算引擎在不同機器之間會傳遞消息,並且一個機器可以調用另一個機器上某一類消息的響應代碼(Handler)。在這種架構上構建圖模型層(Graph Model),用戶就可以利用圖模型層的抽象,做自己的應用。所以Graph Engine係統不僅可以進行圖數據的處理,由於它是分布式的,所以存儲管理(Memory management)做的也相對較好,可擴展性(Scalability)也比較好。此外它還具有一定的通用性,不僅是圖上的計算,還可以用於其他的應用。比如可以簡單的把它用作鍵值存儲器,簡單的定義數據結構,當成Redis去用。
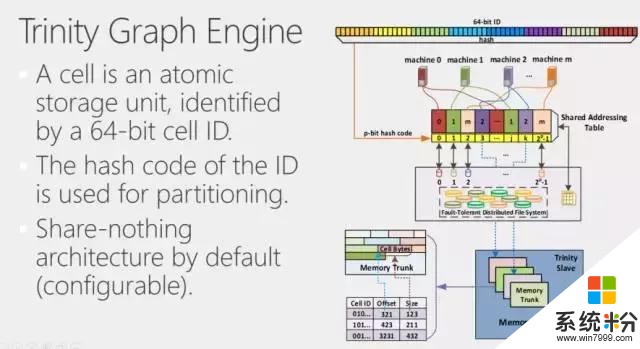
在係統最底層, RAM store本質上也是一個鍵值存儲器,使用64位整數做Key,Value是任意的一個值。每個機器上有一個本地的RAM Store,不同的機器之間,給定一個Key之後,通過對這個Key進行Hash,可以判斷當前的實體,即Cell ID對應的Value是在哪個機器上。這是一種叫Share-nothing的配置方法。當然這是一個可配置的(Configurable)方案,但是默認情況下,它是一個Share-nothing的結構。
拿到一個Key,首先判斷它在哪個機器上,如果我們要訪問對象,就把這個消息發到那個機器上,機器訪問自己的本地內存數據。一個內存存儲(Memory store)可以分成很多不同的塊(Memory Trunk),裏麵有一套內存管理係統,所以我們最終可以定位到每一個對象所對應的內存區域。
講到這兒大家可能會有一個疑問。剛才說,如果把數據按照Blob二進製存的話會有些限製,可現在不還是把數據扔到一個內存塊裏麵,存儲為byte數組麼?那接下來就講講我們是怎麼處理這個問題的。
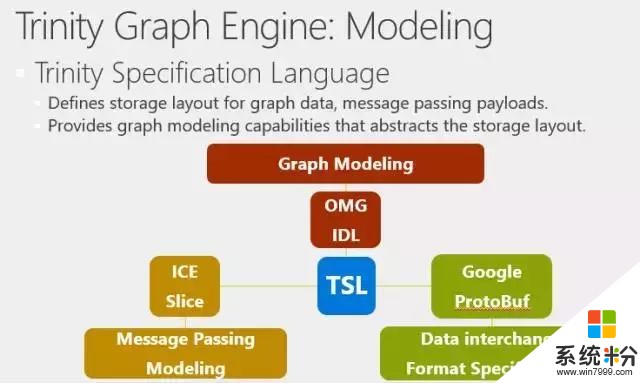
在Graph Engine係統中,我們使用Trinity Specification Language語言,即TSL,來完成以下三種功能。第一個,做數據建模,雖然存儲時存成的是一個Blob,但實際上我們有它的數據模式(Schema),並且可以由用戶指定,而不是用一些簡單的自帶數據結構。第二,在做Message passing時,如果期望得到某一種格式的回複,我們可以用TSL來定義消息傳遞格式。第三,係統和其他外部係統之間需要交互,比如要從C#裏傳遞一個東西,放到Python裏,我們也可以通過TSL來進行數據交換,我們可以提供一種標準,作為數據的中間格式。

這裏有兩個TSL的例子,可以看到TSL和C族語言非常像。首先,看一下圖模型的定義,我們用Cell關鍵字,指明定義的結構體是一種實體——實際上一個cell就是一個Key對應的一個Value,它有自己的內部結構。比如Movie裏有電影名字,主演等。同樣的,根據演員名字,我們可以得出這個人演了哪些電影。
我們可以在實體的 Cell Type以及它的Filed上加一些屬性,用於和係統的其他模塊進行交互。在Message Passing裏,實際上是一個類似的結構,我們可以定義一個結構,一個cell也可以包含一個結構,不過這個結構體還可以額外用來做Message Passing。
定義結構後,接下來,我們定義了一個通信協議,協議說,發送消息是同步消息,消息發出後,我期待對方處理完返回的還是一個My Message。
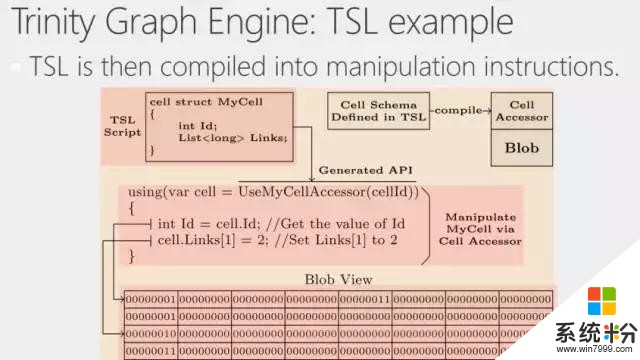
定義好TSL後,會有一個TSL編譯器,根據用戶定義的Cell Struct以及其他定義結構,生成一些對Cell操作的存取器(Accessor)。比如這裏的UseMyCellAccesor,這個API不是係統本來提供的,而是Graph Engine的程序集(Assembly)加上用戶的TSL生成出的程序集然後再綜合生成的一個API。
這個API的使用方法和Struct類似,可以直接操作裏麵的ID,也可以認為裏麵Links是個List,直接分配給List一些值。但實際上我們並沒有分配一個運行時的List,我們會把操作翻譯成對當前Cell對應的內存的操作。也就是說鍵值存儲器負責最基本的給出內存空間。然後生成的代碼負責處理用戶如何分配數據,係統應該如何理解數據。
這樣一來,我們可以用像Struct一樣簡單的接口,利用Accessor,操作一個虛擬的概念。我們隻提供了對操作的描述,具體的執行則是翻譯成了低層對內存直接的操作。這樣既能保證用戶接口的友好性,工作效率也可以做得非常高。
另外,這也是Graph Engine與其他係統一個很顯著的區別,係統不僅可以對裏麵所存的實體進行類型定義,也可以有它自己的結構,甚至這個結構是分層的,因為一個Cell也可以包含其他的Struct。另一方麵,由於擁有Accessor這套係統,因此,它可以直接在RAM Store裏就地操作數據,從而相應地提高效率。
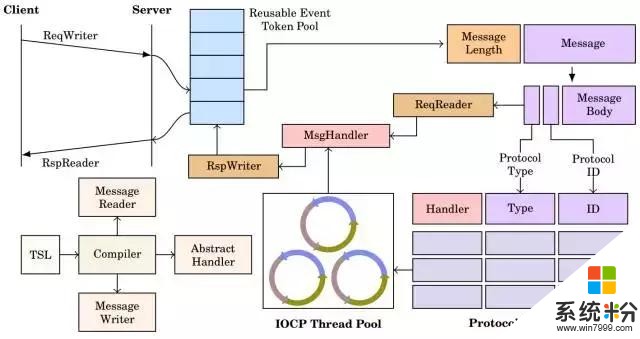
與此類似的,在用TSL做Message Passing過程中,我們從上圖的左上角看起,客戶端先初始化了一個請求服務器。在客戶端,Graph Engine隻負責分配緩衝區(Buffer),然後生成的API就會有Data Accsesor告訴我們如何往緩衝中填充數據,甚至可以直接把RAM Store中的一些數據取出,再通過Accesor傳給服務器。在服務器這邊,我們有一個IOCP的線程池(Thread Pool),或者在Linux係統中,我們用的是一個事件庫。
並且我們還定義了協議(Protocol),每一個協議會對應一個Handler,代表服務器收到該協議的消息後應該做什麼動作。我們把這個東西存成一個地址向量,在客戶端來了一個請求後,係統通過向量跳轉到一個Handler裏去執行。執行完成後,根據消息是同步還是異步,可以做一個選擇。如果同步,客戶端會進行block,直到服務器處理完這個消息,並返回處理結果。
我們注意到,客戶端發送的請求ReqWriter以及服務器返回的RspReader,其實都是由TSL編譯器生成的。不僅如此,在一個消息到達服務器之後,它有一個調度(Dispatch)的過程,需要把消息翻譯成一種數據結構,這裏我們可以直接用Data Accessor去讀取緩衝器中的內容。所有的輔助過程,包括Handler的抽象接口,都是由TSL Compiler生成的。我們設計係統的目標就是讓消息傳遞(Remote Message Passing)變得盡量簡單,就像在本地寫GUI程序一樣。
關於係統底層的實現細節就先介紹到這裏。下麵來看一個具體的例子——做一個Twitter的“爬蟲”。Twitter本身提供了一組Streaming API,訂閱後會不停地給你推送最新的消息。
我們可以在Graph Engine上加一個Message Handler,每次Twitter來了一條新的消息,我們就向這個消息協議轉發,這個協議(Protocol)可以是同步、異步,或者是內部的協議,也可以是HTTP的協議,所以和其他語言非常好交互。

我們可以用這個做什麼事情呢?當一條推文來了之後,我們可以把它放到Graph Engine裏。在消息處理器中找到這條推文應該存的地方,比如,哪個用戶發的,提到了哪些人等等。在做這件事情的同時,實體間的關係就建立起來了,因為一個用戶發了一個推文,會有一個關係連到一條邊,如果推文裏提到了其他人,那麼係統就不僅是存下了這條信息,還可以把所有關係都實時建立起來。
不僅如此,在不停更新數據的同時,我們還可以在上麵跑一些計算,記在數據庫裏,並進行一些查詢。
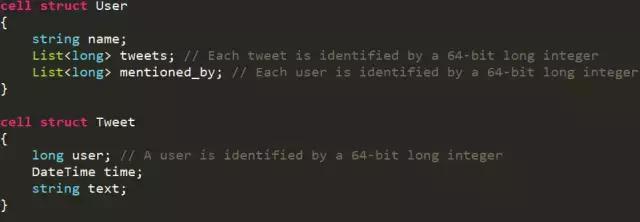
這裏是一個簡化的Twitter 圖模型,裏麵有兩種實體,一種是用戶、一種是推文,我們用邊把它們連起來,發現用戶可能被其他的推文提到過。與此同時,關於推文的定義,它裏麵有一個單獨的邊,指向發推文的用戶,並且把文本內容作為一個屬性,附在這個點上。
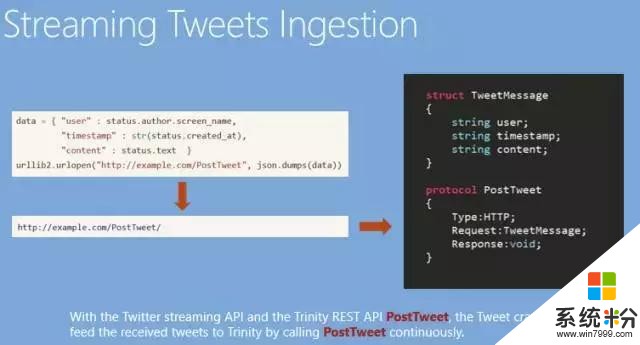
比如,我寫好了一個Python的Twitter“爬蟲“,調用了官方接口,就可以去監測Twitter中的事件,那麼怎麼交互呢?在Graph Engine裏麵定義一個協議(Protocol),標出期望的請求是一個Tweet Message,這裏麵就包含了用戶、時間戳、文本內容。因為這是一個事件定義,文本內容裏可能是它發出的一個推文。在指定協議為HTTP後,Graph Engine啟動時候就會監測一個HTTP的協議,然後我們就可以在Python裏直接把數據傳送到Graph Engine。
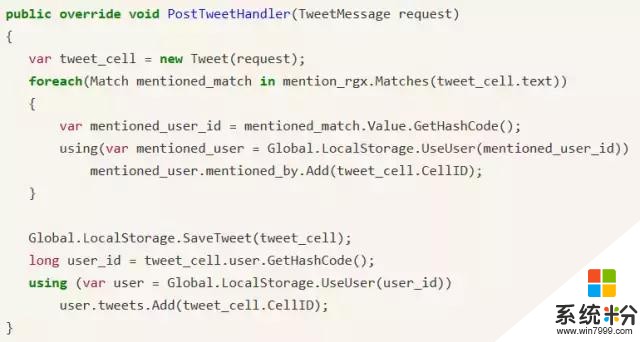
上圖可以看到Post Tweet Handler的具體實現。首先從Python方來了一個請求,我們收到了一個推文消息,然後就可以實時在Handler裏用正則表達式看有沒有提到用戶名的部分。如果有,就抽取出來,變成User ID,然後填充相應的關係。以及在此之後,我們會把當前推文存到係統裏麵。因為Handler不是單線程的調用,係統有一個thread Pool,所以這樣的操作可以在一個Handler裏實時完成。
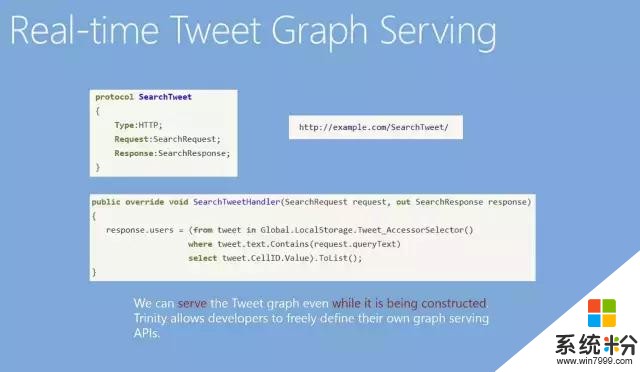
更進一步,在不停的接收(Ingest)數據的同時,還可以定義另外一個協議。現在如果要做全文索引,就可以看到定義了協議後域名下就會多出一個SearchTweet的地址,如果用一個Python代碼去訪問這個地址,就會觸發SearchTweetHandler。這裏可以使用LINQ語法,localstorage代表要用自己機器上的RAM Store。後麵的Selector是說一但使用Tweet_AccessorSelector,就會把所有推文全部選出來,再之後就可以用“where”做過濾(filtering)。比如,文本裏有請求的查詢內容,滿足條件我們就做一個投影(projection),取出Cell ID,然後我們就拿到了所有符合搜索的推文。
那麼問題也來了。Schema是用戶自定義的,這裏可能包含任何東西,在這種情況下,如何設計一個標準的圖模型層?為此,我們采取了一個方案,就是把整個係統做成一個模塊化係統(Module System),每一個模塊可以提供一個泛型算法(Generic Algorithms),它不和某個具體數據綁定,而是根據某種元規則執行算法,類似C++裏麵模板庫做的事情。
隻要泛型算法對於一個數據的觀點、看法和用戶對於數據的看法一致,那麼就可以說用戶數據的schema和某個泛型算法是兼容的,進而用戶就可以實現一個通用的圖模型來完成一些他不方便自己實現的功能。
具體來講,回到剛才的Tweet Graph上,我們有用戶和推文兩種實體。我們的目標是要把查詢語言,就是LIKQ,應用到Tweet Graph,在Tweet Graph上實現圖的查詢。問題是現在的Schema裏隻有List<long>,係統不可能見到List<long>就認為它是一個邊,然後去遍曆,因為這個Long可能還有別的意思,這樣是不現實的。
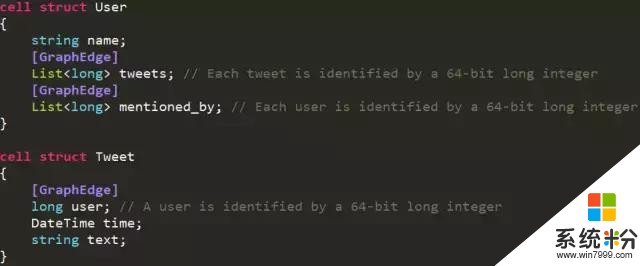
為了解決這個不匹配問題,我們可以加一些屬性。這裏的屬性是TSL裏麵的,和C#裏是不一樣的,可以理解成是一個字符串,我們把字符串的標簽(tag)打在了一個實體或者field上。這裏打的標簽叫做“ GraphEdge”,這樣就指定了,它是圖裏麵的邊。這就回到了剛才所討論的,數據和泛型算法對於一個屬性有沒有統一的認識。比如,如果查詢語言覺得GraphEdge是邊的意思,那麼它就會采取一個方案。如果是一個算法的模塊調用一個具體的名字,如遍曆判斷當前是不是一個用戶。如果是用戶就從Tweets mentioned_by走過去,那這樣就不是泛型算法,因為它引用(reference)一個具體的數據。
為了避免這種情況,我們允許泛型算法直接通過屬性,找到一個實體中所有符合屬性的部分。它可以請求係統,去當前的實體裏尋找所有有GraphEdge標誌的部分,並且目標是想從這裏麵提取出長整型。所以不管你的Graph Engine是List<long>,還是單獨的Long,甚至是一個Int,更有甚者,這裏存的是個String,都可以通過我們係統的Graph Model中間層,然後盡可能的枚舉(Enumerate)出長整型來,使得用戶數據和係統的泛型算法間可以聯係在一起。
接下來我們看一下具體的圖查詢語言,即LIKQ 。LIKQ是一個直接可以嵌入編程語言的查詢語言,它和LINQ很像,都有一個很流暢的語法,可以直接寫在編程語言裏。
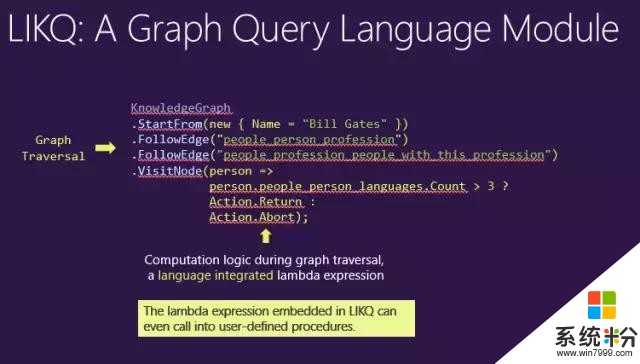
這裏的例子是一個知識圖譜,StartFrom這個點,指定一個查詢條件,名字叫“比爾蓋茨”,從這個點FollowEdge,就說從人這個點走到他的職業,然後再從FollowEdge走到people_profession_people_with_this_profession,就找到了和他相同職業的所有人。
我們不僅可以簡單從每條邊走出去,同時可以在一個點上時時的添加一些查詢條件,方法是給這個點傳入一個Lambda表達式,每當遍曆的框架遇到這個點,比如走到第三跳時,就會動態執行這個Lambda表達式。
比如這裏的例子是找和比爾蓋茨相同職業的,會說三種以上語言的人。如果找到了,係統就保存當前路徑(Path),否則就終止當前的搜索。
Lambda表達式具有非常靈活的查詢(Query)特性,不僅可以調用Count>3,用戶甚至可以預先把自己的一些功能注冊到LIKQ模塊裏,隻要服務器配置正確且加載了程序集(assembly),客戶端就可以直接調用這個接口,調用服務器上預先存好的邏輯,而不用把整個邏輯全部寫到Query裏麵。

LIKQ語言是一種線性遍曆語言,所有的查詢動作都是圖的遍曆(Graph Traversal)。比如Tweet Graph中,指定從Graph Engine出發(即Twitter上我們的帳號),從mentioned_by找到所有提到我們的人,不做任何過濾,一旦到達那個點之後,就執行下一跳,走的邊是用戶。也就是說從Graph Engine mentioned_by出發,找到了一個用戶,即有一個用戶提到了我們,走到這個用戶後繼續往前走,找到他們所發的那些推文。
這樣一來,一旦到達某個推文之後,不加任何限製條件的時候係統會Action.Return。也就是說,由於它是一個線性的查詢語言,因此每個查詢表達式對應在圖遍曆中的一條路徑上所有的限製條件,即它的限製條件都是從Graph Engine出發然後到一個用戶再到一個推文。所以它隻是限定了跳數,以及每一步從什麼邊跳出去。到達推文之後,它會無條件的把當前路徑當成結果的一部分返回,然後做一些投影,把推文裏的文本選擇出來。這就是LIKQ圖數據查詢語言的一些簡單例子。
看完這篇文章有沒有收獲很大?還想了解更多相關問題麼?快來下方評論區提問吧!
相關資訊
最新熱門應用

芝麻交易所最新版本
其它軟件223.89MB
下載
bione數字貨幣交易所5.1.9最新版
其它軟件49.33M
下載
zb交易所手機app
其它軟件225.08MB
下載
ght交易平台
其它軟件168.21M
下載
芝麻交易所ios蘋果版
其它軟件223.89MB
下載
zt交易所包
其它軟件273.2 MB
下載
ubcoin交易所官網
其它軟件18.21MB
下載
mxc官方交易平台app
其它軟件84.30MB
下載
鏈易交易平台app
其它軟件72.70MB
下載
mxc交易所app
其它軟件98.2MB
下載