

在電影《她(HER)》中有這樣一幕:主人公是一位信件撰寫人,人工智能操作係統薩曼莎在得到他的允許後閱讀他的郵件資料,總結出需要保留和刪除的郵件,幫助他修改信件草稿中的錯字,並且與他探討她喜愛的信件片段。與此同時,薩曼莎通過閱讀主人公的海量信息來了解他,也通過閱讀互聯網上的海量數據來了解世界。閱讀這項人類的基本能力,在眾多科幻作品中也成了人工智能的入門標配。
盡管人工智能的熱點此起彼伏,但毫無疑問的是,自然語言處理始終是實現智能、自然人機交互願景裏一塊重要的技術基石。而機器閱讀理解則可以被視為是自然語言處理領域皇冠上的明珠,也是目前該領域的研究焦點之一。
做機器閱讀理解研究的學者想必對由斯坦福大學自然語言計算組發起的SQuAD(Stanford Question Answering Dataset)文本理解挑戰賽並不陌生,它也被譽為“機器閱讀理解界的ImageNet”。諸多來自全球學術界和產業界的研究團隊都積極地參與其中,目前微軟亞洲研究院的自然語言計算研究組持續穩居榜首,與包括艾倫研究院、IBM、Salesforce、Facebook、穀歌以及CMU(卡內基·梅隆大學)、斯坦福大學等在內的全球自然語言處理領域的研究人員,共同推動著自然語言理解的進步。
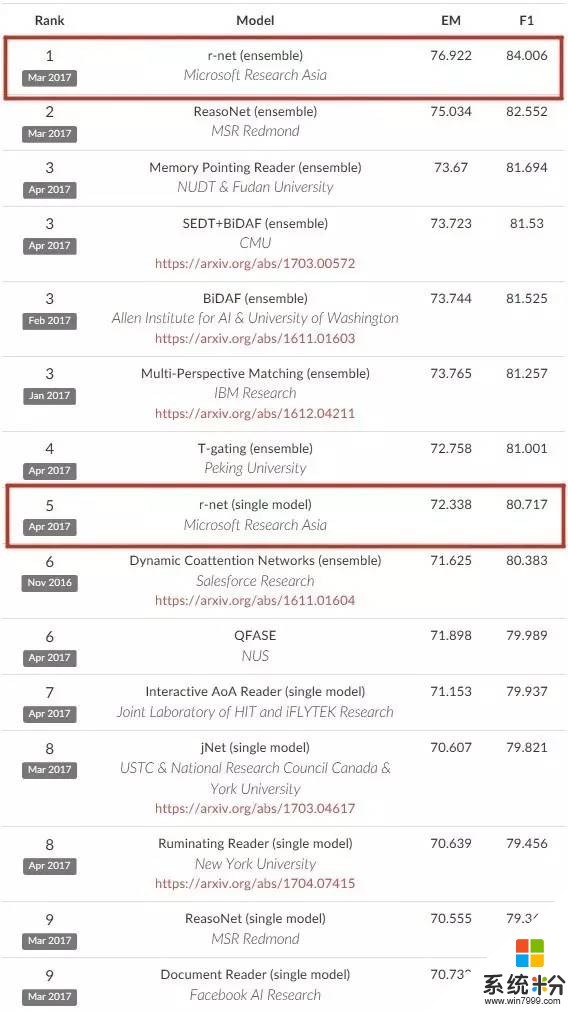
2017年5月8日SQuAD排名和結果截圖,其中微軟亞洲研究院的集成模型(ensemble)和單模型(single model)分列各自排名首位
那麼,SQuAD機器閱讀理解挑戰賽是怎樣進行的呢?SQuAD通過眾包的方式構建了一個大規模的機器閱讀理解數據集(包含10萬個問題),即將一篇幾百(平均100,最多800)詞左右的短文給標注者閱讀,隨後讓標注人員提出最多5個基於文章內容的問題並提供正確答案。SQuAD向參賽者提供訓練集用於模型訓練,以及一個規模較小的數據集作為開發集,用於模型的測試和調優。與此同時,他們提供了一個開放平台供參賽者提交自己的算法,並利用測試集對其進行評分,評分結果將實時地在SQuAD官網上進行更新。
得益於SQuAD所提供的龐大數據規模,參與該項挑戰賽的選手不斷地對成績進行刷新,SQuAD挑戰賽也逐步成為行業內公認的機器閱讀理解標準水平測試。在今年的ACL大會(自然語言處理領域最頂尖的會議之一)的投稿裏,有非常多的論文就是關於這項挑戰賽的研究,其影響力可見一斑。從ACL 2017論文主題的可視分析中可以看到,“reading comprehension(閱讀理解)”是今年ACL錄取論文中最熱門的關鍵詞和任務,廣受自然語言處理領域研究人員的關注。
“雖然偶爾有一兩天其它團隊超過了我們的成績,但我們也有最新的算法能夠很快地進行更新,並取得更好的成績,對於這一點我們的團隊始終十分自信。”機器閱讀理解研究的主要負責人、微軟亞洲研究院自然語言計算研究組主管研究員韋福如表示。
自然語言計算領域皇冠上的明珠
如今,我們在圖像識別、機器翻譯和語音識別等研究領域已經看到了機器學習帶來的顯著成果。例如圖像識別技術對癌細胞病理切片的識別能力已逐步超過人類,目前機器圍棋棋手的棋力已經幾乎無人能敵……在人工智能技術進步向人們展現了各種可喜的成果之後,大家將探尋的目光投向更遠的未來,下一個人工智能技術的增長點在哪裏?
狂熱過後,當我們重新審視人工智能這個問題時,一個最基本的問題可能尚未解決:計算機能夠理解多少我們的語言了?
一些人類學家認為,語言是構建人類文明的基石。在語言之上,我們構建了神話、宗教;構建了城邦,帝國;還構建了信任、信仰。計算機發明以來,層出不窮的編程語言都在教人們學會和計算機對話,而人們理想中的人工智能則是應該主動學習,掌握人類語言的奧義。為此微軟提出了CaaP(Conversation as a Platform,對話即平台)戰略,並將對話式人工智能作為微軟在人工智能領域布局的重點。
計算語言學協會(ACL, Association for Computational Linguistics)候任主席,微軟亞洲研究院副院長周明博士認為:“自然語言處理的基本研究包括分詞、斷句、句法語義分析等等。而機器閱讀理解就是自然語言計算領域皇冠上的明珠。”
一般來說,人們在讀完一篇文章之後就會在腦海裏形成一定的印象,例如這篇文章講的是什麼人,做了什麼事情,出現了什麼,發生在哪裏等等。人們能夠很輕而易舉地歸納出文章中的重點內容。機器閱讀理解的研究就是賦予計算機與人類同等的閱讀能力,即讓計算機閱讀一篇文章,隨後讓計算機解答與文中信息相關的問題。這種對人類而言輕而易舉的能力,對計算機來說卻並非如此。
很長一段時間以來,自然語言處理的研究都是基於句子級別的閱讀理解。例如給計算機一句話,理解句子中的主謂賓、定狀補,誰做了何事等等。但長文本的理解問題一直是研究的一個難點,因為這涉及到句子之間的連貫、上下文和推理等更高維的研究內容。
比如下麵這段文本:
The Rhine (Romansh: Rein, German: Rhein, French: le Rhin, Dutch: Rijn) is a European river that begins in the Swiss canton of Graubünden in the southeastern Swiss Alps, forms part of the Swiss-Austrian, Swiss-Liechtenstein border, Swiss-German and then the Franco-German border, then flows through the Rhineland and eventually empties into the North Sea in the Netherlands. The biggest city on the river Rhine is Cologne, Germany with a population of more than 1,050,000 people. It is the second-longest river in Central and Western Europe (after the Danube), at about 1,230 km (760 mi), with an average discharge of about 2,900 m3/s (100,000 cu ft/s).
(大意:萊茵河是一條位於歐洲的著名河流,始於瑞士阿爾卑斯山,流經瑞士、 奧地利、列支敦士登、法國、德國、荷蘭,最終在荷蘭注入北海。萊茵河上最大的城市是德國科隆。它是中歐和西歐區域的第二長河流,位於多瑙河之後,約1230公裏。)
若針對該段內容提問:What river is larger than the Rhine?(什麼河比萊茵河長?)人們可以輕易地給出答案:Danube(多瑙河)。但目前即使是最佳的係統模型R-NET給出的輸出也並不盡人意,它的回答是:科隆,可見要讓計算機真正地理解文本內容並像人一樣可以對文字進行推理的難度是如此之大。
在回答該問題時,計算機除了要處理文中的指代“it”,還需要算法和模型進一步對“larger than”和“after”這兩個表述進行推理,從而得知Danube是正確答案。此外,由於文中並沒有顯式提到Danube是“river”,所以又加大了係統的推理難度。
但大數據的發展讓學者們看到了這一研究方向的曙光。可獲取的越來越大的文本數據,加上深度學習的算法以及海量的雲計算資源,使得研究者們可以針對長文本做點對點的學習,即對句子、短語、上下文進行建模,這其中就隱藏了一定的推理能力。所以,目前自然語言處理領域就把基於篇章的理解提上研究的議事日程,成為目前該領域的研究焦點之一。而針對上文提及的相關難點,微軟亞洲研究院自然語言計算研究組正在進行下一步的研究和探索。
做頂尖的機器閱讀理解研究
正如前文所說,機器閱讀理解的研究之路始終充滿著許多困難和挑戰。
首先是數據問題。目前基於統計方法(尤其是深度學習模型)的機器閱讀理解的研究離不開大量的、人工標注的數據。在SQuAD數據集推出之前,數據集常常麵臨規模較小,或是質量不佳(因為多是自動生成)的問題,而SQuAD無論是在數據規模還是數據質量上都有一個很大的提升。在基於深度學習方法的研究背景下,數據量不夠就很難做出有效、或是有用的模型,更難對模型進行合理、標準的測試。
另一方麵則是算法問題。之前自然語言處理在做閱讀理解或者是自動問答研究的時候,會把這個研究問題視作一個係統的工程,因而把這個問題分成許多不同的部分。例如先去理解用戶的問題;再去找答案的候選;再將候選答案進行精挑細選、互相比較;最後對候選答案進行排序打分,挑選出最可能的答案或者生成最終的答案。而這個繁複的過程中,似乎其中的每一步都是可以優化的。
但它相應地也會帶來一些問題。
第一,當你分步去優化這其中的每一個過程的時候,你會去研究如何更好地理解這個問題,或是研究如何更好地把答案做對,這些分目標研究結果的整合未必能和“如何將閱讀理解的答案正確找出來”這個目標完全吻合。
第二,如果想做局部的優化,就意味著每一個局部過程都需要相應的(標注)數據,這使得閱讀理解的研究進展緩慢。如果隻使用問題-答案作為訓練數據,中間模塊的優化得到的監督信息不那麼直接,因而很難有效。
結合了上述問題,微軟亞洲研究院自然語言計算研究組的機器閱讀理解研究團隊采用的則是一個端到端的深度學習模型的解決方案,區別於上述的每一個細化環節的具體優化過程,他們采取的方法是把中間環節盡可能的省去,使得整體的過程能夠得到最優效果。
實際上,SQuAD的挑戰賽形式就是讓係統在閱讀完一篇幾百詞左右的短文之後再回答5個基於文章內容的問題。這個問題可能比大家熟知的高考英文閱讀理解,或是托福閱讀考試都要難得多。人們參加的這些考試往往是一個答案被限定住範圍的選擇題。
但是在SQuAD的數據集中,問題和答案具有非常豐富的多樣性。這五個問題中可能涉及文章中的某一個人,某一個地點,或是某一個時間等等實體;也有可能會問一些為什麼(Why)、怎麼樣(How)的問題。後者的答案可能實際上是一句話,甚至是一小段話,因此解決這個問題隻會更加棘手。
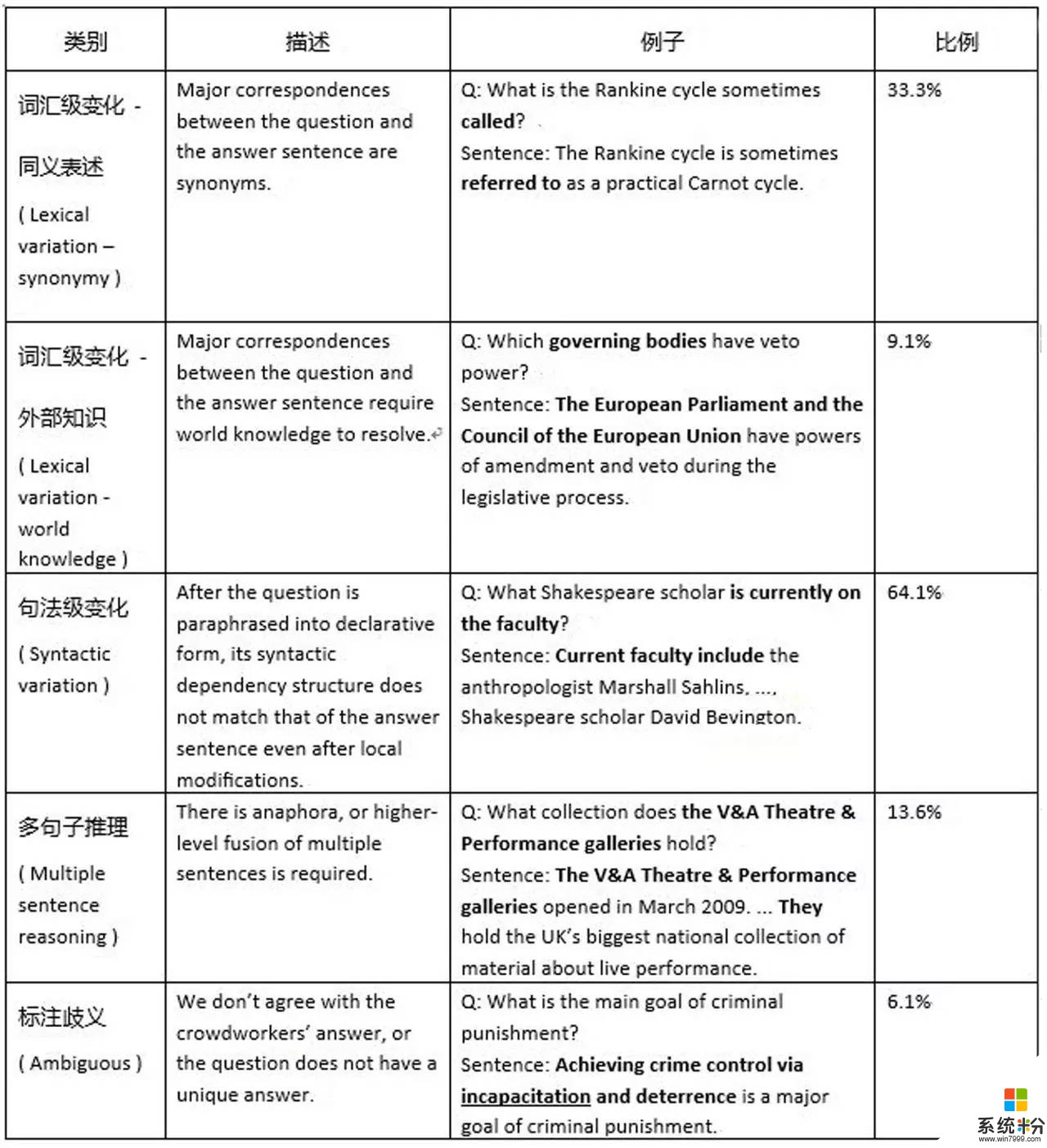
另外,在SQuAD數據集中,除了問題的多樣性之外,研究員們發現還有更多的挑戰。比如語言(包括詞級別和句子級別)的歧義性,對於同一個意思,問題和短文會用不同的詞語或者句型表述(在標注指南中就明確要求標注者盡可能使用不同的表述)。另一個很有難度的挑戰是對於有些問題,找到正確答案需要用到整篇短文中的不同句子的信息,進而對這些信息進行聚合和比較才能最終得出正確的答案。當然,也有一部分問題需要用到比較複雜的推理、常識和世界知識,麵對這類問題就更是難以處理。下表是發布SQuAD數據集一文中給出的總結。
目前SQuAD挑戰賽采用兩個評價標準來對參與係統的結果進行評測。由人工標注的答案作為標準,係統自動依據準確性和相似度兩個不同的維度進行打分,較客觀地保證了評分係統的公平性。微軟亞洲研究院團隊在這兩個不同維度的評價標準上均取得了最優的成績,其準確度達到了76.922%,相似度達到了84.006%,高出第二名近兩個百分點。
R-NET: 基於深度神經網絡的端到端係統
為了研究機器閱讀理解的問題,包括韋福如和楊南等在內的研究團隊試圖去建模人做閱讀理解的過程。他們采用了R-NET,一個多層的網絡結構,分別從四個層麵對整個閱讀理解任務的算法進行了建模。
我們在做閱讀理解的過程中,一個常見的順序是這樣的:
首先閱讀整篇文章,對文章有一個初步理解之後再去審題,從而對問題也有了一定認知。
第二步,可能就需要將問題和文中的部分段落和內容做一些關聯。例如題幹中出現的某些關鍵已知信息(或證據)的,找出一些候選答案,舉例來說:如果問題問的信息是時間,那麼文中出現的與時間相關的信息就可能是候選答案。
第三步,當我們將候選答案與問題進行對應之後,我們還需要綜合全文去看待這些問題,進行證據的融合來輔證答案的正確性。
最後一步,就是針對自己挑出的答案候選進行精篩,最終寫下最正確的答案。
有鑒於此,研究組提出的模型也就分為這樣的四層。
最下麵的一層做表示學習,就是給問題和文本中的每一個詞做一個表示,即深度學習裏的向量。這裏研究組使用的是多層的雙向循環神經網絡。
第二步,就是將問題中的向量和文本中的向量做一個比對,這樣就能找出那些問題和哪些文字部分比較接近。接下來,將這些結果放在全局中進行比對。這些都是通過注意力機製(attention)達到的。
最後一步,針對挑出的答案候選區中的每一個詞彙進行預測,哪一個詞是答案的開始,到哪個詞是答案的結束。這樣,係統會挑出可能性最高的一段文本,最後將答案輸出出來。
整個過程就是一個基於以上四個層麵的神經網絡的端到端係統(見下圖)。
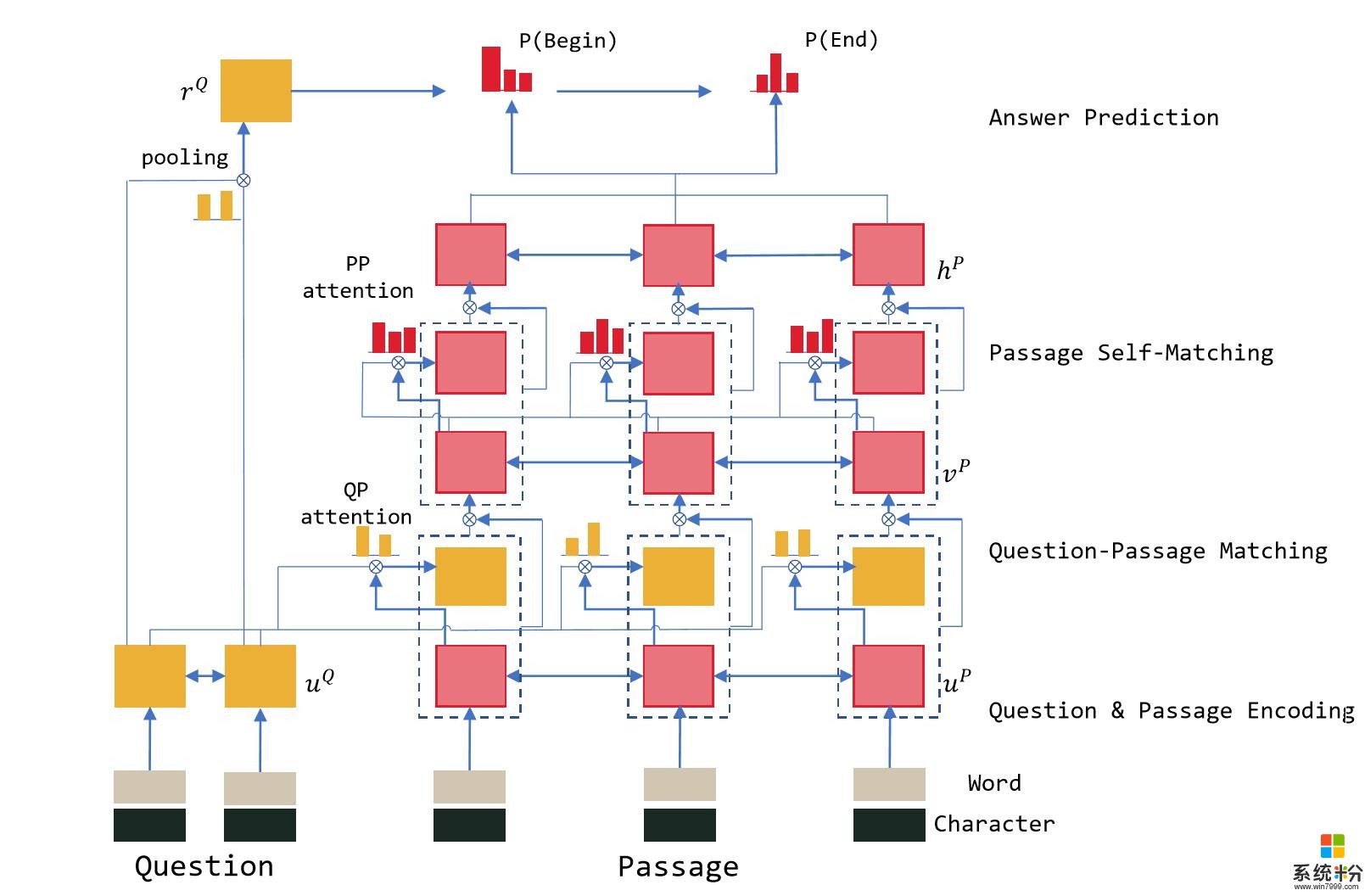
微軟亞洲研究院提出的R-NET算法的網絡結構圖。其中最為獨特的部分是第三層文章的自匹配網絡(Self-Matching Networks),更多細節請點擊此鏈接,參考技術報告。
關於這項研究的論文已經被ACL 2017錄用,並獲得審稿者的一致好評。
SQuAD數據集於2016年9月份發布了正式版。一經推出,微軟亞洲研究院自然語言計算研究組就敏銳地判斷這是一個非常重要的數據集,將會極大地推動機器閱讀理解的研究,並將在研究界和工業界產生積極深遠的影響。10月,研究團隊就第一次提交了他們的研究成果,並且取得了第一名的好成績,而後續幾個月的數次提交,則是在不斷地刷新著自己的成績。對於研究團隊來說,這其實是一個試錯的過程,團隊每天都會討論總結當天的試錯成果,有新的想法就不斷嚐試。
未來的方向
提及機器閱讀理解未來值得探索的方向,韋福如分享了他的三點看法。他認為一方麵基於深度學習的算法和模型還有很大的空間,適合機器閱讀理解的網絡結構值得在SQuAD類似的數據集上進一步嚐試和驗證。具體來說,通過對R-NET目前處理不好的問題的進一步分析,能否提出可以對複雜推理進行有效建模,以及能把常識和外部知識(比如知識庫)有效利用起來的深度學習網絡,是目前很有意義的研究課題。另外,目前基於深度學習的閱讀理解模型都是黑盒的,很難直觀地表示機器進行閱讀理解的過程和結果,因而可解釋性的深度學習模型也將是很有趣的研究方向。
其次,人類理解文本的能力是多維度的,結合多任務(尤其是閱讀理解相關的任務,例如閱讀理解之後進行摘要和問答)的模型非常值得關注和期待。更進一步,雖然SQuAD提供了比較大的人工標注數據集,如何有效且高效地使用未標注的數據也是非常值得期待的研究課題和方向。
最後從任務上看,目前SQuAD的任務定義中答案是原文的某個子片段,而實際中人可能讀完文章之後需要進行更複雜的推理、並組織新的文字表達出來。
相關資訊
最新熱門應用

智慧笑聯app官網最新版
生活實用41.45MB
下載
盯鏈app安卓最新版
生活實用50.17M
下載
學有優教app家長版
辦公學習38.83M
下載
九號出行app官網最新版
旅行交通28.8M
下載
貨拉拉司機版app最新版
生活實用145.22M
下載
全自動搶紅包神器2024最新版本安卓app
係統工具4.39M
下載
掃描王全能寶官網最新版
辦公學習238.17M
下載
海信愛家app最新版本
生活實用235.33M
下載
航旅縱橫手機版
旅行交通138.2M
下載
雙開助手多開分身安卓版
係統工具18.11M
下載