
人工智能發展到了哪一步?
小卓用一篇閱讀理解告訴你答案:
據CNN、CNET、彭博社等多家外媒報道,1月11日,微軟和阿裏巴巴開發的AI模型在斯坦福閱讀測試中首次勝過人類。這是繼國際象棋、橋牌等遊戲之後,機器再次戰勝人類。
機器精準度匹配首次超越人類
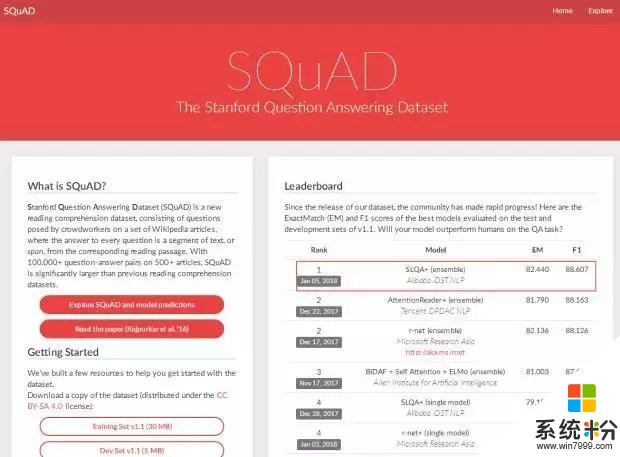
SQuAD比賽,是由斯坦福大學發起的機器閱讀理解領域頂級賽事,它構建了一個大規模的機器閱讀理解數據集(包含10萬個問題),文章來源於500多篇維基百科文章。機器在閱讀完數據集中的一篇短文之後,需要回答若幹個基於文章內容的問題,然後與標準答案進行比對,得出精確匹配(Exact Match)和模糊匹配(F1-score)的結果。
通過這套試題梳理出線索,可看出機器學習模型是否能夠在經過大量信息處理後給出問題的確切答案。這些題目所構成的試卷被認為是當前世界檢測機器閱讀水平的最權威標準之一。
此次測試中,參賽公司讓各自的人工智能係統解答斯坦福問答數據集的提問,然後,該數據集評估閱讀理解能力,將智能係統與普通人的答案進行比較,並進行排名。結果,微軟、阿裏巴巴分別以82.650和82.440的精準率打破了世界紀錄,並且超越了人類82.304的成績,刷新了在SQuAD上的排名。
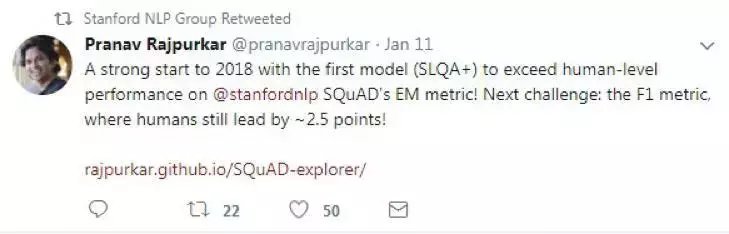
SQuAD的負責人Pranav Rajpurkar在Twitter上表示,“2018年是一個強勁的開始,第一個模型(阿裏巴巴iDST團隊提交的SLQA +)在精準度匹配上超越人類表現!下一個挑戰:模糊匹配,人類仍然領先2.5分!”
理解和分析是機器與人的最大區別
機器閱讀理解,雖然看起來僅是讓AI進行一場考試,但確實自然語言處理(NPL)技術中,除了語音判斷、語義理解之後更大的挑戰,即如何讓機器理解全文語境。因為閱讀理解問題,不止要處理語音和語義,還要關注和理解詞彙、語句、篇章結構、思維邏輯、輔助語句和關鍵句等元素構成的複雜組織網絡。
正如做一份閱讀理解題,斯坦福閱讀理解數據集中會提問:“德國首相出生於哪一年?”緊接著,根據上下文理解,“她的出生地又是哪裏?”再比如,“喬治·史密斯是否是美國國籍?”那麼這個問題在原文中可尋究的出處是“喬治·史密斯出生於夏威夷,位於美國。”這其中的關鍵在於,處理閱讀理解相關問題,需要的不僅是人工智能的計算能力,更多的是理解和分析能力,而這恰恰是機器與人最大的區別。
值得寬慰的是:從目前來看,機器在複雜語言的理解方麵,仍然很難與人類相匹敵。
相關資訊
最新熱門應用

bicc交易所app蘋果
其它軟件45.94MB
下載
香港ceo交易所官網
其它軟件34.95 MB
下載
歐意錢包app
其它軟件397.1MB
下載
aibox交易所app
其它軟件112.74M
下載
btcc交易平台app
其它軟件26.13MB
下載
zb交易平台官網
其它軟件223.89MB
下載
芝麻交易平台官方安卓版
其它軟件223.89MB
下載
易歐交易所app官網安卓蘋果
其它軟件397.1MB
下載
滿幣交易所app
其它軟件21.91MB
下載
天秤幣交易所蘋果app
其它軟件88.66MB
下載