
翻譯沒有唯一標準答案,它更像一種藝術。
AI科技評論消息:14日晚,微軟亞洲研究院與雷德蒙研究院的研究人員宣布,其研發的機器翻譯係統在通用新聞報道測試集newstest2017的中-英測試集上,達到了可與人工翻譯媲美的水平;這是首個在新聞報道的翻譯質量和準確率上可以比肩人工翻譯的翻譯係統。
newstest2017測試集由來自產業界和學術界的團隊共同開發完成,並於2017年在WMT17大會上發布。而新聞(news)測試集則是三類翻譯測試集中的一個,其他兩類為生物醫學(biomedical)和多模式(multimodal)。
四大技術我們知道,對於同一個意思人類可以用不同的句子來表達,因此翻譯並沒有標準答案,即使是兩位專業的翻譯人員對於完全相同的句子也會有略微不同的翻譯,而且兩個人的翻譯都不錯。微軟亞洲研究院副院長、自然語言計算組負責人周明表示:“這也是為什麼機器翻譯比純粹的模式識別任務複雜得多,人們可能用不同的詞語來表達完全相同的意思,但未必能準確判斷哪一個更好。”
這也是為什麼科研人員在機器翻譯上攻堅了數十年,甚至曾經很多人都認為機器翻譯永遠不可能達到人類翻譯的水平。近兩年隨著深度神經網絡的引入,機器翻譯的表現取得了很多顯著的提升,翻譯結果相較於以往的統計機器翻譯結果更加的自然流暢。
據了解,在這次的工作中來自微軟亞洲研究院和雷德蒙研究院的三個研究組通過多次交流合作,將他們的研究工作相結合,再次更進一步地提高了機器翻譯的質量,其中用到的技術包括對偶學習(Dual Learning)、推敲網絡(Deliberation Networks)、聯合訓練(Joint Training)和一致性規範(Agreement Regularization)等。
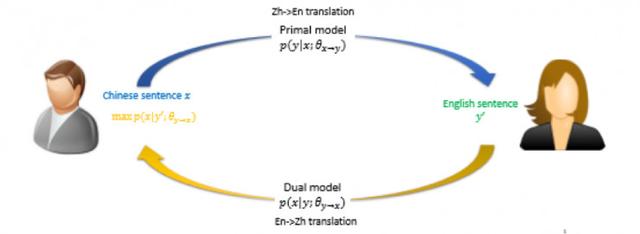
對偶無監督學習框架
對偶學習,即利用任務的對偶結構來進行學習。例如,在翻譯領域,我們關心從英文翻譯到中文,也同樣關心從中文翻譯回英文。由於存在這樣的對偶結構,兩個任務可以互相提供反饋信息,而這些反饋信息可以用來訓練深度學習模型。也就是說,即便沒有人為標注的數據,有了對偶結構也可以做深度學習。另一方麵,兩個對偶任務可以互相充當對方的環境,這樣就不必與真實的環境做交互,兩個對偶任務之間的交互就可以產生有效的反饋信號。因此,充分地利用對偶結構,就有望解決深度學習和增強學習的瓶頸——訓練數據從哪裏來、與環境的交互怎麼持續進行等問題。
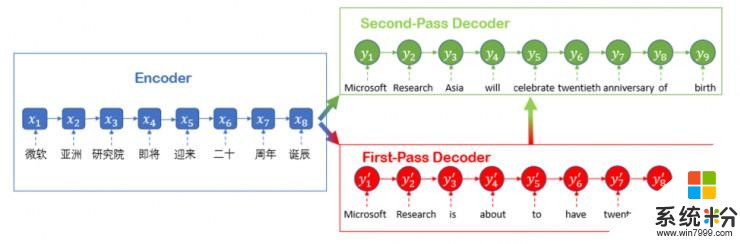
推敲網絡的解碼過程
推敲網絡中的“推敲”二字可以認為是來源於人類閱讀、寫文章以及做其他任務時候的一種行為方式,即任務完成之後,並不當即終止,而是會反複推敲。微軟亞洲研究院機器學習組將這個過程沿用到了機器學習中。推敲網絡具有兩段解碼器,其中第一階段解碼器用於解碼生成原始序列,第二階段解碼器通過推敲的過程打磨和潤色原始語句。後者了解全局信息,在機器翻譯中看,它可以基於第一階段生成的語句,產生更好的翻譯結果。
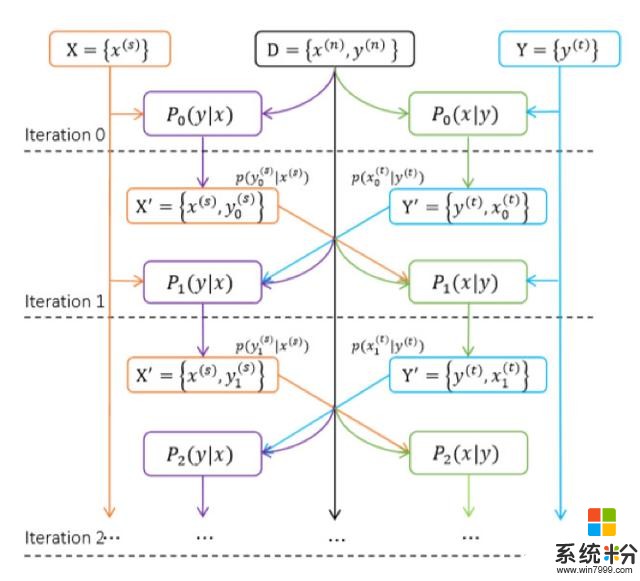
聯合訓練:從源語言到目標語言翻譯(Source to Target)P(y|x) 與從目標語言到源語言翻譯(Target to Source)P(x|y)
聯合訓練可以認為是從源語言到目標語言翻譯(Source to Target)的學習與從目標語言到源語言翻譯(Target to Source)的學習的結合。中英翻譯和英中翻譯都使用初始並行數據來訓練,在每次訓練的迭代過程中,中英翻譯係統將中文句子翻譯成英文句子,從而獲得新的句對,而該句對又可以反過來補充到英中翻譯係統的數據集中。同理,這個過程也可以反向進行。這樣雙向融合不僅使得兩個係統的訓練數據集大大增加,而且準確率也大幅提高。
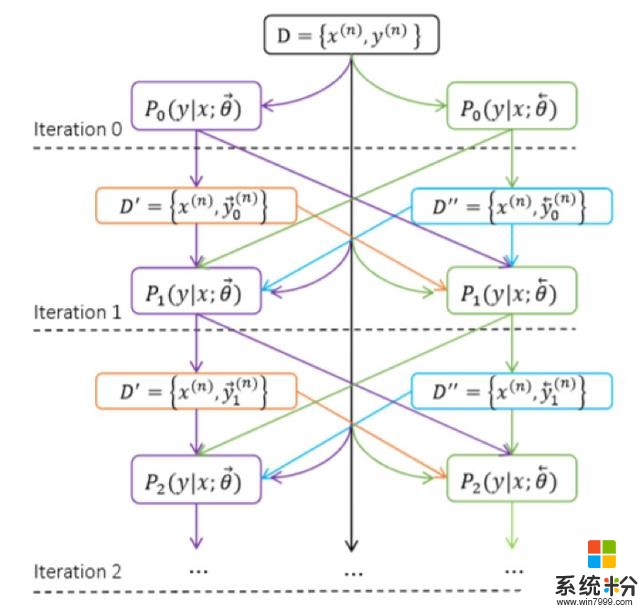
一致性規範:從左到右P(y|x,theta->) 和從右到左P(y|x,theta
一致性規範,即翻譯結果可以從左到右按順序產生,也可以從右到左進行生成。該規範對從左到右和從右到左的翻譯結果進行約束。如果這兩個過程生成的翻譯結果一樣,一般而言比結果不一樣的翻譯更加可信。這個約束,應用於神經機器翻譯訓練過程中,以鼓勵係統基於這兩個相反的過程生成一致的翻譯結果。
與人類比較由於機器翻譯沒有“正確的”翻譯結果,為了與人類的翻譯水平進行比較,就必須嚴格地定義什麼是與人類翻譯水平相當。根據其發表的論文中表述,這種定義有兩種:
1、如果一個具備雙語能力的人判斷人類輸出的譯文質量與機器輸出的譯文質量相當,則機器達到人類水平。
2、如果機器翻譯係統在測試集上的譯文質量得分(人工評分)與人類譯文得分沒有顯著差別,則機器達到人類水平。
微軟選擇了第二種定義,因為這樣相對而言比較公平且有實際意義。
newstest2017新聞報道測試集中共包括了約2000個句子,它們是由專業人員從在線報紙樣本翻譯而來。
微軟團隊對測試集進行了多輪評估,每次評估會隨機挑選數百個句子進行翻譯。
隨後,為了驗證微軟的機器翻譯是否達到了人類翻譯水平,微軟從外部聘請了一群雙語語言顧問,讓他們對微軟的翻譯結果和人工的翻譯進行比較和評分,結果如下:
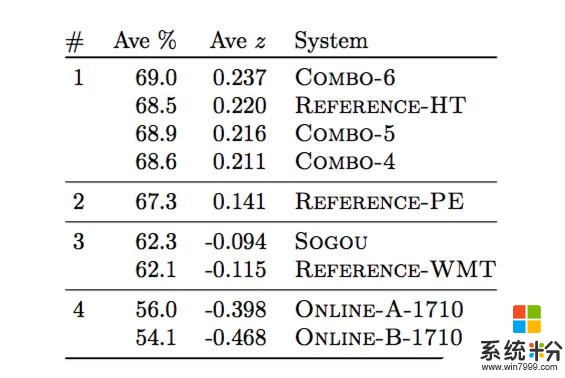
#表示集群的排名,Ave%表示平均原始分數(範圍在[0,100]之間),Ave z表示標準 z分數。該表顯示了係統收集了至少1827份評估結果。
從表中我們可以看出,微軟的係統(Combo-4, 5, 6)已經與人類翻譯(Reference-HT)無顯著差別,遠遠超過Reference-PE(人類翻譯—基於機器翻譯後的編輯)以及Reference-WMT。
任重而道遠對於這項結果,來自微軟的研究人員卻表現地極為自然。

微軟技術院士黃學東,負責微軟語音、自然語言和機器翻譯
微軟技術院士黃學東告訴記者:
“在機器翻譯方麵達到與人類相同的水平是所有人的夢想,我們沒有想到這麼快就能實現。消除語言障礙,幫助人們更好地溝通,這非常有意義,值得我們多年來為此付出的努力。”
微軟機器翻譯團隊研究經理Arul Menezes表示:
“團隊想要證明的是:當一種語言對(比如中-英)擁有較多的訓練數據,且測試集中包含的是常見的大眾類新聞詞彙時,那麼在人工智能技術的加持下機器翻譯係統的表現可以與人類媲美。”

微軟亞洲研究院副院長、自然語言計算組負責人周明
微軟亞洲研究院副院長、自然語言計算組負責人周明則表示任重而道遠:
“在WMT17測試集上的翻譯結果達到人類水平很鼓舞人心,但仍有很多挑戰需要我們解決,比如在實時的新聞報道上測試係統等。”

微軟亞洲研究院副院長、機器學習組負責人劉鐵岩
而微軟亞洲研究院副院長、機器學習組負責人劉鐵岩對技術的進展表示樂觀:
“我們不知道哪一天機器翻譯係統才能在翻譯任何語言、任何類型的文本時,都能在“信、達、雅”等多個維度上達到專業翻譯人員的水準。我們可以預測的是,新技術的應用一定會讓機器翻譯的結果日臻完善。”
據了解,此次的技術突破將很快應用到微軟的商用多語言翻譯係統產品中,從而幫助其它語言或詞彙更複雜、更專業的文本實現更準確、更地道的翻譯。此外,這些新技術還可以被應用在機器翻譯之外的其他領域,催生更多人工智能技術和應用的突破。
相關資訊
最新熱門應用

hotbit交易平台app安卓版
其它軟件223.89MB
下載
bilaxy交易所app
其它軟件223.89MB
下載
avive交易所官網最新版
其它軟件292.97MB
下載
必安交易所app官網版安卓
其它軟件179MB
下載
富比特交易所app安卓版
其它軟件34.95 MB
下載
美卡幣交易所安卓版
其它軟件16.3MB
下載
幣幣交易所app官網
其它軟件45.35MB
下載
熱幣交易所最新版本app
其它軟件287.27 MB
下載
zbg交易所官方ios
其它軟件96.60MB
下載
拉菲交易所安卓版
其它軟件223.89MB
下載