
讓AI認得圖像,根據自己的理解給出一段敘述,已經不是什麼新鮮事了。從圖像到文字容易,把這個過程反過來卻很難。
讓AI畫圖有了成熟的解決方案,GAN就是是一個好辦法,但是它通暢並不能按要求隨心所欲造出圖像。
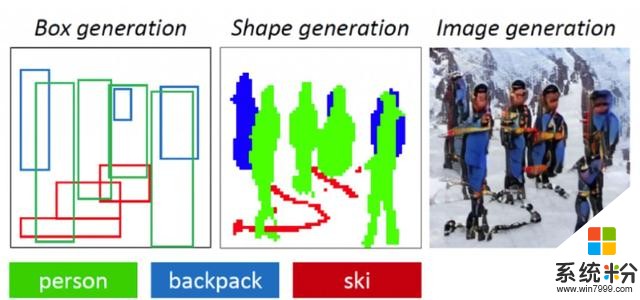
而微軟和京東AI研究院合作提出的ObjGAN就能做到這一點。ObjGAN可以理解一段說明文字,生成草圖布局,並根據確切描述完善圖像細節。
他們的文章《Object-driven Text-to-Image Synthesis via Adversarial Training》已經被正在加州長灘舉辦的學術會議CVPR 2019收錄。
應付多種場景
研究人員在文章中說,ObjGAN的生成器能夠利用細節單詞和對象級信息來逐步細化合成圖像。這使得ObjGAN在生成圖像細節時比之前的研究要強得多。
ObjGAN能生成多種場景下的小狗:一隻棕色小狗躺在床上,或者是一隻黑色小狗叼飛盤。

△左邊是真實場景,中間兩張由P-AttnGAN生成,右邊兩張由ObjGAN生成
如果說簡單場景還看不出ObjGAN的厲害之處,那麼下麵兩幅場景可以說是遠遠把對手甩在身後了。
上一張是酒店房間,下一張是多種蔬菜水果,這兩種場景下的對象非常多,P-AttnGAN已經翻車,除了畫麵混亂外,它還發生了理解錯誤的問題,把藍色屬性錯誤地放在床這個物體上。
為了證明Obj-GAN的泛化能力,研究人員不僅讓它生成真實生活中的場景,甚至連不合常理的結果也可以“強行”生成。
比如讓汽車火車停在水麵上,讓喵咪去叼飛盤或者下海遊泳。

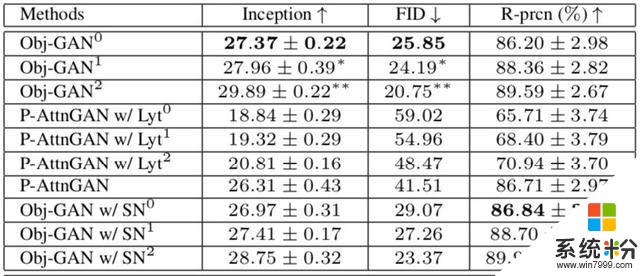
在客觀指標上,Obj-GAN在大規模COCO基準測試的各種指標上優於先前的水平,Inception分數提高到了27,大大高於P-AttnGAN隻有20左右的得分,FID也降低到了25.85。
ObjGAN原理
由文字描述生成圖像的難點在於,如何讓AI理解場景中多個對象之間的關係。ObjGAN通過關注文本描述中最相關的單詞和預先生成的語義布局來合成對象。
以前的方法使用僅為單個對象提供粗粒度信號的圖像-描述對,即使是性能最佳的模型也難以生成語義上有意義包含多個對象的圖片。
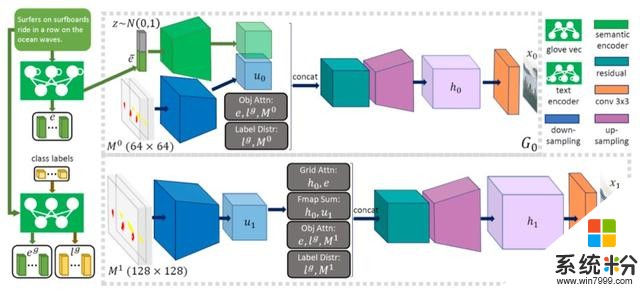
為了克服這些問題,研究人員提出了一種新的對象驅動的注意圖像生成器,將圖像生成分為構圖和精細化圖像兩步。
此外,他們還提出了一種新的基於Fast R-CNN的逐對象鑒別器,提供關於合成對象是否與文本描述和預先生成布局匹配的識別信號。
最後,微軟在這方麵的研究不止ObjGAN一篇論文,他們還與騰訊AI研究院StoryGAN,也是從文本描述生成圖像,同樣被今年的CVPR收錄。
傳送門
論文地址:
https://arxiv.org/abs/1902.10740
PyTorch實現已開源:
https://github.com/jamesli1618/Obj-GAN
— 完 —
誠摯招聘
量子位正在招募編輯/記者,工作地點在北京中關村。期待有才氣、有熱情的同學加入我們!相關細節,請在量子位公眾號(QbitAI)對話界麵,回複“招聘”兩個字。
量子位 QbitAI · 頭條號簽約作者
վ'ᴗ' ի 追蹤AI技術和產品新動態
相關資訊
最新熱門應用

虛擬幣交易app
其它軟件179MB
下載
抹茶交易所官網蘋果
其它軟件30.58MB
下載
歐交易所官網版
其它軟件397.1MB
下載
uniswap交易所蘋果版
其它軟件292.97MB
下載
中安交易所2024官網
其它軟件58.84MB
下載
熱幣全球交易所app邀請碼
其它軟件175.43 MB
下載
比特幣交易網
其它軟件179MB
下載
雷盾交易所app最新版
其它軟件28.18M
下載
火比特交易平台安卓版官網
其它軟件223.89MB
下載
中安交易所官網
其它軟件58.84MB
下載