

翻譯|AI科技大本營(rgznai100)
參與 | 周翔,尚岩奇
他可謂神童。
2009年,在 IEEE 舉辦的 CVPR 大會上,還在微軟亞研院(MSRA)實習的何愷明的第一篇論文“Single Image Haze Removal Using Dark Channel Prior”豔驚四座,獲最佳論文,這是第一次完全由中國人組成的團隊獲得該獎項。
2016年,何愷明所在團隊的另一篇論文“Deep Residual Learning for Image Recognition”再獲 CVPR 最佳論文獎。
同年 8 月,這位 2003 年的廣東省理科高考狀元離開 MSRA,加入 FAIR(Facebook AI Research),擔任科學家。
當然,除了這些不凡的履曆之外,何愷明還是 Faster R-CNN 和 Mask R-CNN 的主要貢獻者。有媒體評價稱,何愷明用自己的行動打破了外界認為高考狀元高分低能的偏見。(當然,本營長還是羨慕高考狀元滴,木有偏見)
近日,AI科技大本營在 arXiv 上發現了何愷明所在 FAIR 團隊的最新力作:“Focal Loss for Dense Object Detection(用於密集對象檢測的 Focal Loss 函數)”。
這篇論文到底有什麼重大意義呢?
清華大學孔濤博士在知乎上這麼寫道:
目標的檢測和定位中一個很困難的問題是,如何從數以萬計的候選窗口中挑選包含目標物的物體。隻有候選窗口足夠多,才能保證模型的 Recall。
目前,目標檢測框架主要有兩種:
一種是 one-stage ,例如 YOLO、SSD 等,這一類方法速度很快,但識別精度沒有 two-stage 的高,其中一個很重要的原因是,利用一個分類器很難既把負樣本抑製掉,又把目標分類好。
另外一種目標檢測框架是 two-stage ,以 Faster RCNN 為代表,這一類方法識別準確度和定位精度都很高,但存在著計算效率低,資源占用大的問題。
Focal Loss 從優化函數的角度上來解決這個問題,實驗結果非常 solid,很讚的工作。
也就是說,one-stage 檢測器更快更簡單,但是準確度不高。two-stage 檢測器準確度高,但太費資源。
魚和熊掌,不可兼得。
如果想要兩者兼得,如何實現?
何凱明團隊提出了用 Focal Loss 函數來訓練。
因為,他在訓練過程中發現,類別失衡是影響 one-stage 檢測器準確度的主要原因。那麼,如果能將“類別失衡”這個因素解決掉,one-stage 不就能達到比較高的識別精度了嗎?
於是在研究中,何凱明團隊采用 Focal Loss 函數來消除“類別失衡”這個主要障礙。
結果怎樣呢?
為了評估該損失的有效性,該團隊設計並訓練了一個簡單的密集目標檢測器—RetinaNet。試驗結果證明,當使用 Focal Loss 訓練時,RetinaNet 不僅能趕上 one-stage 檢測器的檢測速度,而且還在準確度上超越了當前所有最先進的 two-stage 檢測器。
可謂魚和熊掌兼得之。
具體怎麼實現呢?以下是該論文簡介,Enjoy!詳細信息,請查閱原文鏈接。

摘要
目前準確度最高的目標檢測器采用的是一種常在 R-CNN 中使用的 two-stage 方法,這種方法將分類器應用於一個由候選目標位置組成的稀疏樣本集。相反,one-stage 檢測器則應用於一個由可能目標位置組成的規則密集樣本集,而且更快更簡單,但是準確度卻落後於 two-stage 檢測器。在本文中,我們探討了造成這種現象的原因。
我們發現,在訓練密集目標檢測器的過程中出現的嚴重的 foreground-background 類別失衡,是造成這種現象的主要成因。我們解決這種類別失衡(class imbalance)的方案是,重塑標準交叉熵損失,使其減少分類清晰的樣本的損失的權重。Focal Loss 將訓練集中在一個稀疏的困難樣本集上,並防止大量簡單負樣本在訓練的過程中淹沒檢測器。為了評估該損失的有效性,我們設計並訓練了一個簡單的密集目標檢測器—RetinaNet。試驗結果證明,當使用 Focal Loss訓練時,RetinaNet 不僅能趕上 one-stage 檢測器的檢測速度,而且還在準確度上超越了當前所有最先進的 two-stage 檢測器。
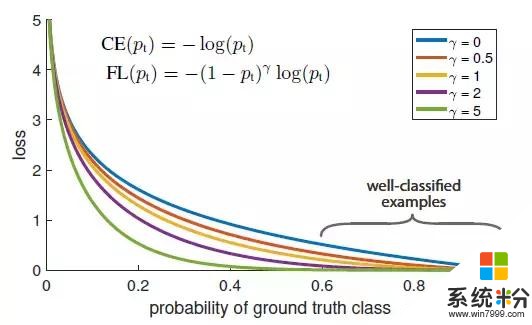
損失函數 Focal Loss(焦點損失)
圖1:我們提出了一種新的損失函數 Focal Loss(焦點損失),這個損失函數在標準的交叉熵標準上添加了一個因子 (1- pt) γ 。設定 γ > 0 可以減小分類清晰的樣本的相對損失(pt > .5),使模型更加集中於困難的錯誤分類的樣本。試驗證明,在存在大量簡單背景樣本(background example)的情況下,我們提出的 Focal Loss 函數可以訓練出準確度很高的密集對象檢測器。
1 簡介
當前最優秀的目標檢測器使用的都是一種由 proposal 驅動的 two-stage 機製。和在 R-CNN 框架中一樣,第一個階段生成一個候選目標位置組成的稀疏樣本集,第二個階段使用一個卷積神經網絡將各候選位置歸至 foreground 類別或 background 類別。隨著一些列的進步,這個 two-stage 框架可以在難度極高的 COCO benchmark 上一直保持很高的準確度。
既然 two-stage 檢測器的結果這麼好,那麼一個很自然的問題是:簡單的 one-stage 檢測器是否也能實現類似的準確度? one-stage 檢測器主要應用在一個由目標位置(object locations)、尺度(scales)和長寬比(aspect ration)組成的規則密集樣本集上。最近對 one-stage 檢測器(如 YOLO 和 SSD)進行的試驗都得出了優秀的結果,相比最優秀的 two-stage 方法,得出的檢測器檢測速度更快,而且能實現 10%- 40% 的準確度。
本文進一步提高了 one-stage 檢測器的性能:我們設計出了一個 one-stage 目標檢測器,並首次達到了更複雜的 two-stage 檢測器所能實現的最高 COCO 平均精度,例如(特征金字塔網絡,Feature Pyramid Network ,FPN)或 Faster R-CNN 的 Mask R-CNN 變體。我們發現訓練過程中的類別失衡是阻礙單階段檢測器實現這個結果的主要障礙,並提出了一種新的損失函數來消除這個障礙。
通過兩階段的級聯(cascade)和采樣的啟發(sampling heuristics),我們解決了像 R-CNN 檢測器的類別失衡問題。候選階段(如Selective Search、EdgeBoxes 、DeepMask 和 RPN)可以快速地將候選目標位置的數目縮至更小(例如 1000-2000),過濾掉大多數背景樣本。在第二個分類階段中,應用抽樣啟發法(sampling heuristics),例如一個固定的前景樣本背景樣本比(1:3),或者在線困難樣本挖掘法(online hard example mining),在 foreground 樣本和 background 樣本之間維持可控的平衡。
相反,one-stage 檢測器則必須處理一個由圖像中規則分布的候選目標位置組成的大樣本集。在實踐中,目標位置的總數目通常可達 10 萬左右,並且密集覆蓋空間位置、尺度和長寬比。雖然還可以應用類似的抽樣啟發法,但是這些方法可能會失效,如果容易分類的背景樣本仍然支配訓練過程話。這種失效是目標識別中的一個典型問題,通常使用 bootstrapping 或困難樣本挖掘來解決。
在本文中,我們提出了一個新的損失函數,它可以替代以往用於解決類別失衡問題的方法。這個損失函數是一個動態縮放的交叉熵損失函數,隨著正確分類的置信度增加,函數中的比例因子縮減至零,見圖1。在訓練過程中,這個比例因子可以自動地減小簡單樣本的影響,並快速地將模型集中在困難樣本上。
試驗證明,Focal Loss 函數可以使我們訓練出準確度很高的 one-stage 檢測器,並且在性能上超越使用抽樣啟發法或困難樣本挖掘法等以往優秀方法訓練出的 one-stage 檢測器。最後,我們發現 Focal Loss 函數的確切形式並不重要,並且證明了其他實例(instantiations)也可以實現類似的結果。
為了證明這個 Focal Loss 函數的有效性,我們設計了一個簡單的 one-stage 目標檢測器—RetinaNet,它會對輸入圖像中目標位置進行密集抽樣。這個檢測器有一個高效的 in-network 特征金字塔(feature pyramid),並使用了錨點盒(anchor box)。我們在設計它時借鑒了很多種想法。RetinaNet 的檢測既高效又準確。我們最好的模型基於 ResNet-101- FPN 骨幹網,在 5fps 的運行速度下,我們在 COCO test-dev 上取得了 39.1 AP 的成績,如圖2 所示,超過目前公開的單一模型在 one-stage 和 two-stage 檢測器上取得的最好成績。
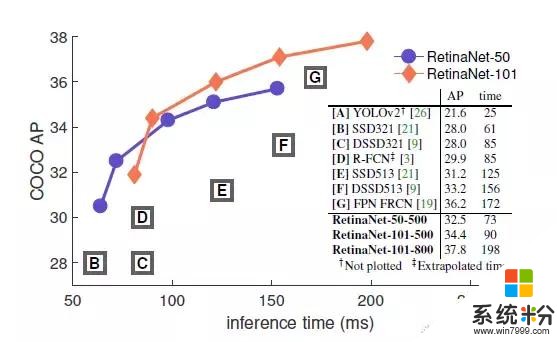
圖2:橫坐標是檢測器在COCO test-dev 上的檢測速度(ms),縱坐標是準確度(AP: av
在 Focal Loss 的作用下,我們簡單的 one-stage RetinaNet 檢測器打敗了先前所有的 one-stage 檢測器和 two-stage 檢測器,包括目前成績最好的 Faster R-CNN係統。我們在圖 2 中按 5 scales(400-800 像素)分別用藍色圓圈和橙色菱形表示了 ResNet-50-FPN 和 ResNet-101-FPN 的 RetinaNet 變體。忽略準確度較低的情況(AP < 25),RetinaNet 的表現優於當前所有的檢測器,訓練時間更長時的檢測器達到了 39.1 AP 的成績。
2 Focal Loss
首先,我們介紹下二進製分類(binary classification)的交叉熵(CE)損失開:
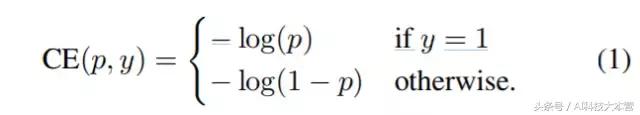
公式1中,y∈{±1} 指定了 ground-truth class,p∈[0,1] 是模型對於標簽為 y = 1 的類的估計概率。為了方便起見,我們定義 pt 為:
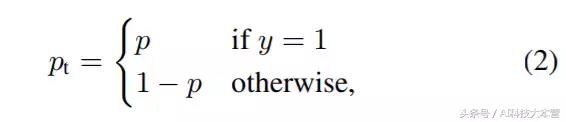
公式2可以轉寫稱:
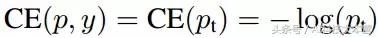
解決 class imbalance 的常見方法是分別為 class 1 和 class -1 引入加權因子 α∈[0; 1]、1-α。 α-balanced 的CE損耗可寫為:
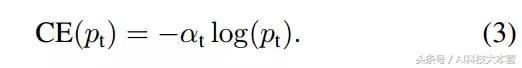
更正式地,我們建議為交叉熵損失增加一個調節因子(1 - pt)γ,其中 γ≥0。於是 Focal Loss 可定義為:
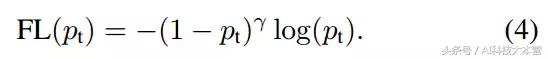
以下是我們在實踐中使用的 Focal Loss:
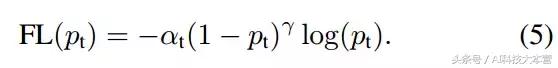
3 RetinaNet 檢測器
RetinaNet 是由一個骨幹網絡和兩個特定任務子網組成的單一網絡。骨感網絡負責在整個輸入圖像上計算卷積特征圖,並且是一個現成的我卷積網絡。 第一個子網在骨幹網絡的輸出上執行卷積對象分類;第二個子網執行卷積邊界框回歸。如下圖所示。
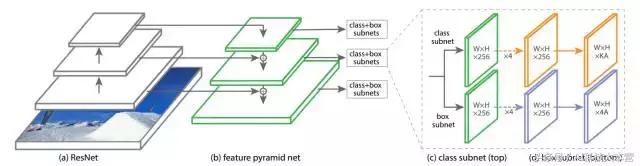
圖3:one-stage RetinaNet 網絡結構
4 訓練
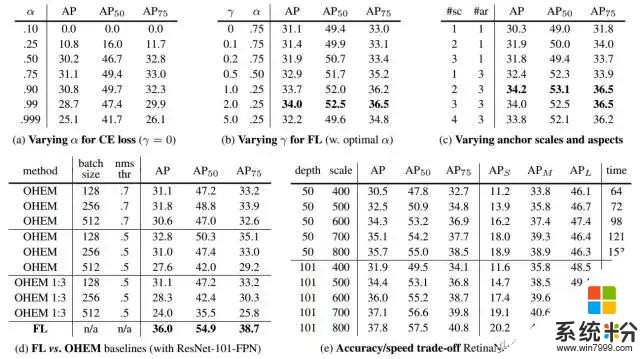
表1: RetinaNet 和 Focal Loss 剝離試驗(ablation experi
5 試驗
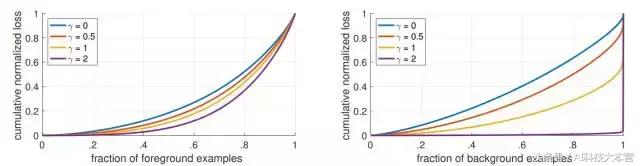
圖4:收斂模型的不同 γ 值的正、負樣本的歸一化損失的累積分布函數。
改變 γ 對於正樣本的損失分布的影響很小。 然而,對於負樣本來說,大幅增加 γ 會將損失集中在困難的樣本上,而不是容易的負樣本上。
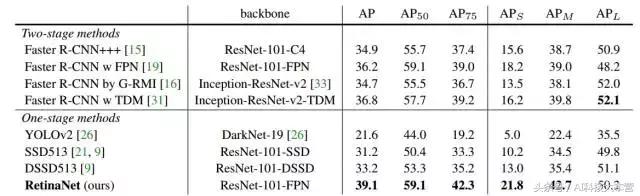
表2:目標檢測單模型結果(邊界框AP)VS COCO test-dev 最先進的方法
6 結論
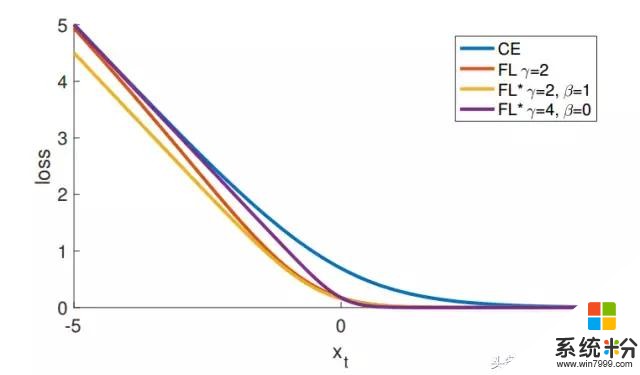
圖5: 作為 xt = yx 的函數,Focal Loss 變體與交叉熵相比較。
原來的 FL(Focal Loss)和替代變體 FL* 都減少了較好分類樣本的相對損失(xt> 0)。
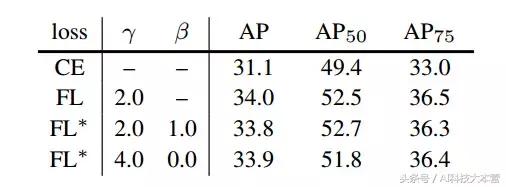
表3:FL 和 FL* VS CE(交叉熵) 的結果
論文地址
https://arxiv.org/abs/1708.02002
相關資訊
最新熱門應用

hotbit交易平台app安卓版
其它軟件223.89MB
下載
bilaxy交易所app
其它軟件223.89MB
下載
avive交易所官網最新版
其它軟件292.97MB
下載
必安交易所app官網版安卓
其它軟件179MB
下載
富比特交易所app安卓版
其它軟件34.95 MB
下載
美卡幣交易所安卓版
其它軟件16.3MB
下載
幣幣交易所app官網
其它軟件45.35MB
下載
熱幣交易所最新版本app
其它軟件287.27 MB
下載
zbg交易所官方ios
其它軟件96.60MB
下載
拉菲交易所安卓版
其它軟件223.89MB
下載