
深度學習框架就像語言一樣:很多人會說英語,但每種語言都有自己的特殊性。作者為幾種不同的網絡結構創建了通用代碼,並可在多個不同的框架中使用。
repo 1.0 完整版 GitHub 地址:https://github.com/ilkarman/DeepLearningFrameworks
我們的想法是創建一個深度學習框架的羅塞塔石碑(Rosetta Stone):假設你很了解某個深度學習框架,你就可以幫助別人使用任何框架。你可能會遇到論文中代碼是另一個框架或整個流程都使用另一種語言的情況。相比在自己喜歡的框架中從頭開始編寫模型,使用「外來」語言會更容易。
感謝 CNTK、Pytorch、Chainer、Caffe2 和 Knet 團隊,以及來自開源社區的所有人在過去幾個月為該 repo 所做的貢獻。
我們的目標是:
1. 創建深度學習框架的羅塞塔石碑,使數據科學家能夠在不同框架之間輕鬆運用專業知識。
2. 使用最新的高級 API 優化 GPU 代碼。
3. 創建一個 GPU 對比的常用設置(可能是 CUDA 版本和精度)。
4. 創建一個跨語言對比的常用設置(Python、Julia、R)。
5. 驗證自己搭建框架的預期性能。
6. 實現不同開源社區之間的合作。
基準深度學習框架的結果
下麵我們來看一種 CNN 模型的訓練時間和結果(預訓練的 ResNet50 模型執行特征提取),以及一種 RNN 模型的訓練時間。
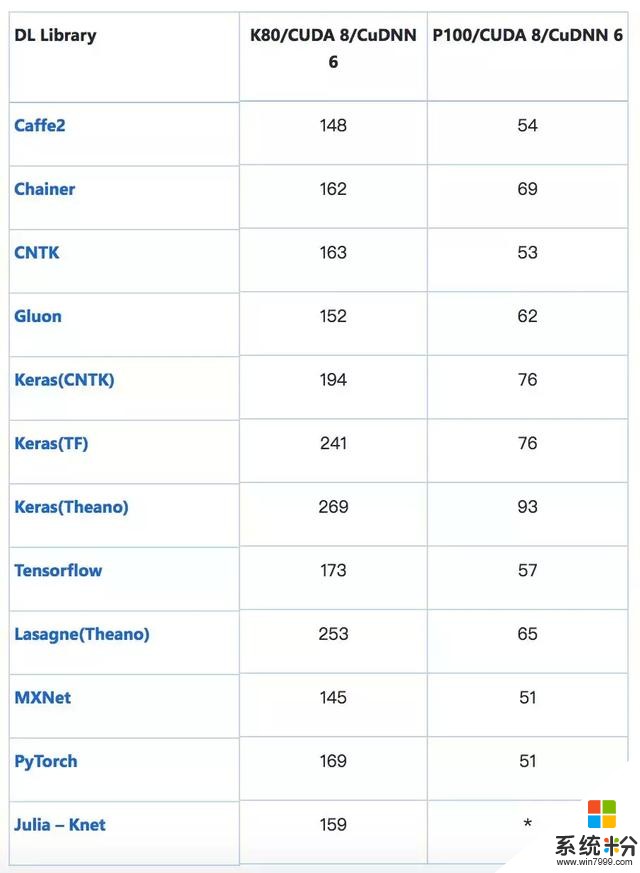
訓練時間(s):CNN(VGG-style,32bit)在 CIFAR-10 上執行圖像識別任務
該模型的輸入是標準 CIFAR-10 數據集(包含 5 萬張訓練圖像和 1 萬張測試圖像),均勻地分成 10 個類別。將每張 32×32 圖像處理為形狀 (3, 32, 32) 的張量,像素強度從 0-255 重新調整至 0-1。
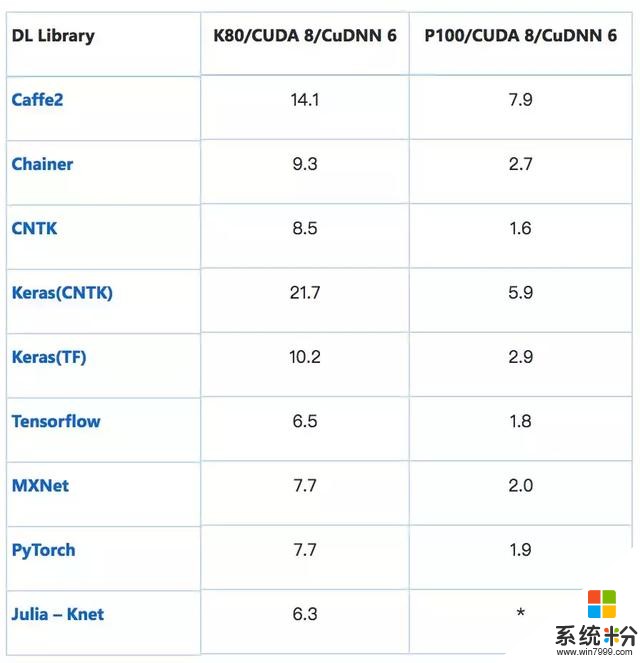
處理 1000 張圖像的平均時間(s):ResNet-50——特征提取
加載預訓練 ResNet-50 模型在末端 (7, 7) 平均池化之後裁斷,輸出 2048D 向量。其可插入 softmax 層或另一個分類器(如 boosted tree)來執行遷移學習。考慮到熱啟動,這種僅前向傳播至 avg_pool 層的操作有時間限製。注意:批量大小保持常量,但是增加 GPU 內存可帶來更好的性能提升(GPU 內存越多越好)。
訓練時間(s):RNN (GRU) 在 IMDB 數據集上執行情感分析任務
模型輸入為標準 IMDB 電影評論數據集(包含 25k 訓練評論和 25k 測試評論),均勻地分為兩類(積極/消極)。使用 https://github.com/keras-team/keras/blob/master/keras/datasets/imdb.py 中的方法進行處理,起始字符設置為 1,集外詞(OOV,本次訓練使用的詞彙表包括 3 萬單詞)設置為 2,這樣單詞索引從 3. Zero 開始,通過填充或截斷使每條評論固定為 150 詞。
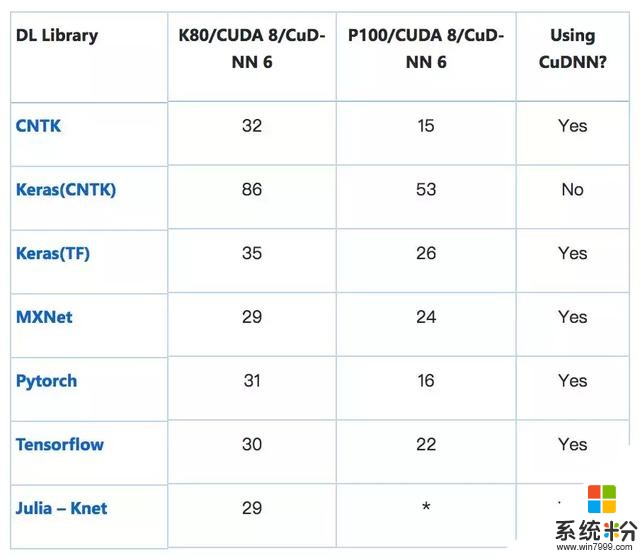
*表示截至本文發布時尚未實現。歡迎社區補充。
經驗教訓
1. 使用自動調參模式:大部分框架使用 cuDNN 的 cudnnFindConvolutionForwardAlgorithm() 來運行窮舉搜索,優化在固定大小圖像上前向卷積所使用的算法。這通常是默認的設置,但是一些框架可能需要一個 flag,例如 torch.backends.cudnn.benchmark=True。
2. 盡可能多地使用 cuDNN:常用的 RNN(如基礎 GRU/LSTM)通常可以調用 cuDNN 封裝器來加速,即用 cudnn_rnn.CudnnGRU() 代替 rnn.GRUCell()。缺點是稍後在 CPU 上運行推斷時難度可能會增加。
3. 匹配形狀:在 cuDNN 上運行時,為 CNN 匹配 NCHW 的原始 channel-ordering、為 RNN 匹配 TNC 可以削減浪費在重塑(reshape)操作上的時間,直接進行矩陣乘法。
4. 原始生成器:使用框架的原始生成器,增強和預處理(例如 shuffling)通過多線程進行異步處理,實現加速。
5. 對於推斷,確保指定的 flag 可以保存被計算的非必要梯度,以及 batch-norm 和 drop-out 等層得到合理使用。
當我們從頭開始創建該 repo 的時候,為了確保在不同框架之間使用的是相同的模型,並以最優化的方式運行,我們使用了很多技巧。過去幾個月裏,這些框架的改版之快令人驚訝,框架的更新導致很多在 2017 年末學會的優化方法如今已然過時。
例如,以 TF 為後端的 Keras 擁有 channel-ordering 硬編碼作為 channels-last(對於 cuDNN 不是最優的),因此指定 channels-first 意味著它將在每個批次(batch)之後重塑到硬編碼值,從而極大降低訓練速度。現在以 TF 為後端的 keras 支持原始 channels-first ordering。之前,TensorFlow 可以通過指定一個 flag 來使用 Winograd 算法用於卷積運算,然而現在這種方法不再有用。你可以在該 repo 的早期版本(https://github.com/ilkarman/DeepLearningFrameworks/tree/cb6792043a330a16f36a5310d3856f23f7a45662)中查看其中的最初學習階段部分。
通過在不同的框架中完成端到端解決方案,我們可以用多種方式對比框架。由於相同的模型架構和數據被用於每一個框架,因此得到的模型準確率在各個框架之間是非常相似的(實際上,這正是我們測試代碼以確保相同的模型在不同框架上運行的一種方法)。此外,該 notebook 的開發目的是為了使框架之間的對比更加容易,而模型加速則不是必要的。
當然,該項目的目的是使用速度和推斷時間等指標來對比不同的框架,而不是為了評估某個框架的整體性能,因為它忽略了一些重要的對比,例如:幫助和支持、提供預訓練模型、自定義層和架構、數據加載器、調試、支持的不同平台、分布式訓練等。該 repo 隻是為了展示如何在不同的框架上構建相同的網絡,並對這些特定的網絡評估性能。
深度學習框架的「旅行伴侶」
深度學習社區流行著很多種深度學習框架,該項目可以幫助 AI 開發者和數據科學家應用不同的深度學習框架。一個相關的工作是 Open Neural Network Exchange(ONNX),這是一個在框架間遷移深度學習模型的開源互通標準。當在一個框架中進行開發工作,但希望轉換到另一個框架中評估模型的時候,ONNX 很有用。類似地,MMdnn 是一組幫助用戶直接在不同框架之間轉換的工具(以及對模型架構進行可視化)。
深度學習框架的「旅行伴侶」工具如 ONNX 和 MMdnn 就像是自動化的機器翻譯係統。相比之下,我們今天發布的 repo 1.0 完整版更像是深度學習框架的羅塞塔石碑,在不同的框架上端到端地展示模型構建過程。
相關資訊
最新熱門應用

中安交易所官網
其它軟件58.84MB
下載
熱幣全球交易所app蘋果
其它軟件38.33MB
下載
歐聯交易所app
其它軟件34.95 MB
下載
bitstamp交易所
其它軟件223.89MB
下載
幣行交易所app安卓版
其它軟件11.97MB
下載
zbx交易平台
其它軟件32.73 MB
下載
鏈一交易所
其它軟件94.15MB
下載
易付幣交易所官網安卓版
其它軟件108.01M
下載
芝麻交易所官網蘋果手機
其它軟件223.89MB
下載
幣王交易所app蘋果
其它軟件47.98MB
下載