
人工智能的閱讀能力在某些方麵已經超越了人類,微軟的 R-Net 就是達到了這一裏程碑的人工智能之一。近日,穀歌工程師 Sachin Joglekar 在 Medium 上發文對 R-Net 進行了直觀的介紹。
R-Net 論文:https://www.microsoft.com/en-us/research/wp-content/uploads/2017/05/r-net.pdf
今年 1 月 13 日,很多媒體的新聞報道稱微軟和阿裏巴巴開發的人工智能在 SQuAD 數據集測試上,閱讀能力上超越了人類。盡管這並不完全準確,但這些公司所開發的模型確實能在某些閱讀任務的某些指標上超越人類水平。這篇文章為微軟實現這一成果背後的人工智能 R-Net 提供了一個直觀的介紹。
首先,給出閱讀問題……
給定一個段落 P:
「特斯拉於 1856 年 7 月 10 日(舊曆法的 6 月 28 日)出生於奧地利帝國斯米連村(現屬克羅地亞)的一個塞族家庭。他的父親米盧廷·特斯拉是一位塞爾維亞東正教神父。特斯拉的母親是久卡·特斯拉(娘家姓為 Mandić),她的父親也是一位東正教神父;:10 她非常擅長製作家庭手工工具、機械器具並且具有記憶塞爾維亞史詩的能力。久卡從沒接受過正規教育。尼古拉將自己的記憶和創造能力歸功於他母親的遺傳和影響。特斯拉的祖先來自塞爾維亞西部靠近黑山的地方。:12」
然後詢問一個問題 Q:
「特斯拉的母親具有怎樣的特殊能力?」
然後提供一部分連續文本作為答案 A:
「擅長製作家庭手工工具、機械器具並且具有記憶塞爾維亞史詩的能力」

斯坦福問答數據集(SQuAD)包含大約 500 篇文章,涉及的問答對數量接近 10 萬(上麵給出的例子就取自其中)。
在我們介紹微軟的用於閱讀理解的方法之前,我們先簡要介紹一下他們論文中大量使用的兩個概念:
1. 循環神經網絡(RNN)
RNN 是一種特殊的神經網絡,可用於分析時間(或序列)數據。標準的前饋神經網絡沒有記憶的概念,而 RNN 則通過使用「反饋的」語境向量(context vector)而將這一概念整合了進來:
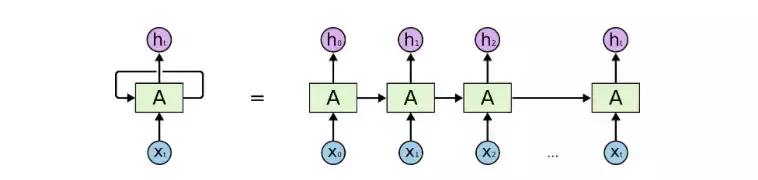
圖 1:一種典型的 RNN
從本質上講,其在任何時間步驟 t 的輸出都是過去語境和當前輸入的一個函數。
雙向 RNN(BiRNN)是一種特殊的 RNN。標準 RNN 是通過「記憶」過去的數據來記憶曆史語境,而 BiRNN 還會從反方向進行遍曆以理解未來的語境:
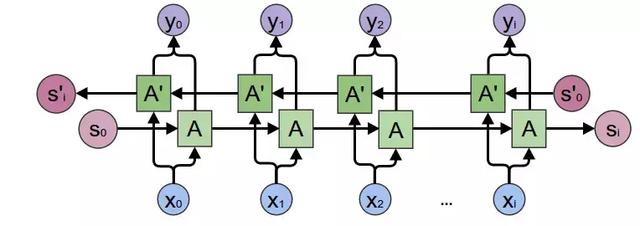
圖 2:BiRNN
需要指出,盡管 RNN 理論上可以記住任何長度的曆史,但通常來說整合短期語境比整合長期信息(相距 20-30 步以上)更好。
注:R-Net 使用 RNN(更具體來說是門控循環單元)的主要目的是模擬「閱讀」文本段落的動作。
2. 注意力(attention)
神經網絡中的注意力是根據人類重點關注視覺輸入中的特定部分並大略查看其餘部分的觀看方式而建模的。
注意力可以用在這樣的應用中:你的數據點集合中並非所有部分都與當前的任務有關。在這樣的情況下,注意力是作為該集合中所有點的 softmax 加權平均而計算的。其權重本身則是作為 1)向量集和 2)某個語境的某個非線性函數而計算的。

圖 3:在「飛盤」的語境下,網絡會重點關注實際的飛盤和與之相關的對象,同時略過其餘部分。
注:R-Net 使用了注意力來在另一些文本的語境下突出文本的某些部分。
R-Net
從直觀上講,R-Net 執行閱讀理解的方式與你我進行閱讀理解的方式相似:通過多次(準確地說是 3 次)「閱讀」(應用 RNN)文本以及在每次迭代中越來越好地「微調」(使用注意力)各詞的向量表征。
讓我們分開解讀其中的每一次過程……
第一次閱讀:略覽
我們從標準的 token(即詞)向量開始,使用了來自 Glove 的詞嵌入。但是,人類通常理解一個詞在其周圍詞所構成的語境中的含義。
比如這兩個例子:「May happen」和「the fourth of May」,其中「May」的含義取決於周圍的詞。另外也要注意背景信息可以來自前向,也可以來自反向。因此,我們在標準詞嵌入之上使用了 BiRNN,以得到更好的向量。
問題和段落上都會應用這個過程。
第二次閱讀:基於問題的分析
在第二次閱讀中,該網絡會使用文本本身的語境來調節來自段落的詞表征。
讓我們假設你已經在該段落的重點位置了:
「……她非常擅長製作家庭手工工具、機械器具並且具有記憶塞爾維亞史詩的能力。久卡從沒接受過正規教育……」
在有了「製作」的前提下,如果你在問題 token 上應用注意力,你可能會重點關注:
「特斯拉的母親具有怎樣的特殊能力?」
類似地,網絡會調整「製作」的向量,使之與「能力」在語義上靠得更近。
該段落中的所有 token 都會完成這樣的操作——本質上講,R-Net 會在問題的需求和文章的相關部分之間形成鏈接。原論文將這個部分稱為門控式基於注意力的 RNN(Gated Attention-based RNN)。
第三次閱讀:有自知的完整的段落理解
在第一次閱讀過程中,我們在 token 臨近周圍詞的語境中對這些 token 進行了理解。
在第二次閱讀過程中,我們根據當前問題改善了我們的理解。
現在我們要鳥瞰整個段落,以定位那些對回答問題真正有幫助的部分。要做到這一點,光是有周圍詞的短期語境視角是不夠的。考慮以下部分中突出強調的詞:
特斯拉的母親是久卡·特斯拉(娘家姓為 Mandić),她的父親也是一位東正教神父;:10 她非常擅長製作家庭手工工具、機械器具並且具有記憶塞爾維亞史詩的能力。久卡從沒接受過正規教育。尼古拉將自己的記憶和創造能力歸功於他母親的遺傳和影響。
這都是指特斯拉的母親所具有的能力。但是,盡管前者確實圍繞描述該能力的文本(是我們想要的),但後麵的能力則是將它們與特斯拉的才能關聯了起來(不是我們想要的)。
為了定位答案的正確起始和結束位置(我們會在下一步解決這個問題),我們需要比較段落中具有相似含義的不同詞,以便找到它們的差異之處。使用單純的 RNN 是很難完成這個任務的,因為這些突出強調的詞相距較遠。
為了解決這個問題,R-Net 使用了所謂「自匹配注意力(Self-Matched Attention)」。
為什麼需要自匹配?
在應用注意力時,我們通常會使用一些數據(比如一個段落詞)來衡量一個向量(比如問題詞)的集合。但在這個迭代過程中,我們會使用當前的段落詞來衡量來自該段落本身的 token。這有助於我們將當前詞與段落其餘部分中具有相似含義的其它詞區分開。為了增強這個過程,這個閱讀階段是使用一個 BiRNN 完成的。
在我看來,使用自匹配注意力這個步驟是 R-Net 最「神奇」的地方:使用注意力來比較同一段落中相距較遠的詞。
最後一步:標記答案
在最後一步,R-Net 使用了一種指針網絡(Pointer Networks)的變體來確定答案所處的起始和結束位置。簡單來說:
我們首先根據問題文本計算另一個注意力向量。這被用作這一次迭代的「起始語境(starting context)」。使用這個知識,再為該起始索引計算一組權重(為該段落中的每個詞)。得到最高權重的詞作為其答案的「起始位置」。
除了權重之外,這個兩步 RNN 還會返回一個新的語境——其中編碼了有關該答案的起始的信息。
再將上述步驟重複一次——這一次使用新的語境而不是基於問題的語境,用以計算該答案的結束位置。
搞定!我們得到解答了!(實際上,我們上述例子中給出的答案就是 R-Net 實際得出的答案。)
如果你對 R-Net 的詳細細節感興趣,請閱讀他們的論文。如果代碼能幫助你更好地理解(至少對我而言是如此),請參閱 YerevaNN 試圖用 Keras 重建 R-Net 的精彩博文:http://yerevann.github.io/2017/08/25/challenges-of-reproducing-r-net-neural-network-using-keras/。
相關資訊
最新熱門應用

bicc數字交易所app
其它軟件32.92MB
下載
比特國際網交易平台
其它軟件298.7 MB
下載
熱幣交易所app官方最新版
其它軟件287.27 MB
下載
歐昜交易所
其它軟件397.1MB
下載
vvbtc交易所最新app
其它軟件31.69MB
下載
星幣交易所app蘋果版
其它軟件95.74MB
下載
zg交易所安卓版app
其它軟件41.99MB
下載
比特幣交易app安卓手機
其它軟件179MB
下載
福音交易所蘋果app
其它軟件287.27 MB
下載
鏈易交易所官網版
其它軟件72.70MB
下載