
近日微軟發布博客,提出一種半監督通用神經機器翻譯方法,解決低資源語言機器翻譯的問題,幫助解決方言和口語機器翻譯難題。該研究相關論文已被 NAACL 2018 接收。
機器翻譯已經成為促進全球交流的重要組成部分。數百萬人使用在線翻譯係統和移動應用進行跨越語言障礙的交流。在近幾年深度學習的浪潮中,機器翻譯取得了快速進步。
微軟研究院近期實現了機器翻譯的曆史性裏程碑——新聞文章中英翻譯達到人類水平。這一當前最優方法是一個神經機器翻譯(NMT)係統,該係統使用了數千萬新聞領域的平行句子作為訓練數據。如此巨量的訓練數據僅僅在少數語言對可以獲得,也僅限於少數特定領域,例如新聞領域或官方記錄。
事實上,盡管全球共有大約七千種口語,但是絕大多數語言都不具備訓練可用機器翻譯係統所需的大量資源。此外,即使具有大量平行數據的語言,也並沒有口語對話或者社交媒體文本等非正式風格的數據,這通常和正式的書麵風格大有不同。對任何語言對而言,獲取數百萬平行句子的數據都是相當困難的。而為任何語言尋找單語數據都會容易一些。
微軟使用半監督通用神經機器翻譯的方法解決了平行數據不足的挑戰,對於極低資源的語言而言,這種方法僅僅需要數千個平行語句就可以實現高質量的機器翻譯係統。這項令人激動的研究(https://www.microsoft.com/en-us/research/publication/universal-neural-machine-translation-extremely-low-resource-languages/)將在 NAACL 2018 上展示。
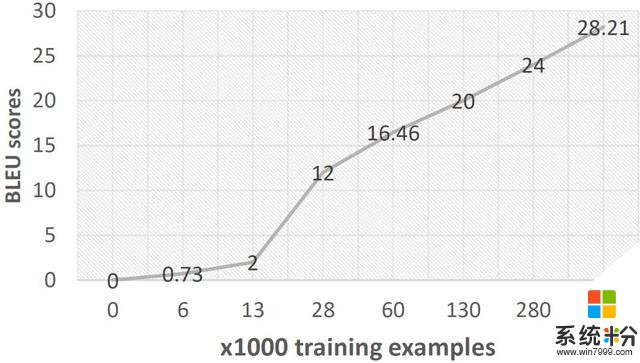
圖 1:訓練數據較少的情況下不可能獲得較高的 BLEU 得分。
如圖 1 所示,使用有限數量的訓練樣本不可能達到高質量的翻譯準確率。所以微軟提出的方法著重於隻有有限數量訓練樣本的情景,例如,隻有 6000 個訓練樣本。

圖 2: 神經機器翻譯編碼器-解碼器框架中編碼器方麵的改進。
微軟提出的係統使用遷移學習方法將不同源語言中詞彙級別和句子級別的表征共享到一個目標語言中。該設置假設多種源語言包括高資源語言和低資源語言。微軟的主要目標是能夠共享所學的模型,以便幫助低資源語言。該係統架構對神經機器翻譯(NMT)的編碼器-解碼器框架新增了兩個修改,以實現半監督通用神經機器翻譯。主要修改了編碼器部分,如圖 2 所示。
1. 為了支持多語詞級別的共享,詞彙部分通過一個通用詞彙表征(ULR)來共享。
2. 專家模型表征所有源語言句子級別的共享,與其他語言共享一個源編碼器。
這兩種修改使低資源語言能夠利用與較高資源語言相關聯的詞級和句子級表征。
ULR 利用預投影步驟,將在單語語料庫上訓練的所有詞嵌入投影到統一的通用空間中。預投影可以使用種子詞典、小型並行數據或無監督方法來實現。如圖 3 所示,研究者最終得到了所有語言的統一表征:在這個例子中,所有語言都投影到英語表征中。值得注意的是,統一嵌入空間是使用 word2vec 學習到的單語嵌入投影而得的,這對於翻譯任務而言並不是最佳的。
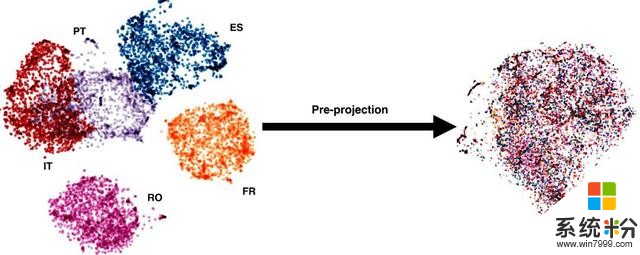
圖 3:ULR 使得為任何語言中的任意單詞實現統一嵌入成為可能。
使用 ULR 可以為任何語言中的任意詞生成統一的嵌入。神經機器翻譯係統使用有限的多語言數據和可選的來自低資源語言的少量數據進行訓練。給定在訓練數據中從未觀察到的任何語言中的任意單詞,目標是對該單詞有合理的表征,以便能夠翻譯這個單詞。微軟提出了一種新型多語言嵌入表征方法,來自任何語言的每個詞都可被表示為通用空間詞嵌入的概率混合。這樣,來自不同語言的語義相似的詞自然就具有相似的表征。該方法基於嵌入空間上的 Key-Query-Value 表征,詳見圖 4。
為表述簡便,假設這麼一個場景,一個使用四種平行語言訓練的多語言係統:西班牙語(ES)、法語(FR)、意大利語(IT)和葡萄牙語(PT)。我們希望使用這個係統來翻譯羅馬尼亞語(RO),它是一種平行數據不足的低資源語言。
研究者對任意給定的羅馬尼亞單詞(例如「pisicile」)執行查詢(query),以從通用嵌入空間中找到類似的單詞,如圖 3 所示。query 是單語嵌入中的詞嵌入;key 是通用嵌入空間中的單詞。value 是在通用空間中表征給定單詞的加權嵌入。ULR 可以處理在平行訓練數據中從未觀察到的任意單詞的無限多語言詞彙表。
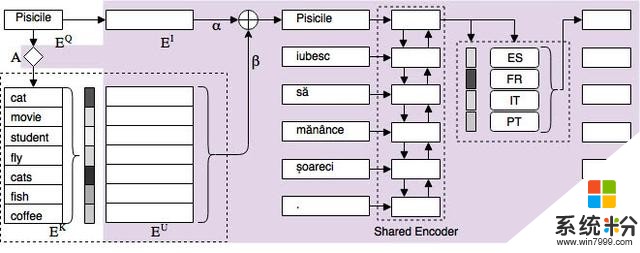
圖 4:使用 MoLE 和 ULR 的係統架構。
一個關鍵問題是,詞嵌入是在單語數據上訓練的,不是針對翻譯任務所進行的優化。微軟研究者向查詢匹配機製添加了一個可訓練的變換矩陣(見圖 4 左上角的 A),其主要目的是針對翻譯任務調整相似度得分。如圖 5 所示,從單語嵌入的角度來看,「autumn」、「fall」、「spring」、「toamnă」(羅馬尼亞語中的秋天)等詞非常相似,而對於翻譯任務來說,「spring」應該不那麼相似。變換矩陣實現了這個目標。
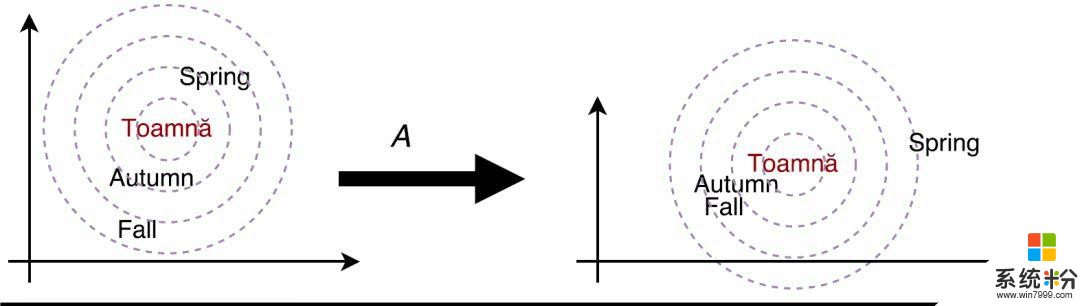
圖 5: 針對翻譯任務調整相似度得分。
當我們朝著通用嵌入表征的目標前進時,編碼器具備語言敏感模塊是至關重要的,這將有助於對不同的語言結構進行建模。微軟的解決方案是用語言專家混合(MoLE)模塊給句子級通用編碼器進行建模。圖 4 在編碼器的最後一層之後增加了 MoLE 模塊。用門控網絡和一組專家網絡來調整每個專家的權重。換句話說,訓練該模型來學習在翻譯低資源語言時從每種語言需要的信息量。MoLE 模塊的輸出將是這些專家的加權和。
NMT 模型學會了在不同的情況下使用不同的語言。在圖 6 中,正方形的顏色越深,任意給定詞條的羅馬尼亞語和其他語言之間的關聯性就越大。很明顯,MoLE 在處理低資源語言單詞時,在語言專家之間進行了有效的轉換。在圖的上半部分,該係統更多地利用了希臘語和捷克語的知識,從德語中利用的知識較少,幾乎沒有利用芬蘭語知識。而在圖的下半部分,意大利語是相關性更強的語言,被使用得更多。有趣的是,該係統學習到,意大利語和捷克語在翻譯羅馬尼亞語時都是有用的,前者和羅馬尼亞語同屬於羅曼語族,而後者不屬於羅曼語族,但由於地理上的接近,它和羅馬尼亞語有顯著的重疊,因而在翻譯羅馬尼亞語時利用度很高。
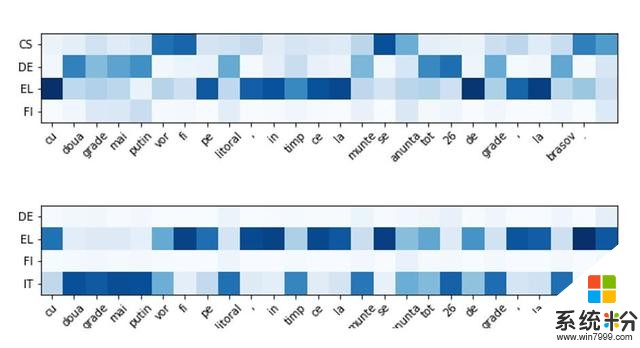
圖 6:MoLE。
在實驗中,研究者在三個場景中嚐試了所提出的模型。第一種是多種語言翻譯場景,該場景中模型僅使用每個語言對的 6000 個平行句子就學會了羅馬尼亞語—英語和拉脫維亞語—英語的翻譯。
在第二個場景中,研究者首先在高資源語言上訓練模型,然後在低資源語言上微調模型。在實驗中,該模型成功地利用 6000 個羅馬尼亞語-英語平行句子對使用零羅馬尼亞語-英語平行數據訓練的多語言係統進行了微調。該係統的 BLEU 值接近 20,隻需兩分鍾就可以在零資源翻譯設置中將預訓練模型微調為適合新語言的模型。
在第三種情況下,研究者調整了一個經過標準阿拉伯語到英語翻譯訓練的係統,使之在完全不使用口語方言平行數據的情況下,就能適用於阿拉伯語口語方言(黎凡特語)。
這些方法幫助微軟擴展 Microsoft Translator 的功能,以支持口語方言和低資源語言(如印度語)。
相關論文將會在 2018 年於新奧爾良舉辦的 NAACL HLT 2018 上展示。
論文:Universal Neural Machine Translation for Extremely Low Resource Languages

摘要:本論文提出了一種新型通用機器翻譯方法,該方法主要針對平行數據有限的語言。該方法利用遷移學習在不同源語言到目標語言的翻譯中共享詞級和句子級表征。詞級表征通過通用詞彙表征(ULR)來支持多語言詞級共享。通過專家模型表征所有源語言句子級別的共享,與其他語言共享一個源編碼器。這使得低資源句子可以利用更高資源語言的詞級和句子級表征。
該方法使用隻有 6000 句子的小型平行語料庫在羅馬尼亞語-英語 WMT2016 中取得了 23 的 BLEU 得分,而使用多語言訓練和回譯的強大基線係統的 BLEU 值是 18。此外,我們證明了該方法在同樣的數據集上、zero-shot 設置中,通過調整預訓練多語言係統達到了接近 20 的 BLEU 值。
相關資訊
最新熱門應用

聚幣交易所app官網安卓
其它軟件175.44M
下載
比特交易所app安卓
其它軟件223.86MB
下載
交易所app蘋果官網
其它軟件34.95 MB
下載
zb交易所蘋果app官網
其它軟件57.91MB
下載
抹茶交易所appios
其它軟件292.97MB
下載
幣贏交易所app最新版蘋果版
其它軟件32.88MB
下載
zg交易所app官網蘋果版本
其它軟件34.95 MB
下載
貨幣交易所app官方蘋果版
其它軟件34.95 MB
下載
幣團交易所
其它軟件43MB
下載
必安交易所官網
其它軟件179MB
下載