
按:眾所周知,大規模帶標簽的數據對於深度學習尤為重要。在以圖像識別、機器翻譯等為代表的任務中,深度神經網絡通過大量帶標簽的數據進行訓練。但這樣的前提存在兩個主要的局限性。首先是人工標記數據的成本很高;其次是大規模標記數據獲取的難度較大。
為了解決這一問題,在 NIPS 2016 上,微軟亞洲研究院提出了“一種新的機器學習範式”——對偶學習,利用任務互為對偶的特點從無標注的數據中進行學習。它的訓練原理是怎樣,具體有哪些應用前景,近期又有著怎樣的進展?本期硬創公開課,榮幸地邀請到微軟亞洲研究院主管研究員秦濤博士,為我們講述對偶學習的新進展。做了不改動原意的整理與編輯,並邀請了秦濤博士核對確認,在此表示感謝。
嘉賓介紹
秦濤博士,微軟亞洲研究院主管研究員,在國際會議和期刊上發表學術論文100餘篇,曾/現任機器學習及人工智能方向多個國際大會領域主席或程序委員會成員,曾任多個國際學術研討會聯合主席。秦濤博士是中國科學技術大學兼職博士生導師,IEEE、ACM會員。他的團隊的研究重點是深度學習和強化學習的算法設計、理論分析及在實際問題中的應用。

大家晚上好,很高興能有這樣一個機會和大家分享微軟最近的一些研究成果。首先非常感謝提供硬創公開課的平台,同時也感謝各位朋友這麼晚還來參加這個線上活動。我今天報告的題目是對偶學習,主要想闡述的是人工智能的對稱之美。

先做一個簡單的自我介紹,我叫秦濤,是微軟亞洲研究院機器學習組的主管研究員。首先我將介紹下我們組所做的事情。
DRL團隊介紹我們組主攻方向是機器學習,有好幾個小團隊,涵蓋了多個機器學習的方向。我們有一個團隊側重於分布式機器學習平台、架構及算法實現,我們做了很多開源的項目,包括微軟認知工具包(原名: CNTK) 及分布式計算平台 DMTK 等,這些項目都可以在 GitHub 上找到。
我們除了做平台外,另一個研究方向是機器學習算法,包括兩個團隊:
深度學習與強化學習算法團隊;
符號學習團隊,即希望把一些邏輯、推理包括知識圖譜的內容與深度學習、統計學習結合起來。
我們還有一個團隊側重於機器學習理論。我們始終認為,機器學習作為一個研究方向,不僅是算法和應用,也需要對學習的理論進行理解與認識。
具體到我帶的深度學習與強化學習團隊,主要課題如同 PPT 上所示的,有四個大方向。

對偶學習是非常重要的一個方向,也是我待會會重點介紹的內容。
第二個很重要的方向是輕量級快速算法。目前深度學習或強化學習的訓練需要非常多的數據,非常長的訓練時間及大量計算資源如GPU。我們設計了一些快速算法,能達到同樣的精度或是相近的精度。
第三個方向是自主學習。我們意識到深度學習本身效果可以做得很好,但需要研究者或實踐者具備一定的經驗,知道如何調各種超參數,比如網絡結構如何設計,每層多少節點,是否要用 residual connection/skip connection,卷積或 recurrent connection,包括優化過程中需不需要做各種各樣的 SGD 算法,learning rate 怎麼做 decay。這些對結果都會有很大影響。
當我們麵臨一個新的數據集時,可能我們需要花很多時間和代價才能得到一個好的模型。因為需要做很多超參數的 tuning.
我們自主學習的理念有點像在模仿自動駕駛,也就是說,能否通過學習的方式,來解決超參數的tuning問題?
此外,我們團隊還會做深度學習與強化學習的相關應用,主要涵蓋三個方麵,包括:
語言理解(語言模型、文本分類、機器翻譯、文本生成等)、圖像理解(圖像分類、生成、描述等)
遊戲(麻將、橋牌等)
金融科技
接下來我將進入今天的分享主題:對偶學習。
對偶學習在介紹對偶學習之前,我想先介紹一下 AI 的發展。大家從很多媒體報道可以了解到,AI從 1956 年誕生以來至今已經 61 年,期間曆經風雨包括兩次高峰與兩次低穀,到目前為止我們處於第三次的上升期,並且這一次的高峰可能還未到達。

AI 在很多實際應用中取得了很好的成績,特別是在很多具體的任務上打敗了人類水平。

因此我們可以說,現在正是 AI 的黃金時代。不僅僅因為它得到了政府的提倡和扶植,在學術圈是一個比較火的研究方向,更重要的是它在工業界的實際問題中取得了非常令人矚目的成績,比如:
微軟亞洲研究院在 2015 年 ImageNet 上提出的深度殘差網絡,第一次使得圖像識別水平超過人類的平均水平,top 5 的錯誤率達到了 3.5%,而人類的水平差不多是 5.1%。
而在語音識別領域,在去年 10 月,微軟的語音識別係統在日常對話數據上,達到了 5.9% 的水平,首次取得與人類相當的識別精度。
遊戲領域上,DeepMind 的 AlphaGo 打敗了李世石,包括今年化名為「Master」也打敗了很多圍棋高手。今年 5 月下旬,AlphaGo 也會與中國頂級棋手進行對戰(屆時也將赴現場報道)。
雖然 AI (特別是以深度學習為代表)取得了非常大的成功,但它也麵臨著很多挑戰。對於研究者而言,不僅要看它取得了哪些成績,還要看它存在哪些問題,有哪些方向需要我們進行研究和推進。我們總結了當前 AI 或深度學習所麵臨的一些主要的挑戰,也是我們組目前研究的方向。
AI 目前所麵臨的挑戰 大數據,代價高昂
大數據,代價高昂目前的 AI 非常依賴大數據,特別是大量的人工標注的數據,但這些數據代價高,且在某些領域內數據很難獲得。
大模型,使用不便深度學習的模型一般體量很大,可能達到上千萬、上億、上十億參數的規模,一個模型大概是幾百兆。如果在雲端或是自己的 PC 上使用,問題不大,但如果想在移動設備(手機、物聯網設備)上使用,就麵臨各種問題。比如手機輸入法,如果用深度神經網絡,表現會更好,但很多時候,光一個語言模型就要達到上百兆,對用戶而言一個手機輸入法需要加載上百兆的模型是一件挺難接受的事,會導致響應速度、memory、耗電量等多個問題。
大計算,時不我待訓練一個深度模型很花時間。以 AlphaGo 為例,論文裏講到需要一個月左右的訓練時間。如果有很多參數、超參數需要調節,算法的迭代速度會變得很慢。時間很多時候是比錢更寶貴的,雖然我們可以同時用很多 GPU訓練,但還是需要好幾周的訓練時間才能得到一個模型。如此長的訓練時間不管是對於大公司的產品迭代,還是創業公司的快速發展,都是一個很大的製約因素。
蠻力解法,似是而非現在的深度學習更像是一種「蠻力求解」,主要靠的是數量取勝,也就是說,由非常多的數據、參數、計算量堆砌起來。人做計算的功耗相對而言非常低,而人的學習過程也不需要那麼大的數據量。舉個例子,比如說開車,現在駕校標準的上課時間也就幾十個小時,但特斯拉的無人駕駛汽車在路上跑了幾百萬小時,依然不能達到和人類一樣的水平。因此,深度學習是否能結合人的一些知識提升學習速度,也是一個值得研究的問題。
調參黑科技,難言之隱深度學習有點類似於「黑科技」,參數調節是非常微妙的,比如一個參數的初始化非常依賴經驗或感覺,這使得目前的深度學習不太像嚴格意義上的科學,更像是一種藝術。那麼我們能否尋找到一種自動化調參的方法,讓人工的幹預越少越好。這樣一來,我們也更方便將深度學習技術應用到新的場景中。
黑盒係統,不明就裏隨著模型深度和參數的增加,深度學習係統也會出現一些問題。此前某個互聯網公司推出了圖像分類的服務,但當時誤將黑人判斷為猩猩,引起了種族歧視的社會輿論,雖然這並不是企業的初衷,隻是技術上出現了問題。這件事情實際上是因為深度學習係統是一個黑盒係統,技術人員難以預計一個黑盒子係統在使用中會出什麼問題,以及解釋為什麼會出某個問題,也就很難在問題出現之前進行防範。因此,如果我們能讓深度學習係統從黑盒子變成白盒子,具備可解釋性及可修正性,自然讓人工智能和深度學習有更大的應用空間。
一階智能,非我所思現在的深度學習更像是一種「一階智能」,即考慮靜態任務(圖像分類、語音識別)。但人類在社會中所麵臨的問題,比如自動駕駛、金融等領域,涉及的情況更加複雜。在麵臨決策時,人們不僅會考慮自己如何做選擇,也常常會考慮其它人如何選擇。
比如,當前的路堵車了,我是否要選擇另一條路,但與此同時,可能別人也會選擇同樣的做法,那麼是否會導致另外一條路更堵?
比如炒股,如果你要比別人獲得更好的收益,那麼不僅要考慮自己如何買入賣出,還要考慮其它人看好什麼股票,他們買入賣出的時間節點是什麼。
這實際上是人類在做決策時的一個博弈過程。目前深度學習的成功,包括圖像識別、語音識別,還是處於一階智能。那麼可能我們需要考慮的是,如果同時有多個 AI 在一個係統中相互作用,會有什麼二階效應,該如何解決這個問題。
對偶學習的提出對偶學習的提出,主要是為了應對第一個挑戰,即大數據的問題。

舉些例子:
ImageNet 中標注過的訓練樣本量,大概是 120 萬張圖片;
語音識別領域需要成千上萬小時的語料數據;
機器翻譯裏麵需要上千萬雙語句對來訓練;
圍棋,如 AlphaGo,需要上千萬的職業棋手的比賽落子記錄。
而目前,大量的人工標注數據存在幾個問題:
首先是標注代價高;
其次是某些應用領域很難拿到數據,如癌症數據(需要與醫院合作),而因為涉及個人隱私,病人可能不願意共享數據。
我們可以估計一下機器翻譯標注數據的代價。目前市場上請專家翻譯,是按照每個詞進行計費, 5-10 美分/詞,那麼我們按市場平均價 0.075 美元,一個句子平均 30 個詞來算,如果我們需要翻譯 1000 萬句話,那麼花費會達到 2250 萬美金。
不過有人認為,其實這個成本也還能接受。但像微軟這樣的公司,通常提供的是幾十種甚至上百種語言的互譯。如果僅僅考慮 100 種語言的互譯,數據標注可能就已經需要超過 1000 億美元了。
因為標注數據的代價如此大,研究人員也提出了不同的解決方案來降低對標注數據的依賴。目前互聯網非常發達,沒有標注的數據量非常大,如何利用這些無標注的數據輔助機器學習呢?這些方法包括:
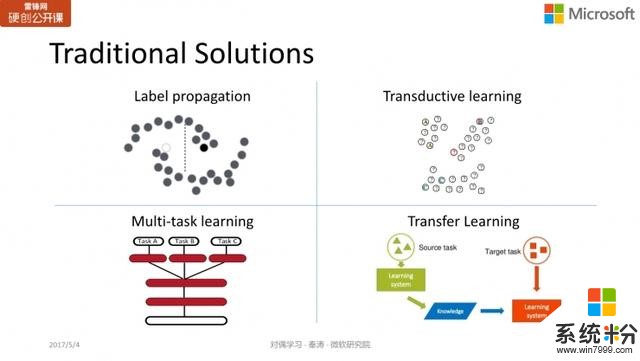
Label Propagation(標簽傳播):以圖像分類為例,如果隻有一萬張標注數據,但我想獲得 100 萬張標注數據,怎麼辦?我可以從網上抓取到很多圖像,如果一個未標注的圖像A和標注的圖像B很相似,那麼就認為圖像A具有和B相同的類別標簽。這樣就可以給很多未標注的數據加上標簽,增加訓練的數據量。
Transductive learning (轉導學習):一種半監督學習的方法。
Multi-task Learning (多任務學習):每個任務都有自己的標注數據,那麼多個任務在訓練時可以共享這些數據,從而每個任務訓練自己的模型時都能看到更多的數據。
Transfer Learning (遷移學習):這也是最近比較火的一種訓練方法。比如我有一個標注數據較少的目標任務(target task),但我的另一個 source task 的標注數據量比較充足,那麼我們可以通過模型的遷移或將數據通過變換借鑒過來,以輔助 target task 的學習。
對偶學習:一種新的視角我們采用一種新的視角來應對標注數據不足的問題,我們稱其為人工智能的對稱之美。其實大自然鍾愛對稱之美,例如生物構造(蝴蝶、人臉),人類也偏愛對稱之美,比如泰姬陵、中國的故宮、太極。

對稱結構不僅存在於自然界,在 AI 的任務中也廣泛存在。比如:
機器翻譯,有英翻中和中翻英的對稱;
語音處理,需要語音轉文字(語音識別),也有文本轉語音(語音合成)的任務;
圖像理解,圖像描述(image captioning)與圖像生成 (image generation)也是一個對稱的過程。
對話任務:問題回答(Question answering)與問題生成(Question generation)
搜索引擎:文本匹配查詢(Query-document matching)與廣告關鍵詞推薦服務(Query/keyword suggestion)

對偶學習的基本思想,實際上是一個新的學習範式,利用 AI 任務的對稱屬性(primal-dual)使其獲得更有效的反饋/正則化,從而引導、加強學習過程(特別是在數據量少的情況下)。
 如何從零或非常少的訓練數據中進行對偶學習?
如何從零或非常少的訓練數據中進行對偶學習?
這是我們發表在 NIPS 2016 的一個工作,主要是以機器翻譯為目標。
以機器翻譯為例,我們手頭有兩個智能體,一個隻懂英文不懂中文,另一個反之。我們希望同時訓練英翻中和中翻英的模型。
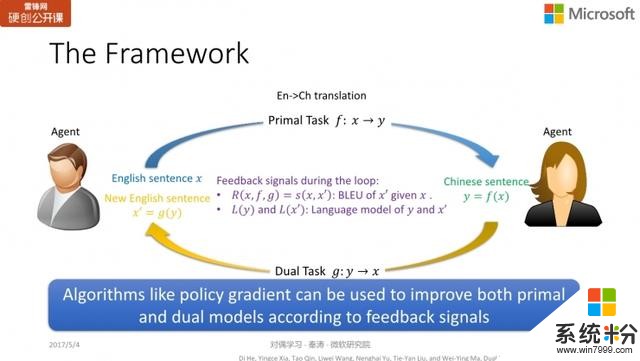
首先,拿到一個無標注的英文句子,我們並不知道
的正確中文翻譯。我們通過 primal model
;翻譯成一個中文句子
。
因為我們沒有進行標注,因此無從判斷句子
的正誤。但懂中文的智能體可以判斷作為一個中文句子,
是否為一個通順的、語法正確的句子。因此,懂中文的智能體可以給出一個 partial feedback,反饋句子
的質量如何。
隨後,我們通過對偶模型
,將中文句子
再翻譯為英文句子
。懂英文的智能體收到這個句子後,它可以比較
與
的相似度。如果
和
的表現很好,那麼
與
應該非常相近。如果反之,可能模型就需要改進。
這個過程實際上非常像強化學習的過程。在訓練過程中,沒有人告訴機器某個狀態下正確的 action 是什麼,隻能通過「試錯-反饋」的過程來反複嚐試。
以圍棋為例子,可能需要走上百步才能知道輸贏,但通過最終的反饋,就能訓練提高這個模型的優劣。對於我們機器翻譯在
的狀態下,我們無從知道正確的 action
是什麼,因此隻能通過已有的 policy
來 take action 得到
,再用另一個 policy
得到
, 從而通過比較
和
獲得反饋。這實際上也是一個不斷試錯的過程,而且像強化學習一樣,是具有延遲的反饋,最開始采取第一個 action
時,隻能獲得部分反饋,隻有到流程結束,才能獲得更有效的完整反饋,比如說
和
的相似性。
Policy Gradient因此,像強化學習的一些算法,都可以直接用於訓練更新模型
和
。我們的工作中用了一個叫策略梯度 policy gradient 的方法。它實際上是強化學習的一類方法。

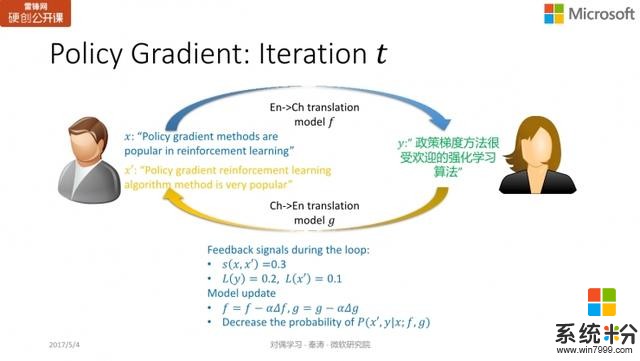
簡單說來,它的基本思想是,當采取某個行動(action)獲得了一個反饋/reward 後,如果反饋不錯,那麼我們會調整模型,使下一次采取同樣行動的概率變大,如果反饋不好,那麼我們就需要更新模型,降低我們采取同樣行動的概率。在算法上的實際,我們會對 primal model 和 dual model 求梯度,如果反饋好,我們會把梯度加到模型上,增加這個 action 的概率;反之,我們會將梯度減去,減少這個 action 出現的概率。
舉個簡單例子,
為「Policy gradient methods are popular in reinforcement learning」,而得到的
在語法上一看就有問題,從而我們發現
和
並不理想,因此希望更新
和
的參數,通過減去梯度,使不好 action 出現的概率變小。
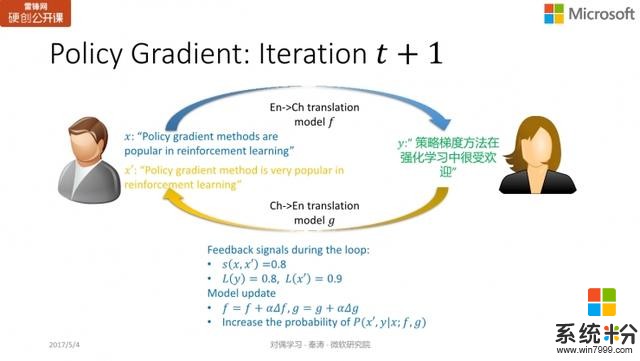
而在新的一輪迭代中,我們發現
和
都不錯,那麼通過加上梯度,使得讓好的 action 出現的概率變大。
雙語翻譯
在英法翻譯的實驗上,雙語標注的數據大概有 1200 萬個句對,目前機器翻譯最好的算法是基於深度神經網絡(Neural Machine Translation),如果用 100% 的雙語句對做訓練,NMT 能達到 30 分的 BLEU score(滿分為 100 分),如果隻用 10% 的標注數據訓練的話,NMT 的表現能達到 25 分;而在同樣 10% 的數據下,采用對偶學習的思想進行訓練,得分能達到 30 以上。也就是說,我們隻用 10% 的雙語數據就達到了 NMT 采用 100% 數據的準確度。

前麵我們估計過,1000 萬雙語標記的數據耗費大概為 2200 萬美元,而如果隻需要 10% 就能達到同樣的效果,我們隻需要花 200 萬美元。有點誇張地說,我們可以節省 2000 萬美元的標注費用,非常可觀。這個實驗結果表明,對偶學習利用無標注數據的效率還是非常高的。
語音處理、圖像處理及問題生成
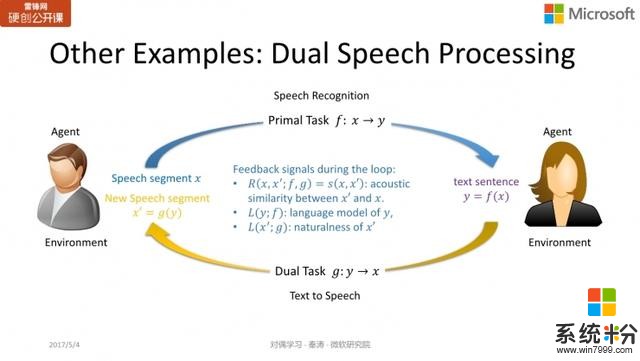
同樣的思想也可以應用於語音處理中,primal task 指的是語音識別,而 dual task 則是語音合成,
是一個文本(句子),那麼我們就能判斷
的語法是否正確,語言的模型得分如何,進而判斷
和
的相似度。
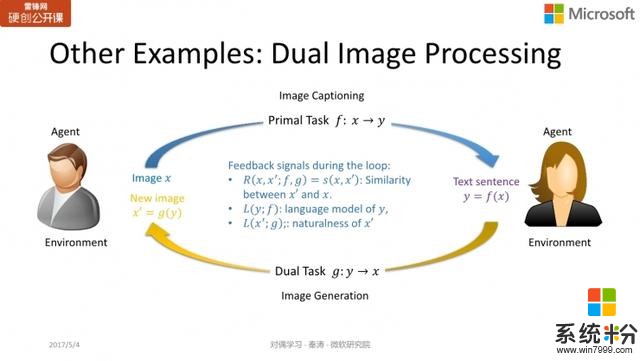
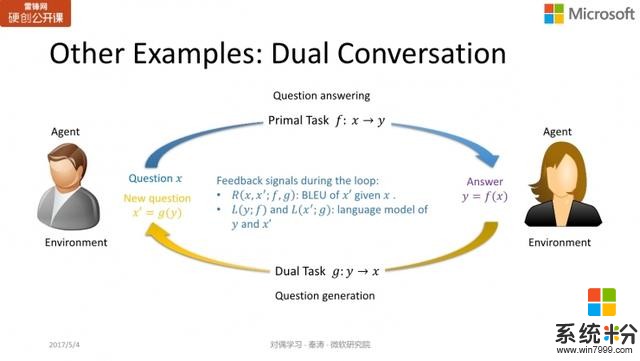
圖像和文本之間的相互轉換,問題回答與問題生成,也可以用同樣的方式實現。我們有同事已經在這個領域做過一些嚐試,也得到了很不錯的結果。
image-to-image translation
這個工作我們發表在 NIPS 2016 上,有很多研究人員把對偶學習的思想推廣應用到其它領域。比如這個叫「image-to-image translation」的任務,將兩種不同的圖像相互轉換,比如將素描轉換為一個照片(生成器 A),或是反過來,將照片轉換為素描(生成器 B)。通過生成器 A 和生成器 B 的兩次生成,我們希望原始素描與最後生成的素描越相似越好。或是反過來,通過生成器 B 和生成器 A 的先後兩次生成,我們希望原始照片與最後生成的照片的重構誤差越小越好。對偶學習和 GAN相結合,可以得到很好的結果。
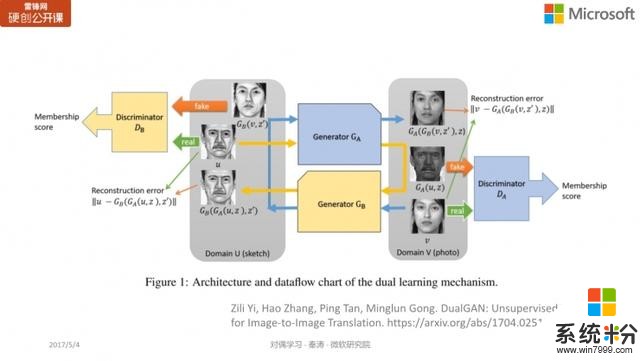
下圖所示的是 Architecture label 的 photo translation 訓練結果,第一列指的是原始 input 的 sketch(素描),第二列就是真實圖片的樣子,第三列就是 DualGAN 得到的結果,而第四列則是隻用 GAN 訓練得到的結果,第五列則是 cGAN,是訓練標注數據所得到的結果。

第二行中,我們可以看到,中間 DualGAN 的結果比 GAN 及 cGAN 的結果都要好,比如第二行 GAN 的上半部分細節丟失得比較嚴重;而第三行中 DualGAN 生成的門相對比較清楚,而 GAN 和 cGAN 生成的門相對比較模糊。從實驗結果的比對中我們可以看到,DualGAN 的效果相對要好不少。
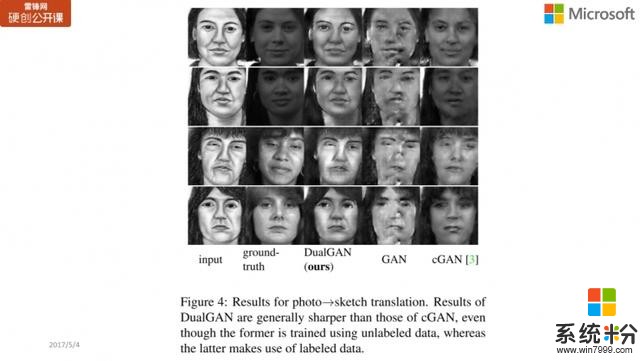
此外還有一個是從照片到素描(photo to sketch)的比對結果,同樣地,第一列指的是原始 input 的 sketch(素描),第二列是真實圖像,後麵三列分別是 DualGAN、GAN 和 cGAN 的訓練結果。DualGAN 在細節上更加清楚,我們可以看到 GAN 甚至某些地方都變形了,而 cGAN 也有不少細節(特別是眼睛)不夠清楚。
Face Attribute Manipulation
此外,我們還注意到另一個工作,它也是借鑒了對偶學習的思想,叫「Face Attribute Manipulation」,即圖像處理方麵的一些工作。比如說,有個人戴著墨鏡,那麼我們會希望「腦補」出對方摘下墨鏡的樣子。或是反過來,在淘寶上看到一個墨鏡,想知道自己戴上墨鏡會是什麼樣子。把墨鏡從人臉上去掉或戴上,實際上也是一個互為對偶的任務。

第一行是原始圖片的樣子,第二行則是結合 dual supervised learning 的方法來處理的結果;第三行則是不用對偶思想進行處理的結果。我們可以看出,第二行的結果比第三行的要好不少。從第一列及第五列可以看出,沒有用對偶學習的話,不僅生成的圖片比較模糊,臉也變形了。
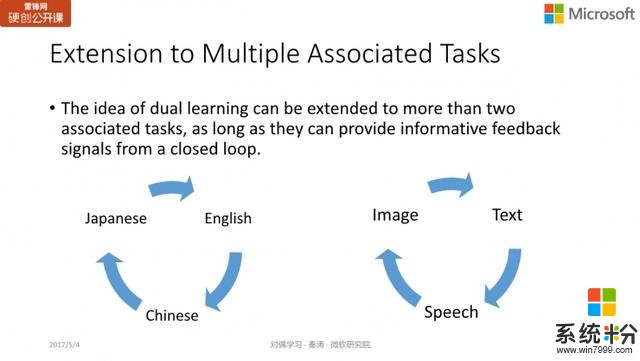
從無標注數據進行對偶學習的基本思想是要能獲得反饋、形成閉環(Closed loop 的反饋)。這種思想不僅僅是局限在互為對偶的兩個任務,可以擴展到更多的任務上,比如翻譯,我們可以在英文、中文、日文間進行轉換,形成閉環,從無標注的數據進行學習;又比如語音、圖像和文本三者的轉換也可以形成閉環,進行對偶學習。
目前為止,我們介紹了如何利用結構對稱之美從無標注的數據進行對偶學習。需要指出的是,對稱之美的價值不局限於此。我們來看看下麵這個概率公式,我們可以想象其中
是中文,
是英文,或
是圖片,
是句子,聯合概率
可用不同的分解方式來實現,比如用 primal 的分解方式,即
,同樣地,對偶分解方式可以寫成
。

利用這樣一個互為對稱的 AI 任務的概率關係,我們可以:
把它做為結構化的正則項,以加強監督學習。
或者提高我們的推理預測(improve inference)能力。
對偶學習如何增強監督學習?下麵我們首先來看看對稱之美如何加強監督學習。

機器翻譯
我們還是以翻譯為例,如果是有標注的數據,那麼監督學習的訓練過程相對簡單。我們知道
是
正確的翻譯,因此,我們就希望更新模型
,使
出現的概率越大越好,也就是最大似然準則。
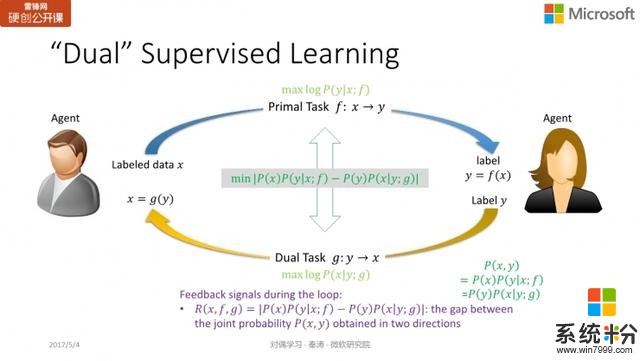
同樣地,對偶訓練的過程也是迭代更新對偶模型
使
,使條件概率
最大化。在傳統的監督學習中,兩個任務的訓練過程其實是分開的。我們知道,聯合概率
不論是用原模型
計算還是用對偶模型
計算,得到的值應該是一樣的。但是如果是分開訓練
和
的話,不一定能保證聯合概率相同。
為了解決這一問題,我們加入了「正則化」項,也就是
,將兩個概率值的 gap 最小化。從而,我們實現了通過結構的對稱性加強監督學習的過程,將兩個互為對稱的兩個任務一起進行學習,我們把這個考慮的結構對稱性的監督學習叫做對偶監督學習。對偶監督學習實際上要優化三個損失函數:最大化對數似然
,最大化對數似然
,以及
。第三項就是正則化像,即要求聯合概率越接近越好。這與 SVM 的正則化像的區別在於,後者與模型有關,和數據無關,但對偶監督學習中討論的正則化像還與數據相關。
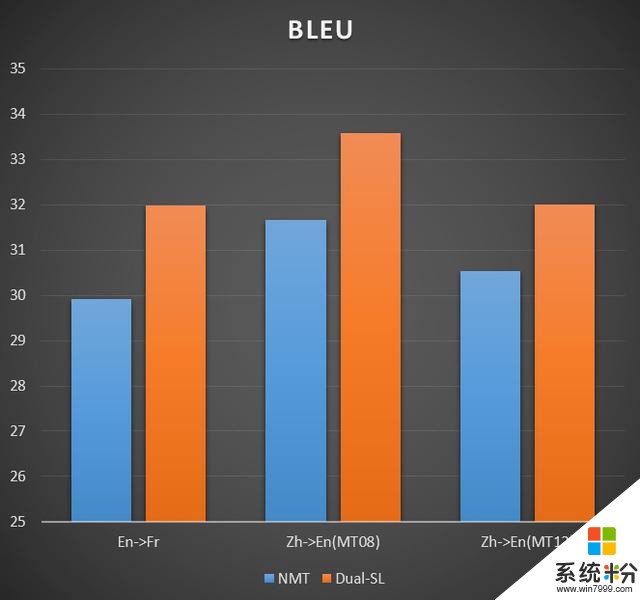
基於對偶監督學習的方法,我們做了機器翻譯的任務,包括英法、英中等翻譯,我們的方法(Dual-SL)相比標準的神經機器翻譯(NMT)效果還是要好不少,用BLEU來評價得分提高了 1-2 分。
圖像分類與生成
我們還將同樣的思想應用到圖像分類與圖像生成上。這兩個過程同樣互為對稱,但與機器翻譯的主要不同點在於,這個過程存在著信息損失。比如將一張圖分成一個類別,但一個類別如「貓」是一個很抽象的概念,可能對應很多不同貓的圖片,也就是說從
至
有信息損失。有人擔心是否因為信息損失的問題,對偶學習就不管用了,實際上不然。
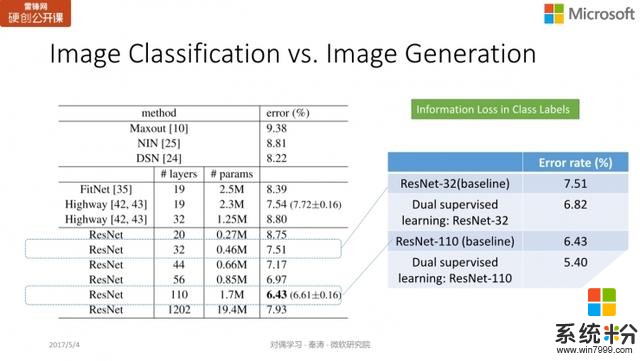
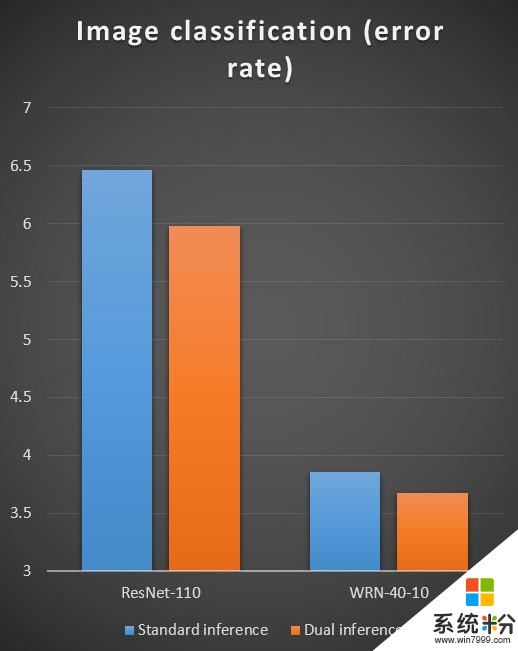
我們在 CIFAR 上采用了 32 層的深度殘差網絡 ResNet 和 110 層的深度殘差網絡進行測試。單獨訓練圖像分類時,32層的錯誤率是 7.51;110 層的則是 6.43;而如果結合了對偶監督學習,錯誤率可以分別減少到 6.82 及 5.40。這個提高實際上非常顯著,從 32 層到 110 層的效果提升也就是 1 個點左右,我們在 110 層的基礎上加上對偶學習後,我們可以進一步將錯誤率降低一個點。目前這項工作已經被 ICML 2017 接受。
對偶學習如何增強推斷?
就像我們前麵講的,不論是有標注的數據,還是無標注的數據,都是通過一種結構的對偶屬性提高我們訓練的過程,改進我們的模型,使我們的訓練做得更好。除此之外,其實利用結構的對稱之美還能提升我們推斷及預測的過程。
同樣以機器翻譯為例,如果我有了一個模型
(英翻中的模型)和模型
(中翻英的模型)。如果有一個英文的句子
,我們通過解碼把能最大化
的中文句子
作為
的翻譯;同理,給定一個中文的句子
,我們把能最大化條件概率
的英文句子
作為
的翻譯。這就是機器學習中標準預測推斷的做法。
前麵我們講到,聯合概率
有兩種計算方式,那麼
條件概率模型可以用正向模型
來計算,也可以通過反向模型
來計算,即
。
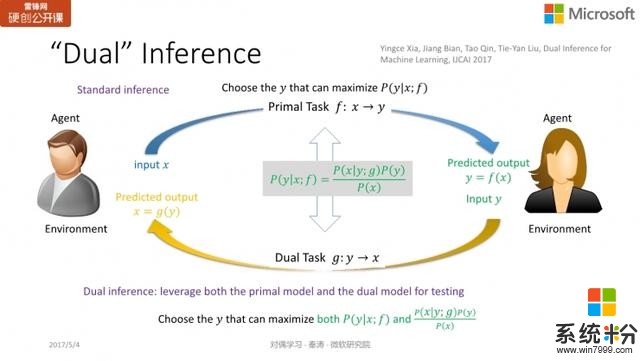
因此我們提出了一個新的概念,叫對偶推斷或對偶預測「dual inference」,在預測/推斷過程中同時采用
和
兩個模型。原本機器學習標準的預測過程是:我要從
預測出
,直接用
就可以了,但現在不同,我預測
時,我希望生成
能使兩項最大化:
和
。
需要指出的是,對偶推斷/預測不影響 和 的訓練過程,這兩個模型還可以按照原來的訓練過程進行,我們隻是改進了預測的過程。
我們在機器翻譯、文本情感分類、圖像分類上做了實驗,結果如下麵三張圖所示,相對於傳統的機器學習中的推斷/預測方式,對偶推斷對這些任務的準確度都有明顯的提升(錯誤率明顯降低)。
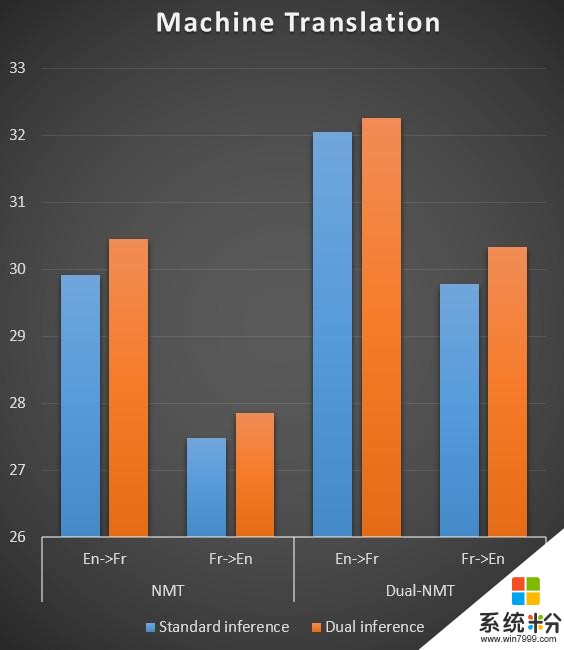
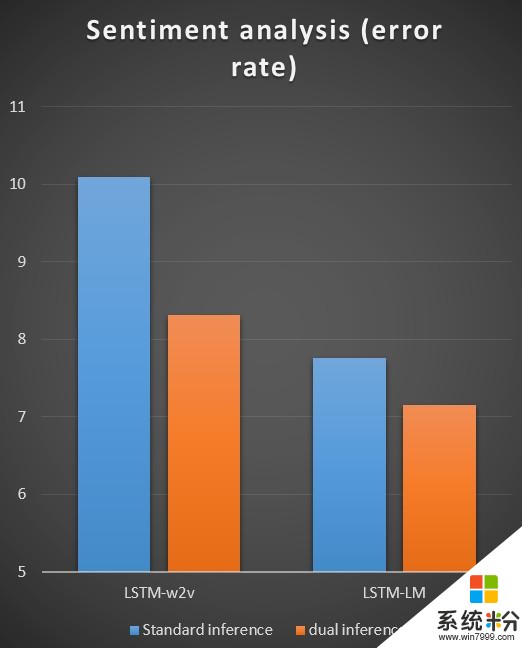
對偶推斷/預測這個工作也剛剛發表在國際人工智能大會上(IJCAI 2017)上,感興趣的讀者可以閱讀我們的論文。
相關工作
對偶學習的思想與很多工作都有關係。
Auto Encoder對深度學習比較了解的同學可能知道一個概念叫「auto encoder」(自編碼器),主要是為了學習數據的隱藏表達(hidden representation)。比如輸入一張圖像,我們希望將它映射到一個特征空間,在無監督學習中,通過特征表達的解碼過程將圖像反向生成。
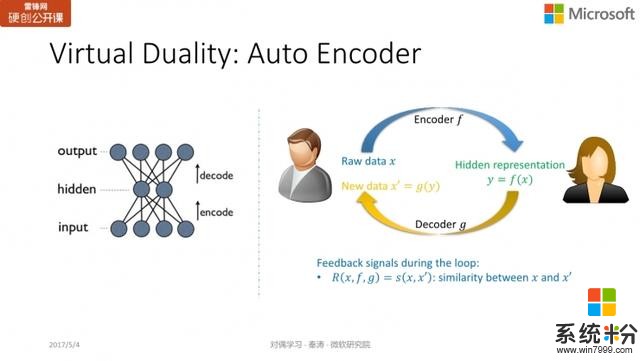
如果用對偶學習來表示這一過程,encoder 相當於原模型;而 decoder 就相當於對偶模型;目的是希望生成的新數據
與原始數據
越接近越好。
從這個角度來看,auto encoder 的思想與無監督對偶學習的概念很類似。
GANs另一個很火的網絡是 GANs,基本思想是輸入一個噪聲向量,我們希望生成器所生成的圖片與真實圖像越接近越好,使判別器無法區分。這種關係就像造假者與警察的關係:造假者希望能製造出盡可能以假亂真的東西,而警察希望盡可能將贗品和正品區分開來。
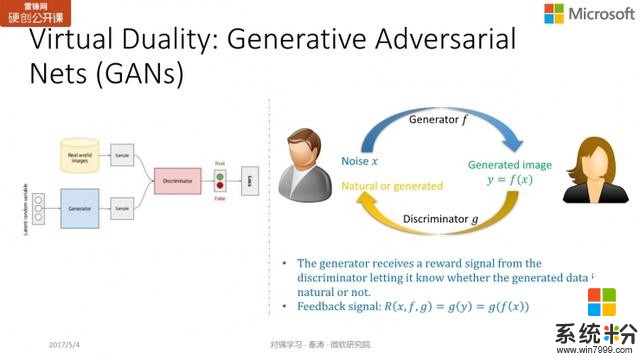
GANs 目前也是深度學習非常火的研究方向。如果用對偶學習的圖例來看,生成器就像是原模型,把隨機噪聲向量
映射到一個圖片
;而判別器就相當於對偶模型,通過直接給
打分的方式,給予它的真實程度反饋。
對偶學習:一種新的學習範式
對偶學習可以應用於很多方麵,如無監督學習與半監督學習,但它的思想與傳統思路有些不同。
與無監督/半監督學習對比:
首先在無監督學習裏,無標注數據並沒有反饋;半監督學習裏會生成一些偽標簽,但質量不能控製。這與對偶學習非常不同,我們會對無標注數據生成一個偽標簽,進而通過對偶模型對這些偽標簽給出質量反饋,因此我們能更有效地利用無標注數據,使得結果比以往的半監督/無監督學習要好。
與 co-training 對比:
其次,有人會認為這種方法與 co-training 很相似,但實際上 co-training 隻是半監督學習的一種特殊方法,做了一些很強的假設,如數據的特征集由兩個不相交的子集且每個子集的特征也足夠強,且co-training隻是針對一個任務進行學習。而對偶學習至少需要兩個互為對稱的任務,且對數據的特征沒有假設。
與多任務學習對比:
對偶學習與多任務學習也有些不同。如多任務學習在郵件識別
中,垃圾郵件識別(
到
)與緊急郵件篩選(
到
),共享底層的表達
,但上層的
與
是不同的。而對偶學習並不共享底層表達。
與遷移學習對比:
此外,對偶學習與遷移學習也有不一樣的地方。遷移學習有一個主要任務,采用其它的任務輔助它。對偶學習的兩個任務是共同提高的,不分主次。
因此,我們認為對偶學習是一種新的學習範式。
總結

對偶學習非常通用
能夠覆蓋目前 AI 的許多應用,包括文本理解、圖像理解,語音識別等。
也能涵蓋於 auto-encoder,GANs 等工作。
對偶學習可以應用於不同學習環境
監督學習、半監督學習、無監督學習都不在話下。
不僅能提升訓練效果,也能提升推斷過程。
對偶學習在技術上的貢獻
對偶學習利用了結構的對稱性/相關性提升學習,利用人類的先驗知識提升深度學習的係統;
對偶學習另一個很有意義的地方在於提供了一種從無標注數據學習的行之有效的方法。有很多人認為深度學習五到十年的主要突破方向在於如何從無標注數據進行學習,而對偶學習通過一個閉環的反饋係統,使我們能從無標注數據中進行學習。
另外,強化學習在遊戲領域中表現更好,因為遊戲可以通過規則製定明確的反饋機製,但像機器翻譯、無人駕駛這樣的物理世界的任務,實際上很難獲得反饋。通過對偶學習,我們可以獲得反饋信號,讓強化學習在實際問題中進行應用。
對偶學習的工作有非常多的研究者共同參與,包括微軟亞洲研究院的同事及實習生們。歡迎大家與我們交流討論合作,一同推進對偶學習的研究。

最後打一個廣告。人工智能深度學習目前是非常火的研究領域,也麵臨著非常多的挑戰,我們希望能有更多的朋友能加入這個方向的研究,共同推進人工智能的發展,創造未來。感興趣的朋友特別是即將畢業的同學或者已經從事這方麵工作的同學可以把簡曆發到這個郵箱 ml-recruit@microsoft.com。
謝謝大家。
 Q&A
Q&A1. 之前在知乎上看過秦老師關於對偶學習的回答,裏麵提到在解決大數據問題時,微軟會將對偶學習應用到更多的領域中去,比如圖像分類和生成。但圖像的分類和生成,與機器互譯的流程並不完全相同(即並不完全對稱),您是如何理解這個問題的?
的確,過程看起來是對稱的,實際上兩者的信息保留度上相差很多。我們可以近似的認為,機器翻譯從中文到英文是沒有信息損失的,反之亦然。但像圖像分類與圖像生成存在信息損失,因此我們近期的工作「對偶監督學習」就希望將它應用於圖像分類與圖像生成中,這個工作可以參考我們ICML2017的論文。目前我們也正在研究如何利用對偶學習的思想針對圖像分類和生成進行無標注學習。現在有一些初步的想法,但還沒有一個成熟的結果。我們當前的結果表明,如果沒有信息損失,那麼可以采用對偶無監督學習。而不論是否有信息損失,都可以采用對偶監督學習。
2. 對偶學習還有哪些可能的應用和方向?是否能談談研究院最近所做的一些進展?
我在前麵的 PPT 也列舉了一些應用,比如研究院的同事正在研究的方向,包括問題的生成與回答、語音合成與語音識別等。實際上,對偶學習的適用範圍很廣,研究和應用空間很大,感興趣的朋友們可以和我們郵件聯係。
3. 在人工智能的學習過程中,如何看待大數據及小數據各自所起的作用?
簡單講來,如果我們有大量標注數據的話,自然我們會想辦法充分利用,但如果沒有大數據的話,小樣本學習的重要一點在於如何利用 domain knowledge 或先驗知識進行學習。包括對偶學習在某種程度上,需要利用兩個任務的對稱性,實際上這也是人類的一種先驗知識,以加強學習。
4. 如何評價最近挺火的DiscoGAN/DualGAN跟對偶機器翻譯之間的異同?
DualGAN 和對偶學習的思想非常類似,但他們的成果算是一個加強版,學習過程的反饋包括兩部分,一個是重構誤差,另一部分是判別器判斷真假的反饋。
5. DualGAN連一小部分有監督數據都不需要,對偶機器翻譯有可能也做到嗎?
我們做了一些簡單嚐試,初步發現,如果完全不用標注數據,對偶機器翻譯收斂會變得很慢,在資源比較有限的情況下,很難在幾個月裏達到一個好的結果。
我們組現在也在研究一個課題,即完全沒有標注數據,是否能隻通過一本英漢詞典(先驗知識)結合對偶學習思想進行學習。
6. actor critic是否也算有duel learning思想?對偶學習收斂性如何優化?
actor critic 有點像對偶模型,actor 負責 take action,而 critic 負責給這個 action 的好壞進行反饋,這樣兩者可以一起優化。但是 actor critic 不是利用了結構對稱性,而是為了優化 actor 而構建一個 critic,因此我覺得 GANs 與它更相似。
優化也是我們現在對偶學習遇到的主要問題之一,也是深度學習算法普遍會遇到的一個問題。這是一個很複雜的過程,目前我們有一些經驗,但通用性不強,因此也處於一個摸索過程。如果朋友們有什麼想法,也歡迎一同討論。
今天的直播就到這裏結束。如果大家想看課程總結文章,可以關注的公眾號,裏麵有很多很好的內容,建議大家平時可以多關注。如果想看具體課程,可以回複「167」進入行業微信群討論,也歡迎大家和我們交流,謝謝大家。
相關資訊
最新熱門應用

智慧笑聯app官網最新版
生活實用41.45MB
下載
盯鏈app安卓最新版
生活實用50.17M
下載
學有優教app家長版
辦公學習38.83M
下載
九號出行app官網最新版
旅行交通28.8M
下載
貨拉拉司機版app最新版
生活實用145.22M
下載
全自動搶紅包神器2024最新版本安卓app
係統工具4.39M
下載
掃描王全能寶官網最新版
辦公學習238.17M
下載
海信愛家app最新版本
生活實用235.33M
下載
航旅縱橫手機版
旅行交通138.2M
下載
雙開助手多開分身安卓版
係統工具18.11M
下載