
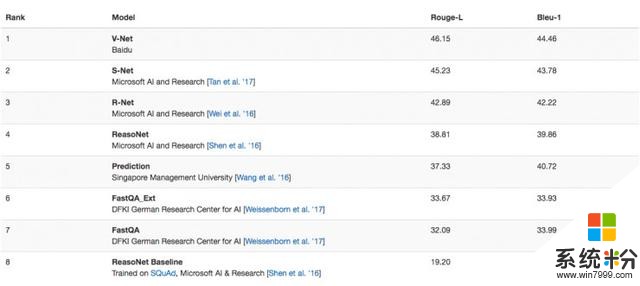
AI 科技評論消息,2 月 21 日,百度 NLP 團隊提交的 V-Net 模型以 46.15 的 Rouge-L 得分位列微軟的 MS MARCO 機器閱讀理解測試第一名。目前人類評測 Rouge-L 得分為 47;BLEU-1 得分為 46。
據了解,百度提交的 V-NET 模型使用了一種新的多候選文檔聯合建模表示方法,通過注意力機製使不同文檔產生的答案之間能夠產生交換信息,互相印證,從而更好的預測答案。
AI 科技評論了解到,除了百度位列第一外,憑借 Microsoft AI and Research 提交的 S-Net、R-Net、ReasoNet,二、三、四名均由微軟摘得。此外,新加坡管理大學與德國人工智能研究中心也緊隨其後。
MS MARCO 全稱為 Microsoft MAchine Reading Comprehension,即「微軟機器閱讀理解」,官網資料顯示其正式發布於 NIPS 2016。這是一套由 10 萬個問答和 20 萬篇不重複的文檔組成的數據集。
在機器閱讀理解領域,想必大家更為熟悉的是斯坦福大學發起的 SQuAD(Stanford Question Answering Dataset), AI 科技評論此前也有過不少相關報道。SQuAD 是行業內公認的機器閱讀理解領域的頂級水平測試,它構建了一個包含十萬個問題的大規模機器閱讀理解數據集,選取超過 500 篇的維基百科文章。在閱讀數據集內的文章後,機器需要回答若幹與文章內容相關的問題,並通過與標準答案的比對,得到 EM(精確匹配)和 F1(模糊匹配)的結果。訊飛與哈工大聯合實驗室、微軟、阿裏巴巴、騰訊等國內外知名研究企業及機構都是 SQuAD 榜單上的常客。
與 SQuAD 的最大不同之處在於,MARCO 數據集中的問題全都基於來自微軟必應搜索(BING)引擎和微軟小娜人工智能助手(Cortana)的已匿名處理的真實查詢。此外,相關回答是由真人參考真實網頁編寫的,並對其準確性進行了驗證。可以說,數據集的建立完全是根據用戶在 BING 中輸入的真實問題模擬搜索引擎中的真實應用場景,其研發團隊也曾表示,「MS MARCO 是目前同類型中最有用的數據集,因為它建立在經過匿名處理的真實世界數據基礎之上。」
目前搜索引擎隻能針對用戶的提問回答一些簡單問題,可以回答複雜問題的係統仍然處於起步階段,而普通人日常想獲取一些瑣碎複雜問題的答案,則需要在搜索引擎提供的結果中再次進行篩選、分析和整理。這些並無明確答案或存在多個可能答案的查詢,是微軟發布這一數據集希望攻克的閱讀理解高堡。
在每一個問題中,MARCO 提供多篇來自搜索結果的網頁文檔,係統需要根據這些文檔來回答給定的問題。就像人類在搜索引擎給定的結果中自行篩選信息一樣,這些文檔中是否有對應的答案、在哪一篇文章中,都需要係統自行判斷,甚至還需要結合多篇文章做出提煉與總結,而這也對機器的閱讀理解能力提出了更高的要求。
「此次在 MARCO 的測試中取得第一,隻是百度機器閱讀理解技術經曆的一次小考,」百度自然語言處理首席科學家兼百度技術委員會主席吳華表示,「我們希望能夠與領域內的其他同行者一起,推進機器閱讀理解技術和應用的研究,使 AI 能夠理解人類的語言、用自然語言與人類交流,讓 AI 更『懂』人類。」
相關資訊
最新熱門應用

可可交易平台app2024安卓手機
其它軟件22.9MB
下載
聚幣交易所官網
其它軟件50.16MB
下載
歐幣交易所app官方版蘋果版
其它軟件273.24MB
下載
幣包交易所app
其它軟件223.89MB
下載
zt蘋果交易所app官網
其它軟件81.19MB
下載
中幣網交易所app官網最新版本
其它軟件288.1 MB
下載
熱幣全球交易所官網
其它軟件287.27 MB
下載
幣贏交易所app蘋果版
其它軟件32.88MB
下載
中幣交易所app蘋果版
其它軟件288.1 MB
下載
ada幣交易所安卓版
其它軟件223.89MB
下載