
按:微軟研究人員創建了一個人工智能的係統,這個係統能夠在 20 世紀 80 年代風靡全球的電子遊戲吃豆人小姐(Ms. Pac-Man)中獲得最高分,係統使用了分治策略來更大程度地影響 AI 代理,從而完美地通關遊戲。
今年年初,微軟收購了一家人工智能初創公司 Maluuba,Maluuba 公司團隊運用強化學習技術(機器學習的分支),在吃豆人小姐遊戲 Atari 2600 版本中表現完美。使用這種方法,該團隊在這個遊戲中得到的分數高達 999,990。
位於加拿大蒙特利爾的麥吉爾大學(McGill University),從事計算機科學研究的 Doina Precup 副教授表示,AI 研究人員的常常使用各種電子遊戲來測試他們研發的係統,但研究人員發現吃豆人小姐遊戲是最難攻克的。
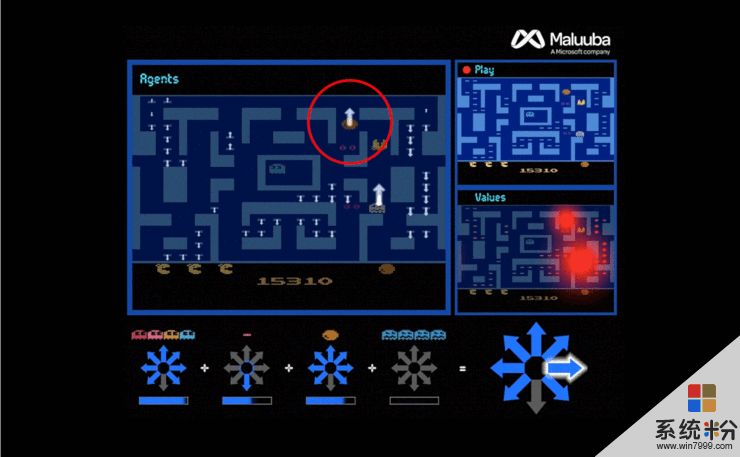
但是,Precup 表示,相比於研究人員所取得的成就而言,她對於研究人員獲得成果的過程更加感興趣。為了在吃豆人小姐遊戲中獲得更高的分數,Maluuba 公司團隊將操控吃豆人小姐遊戲的大問題分解成若幹個小問題,然後將小問題分發給AI代理解決。
Precup 說“這個分治策略的想法讓 Maluuba 公司的研究人員使用不同的係統來實現同一個目標,這是一件非常有趣的事情”,她還說到:“這個想法類似於一些大腦如何工作的理論,它可以更大程度地影響AI代理教學,從而利用有限的信息來完成更為複雜的任務。倘若能夠完美利用分治策略,那人工智能將向前跨越一大步,這真的令人感到尤為興奮。”
Maluuba 團隊將這種分治策略稱之為混合式獎賞架構(Hybrid Reward Architecture),這個方法使用了 150 多名人工智能代理,每個代理與其他代理相互獨立地精通吃豆人小姐遊戲。比如,一些代理成功找到一個豆子將獲得的獎勵,而另外一些代理由於幽靈的存在必須呆在原處。
然後,研究人員在吃豆人小姐遊戲中創建了一個頂級代理,就像一家公司的高級經理一樣,頂級代理能夠獲得所有代理的建議,綜合分析後由頂級代理來決定吃豆人小姐該如何移動。
頂級代理會根據選擇各個方向前進的代理數量的大小來決定移動方向,但同時也需要考慮到代理想要往某個方向移動的反應強度。例如,如果 100 個代理想向右邊移動,因為向右邊走是他們的最佳路徑,但有 3個人想要向左邊移動,因為右邊有一個致命的幽靈,那這 3 個代理向左邊移動的反應強度明顯強於其他代理,考慮到幽靈的存在,頂級代理應該決定向左移動。
Maluuba 公司的研究室經理 Harman Van Seijen,對於他們的最新研究成果發表了一篇文章,文章中寫到,當每位代理都果斷地做出選擇,頂級代理綜合利用每個代理的信息後做出最佳選擇,那麼在吃豆人小姐遊戲中就可以獲得最好的結果。Harman Van Seijen 說:“雖然每個代理隻關心一個特定的問題,但是他們之間有很好的相互作用”。

為什麼 AI 主要研究攻克吃豆人小姐遊戲
需要運用最先進的 AI 研究方法來擊敗類似於上世紀 80 年代 Atari 吃豆人小姐遊戲這樣的簡單遊戲,這看上去很匪夷所思。但是 Maluuba 公司的項目經理 Rahul Mehrotra 表示,使用算法來贏得這些簡單的電子遊戲其實非常困難,因為在玩遊戲的過程中可能會遇到的各種各樣的情況。
Mehrotra 表示:“許多從事人工智能的公司構建遊戲智能算法,因為公司希望人工智能能夠像人類一樣擁有打遊戲的技能。”
Steve Golson 是吃豆人小姐遊戲街機版的創始人之一,他說到,吃豆人小姐最初定位是街機遊戲,希望遊戲對人們有持續吸引力而走出宿舍,所以吃豆人小姐遊戲必須掌握人類不可完全征服的遊戲程序。

運營谘詢公司 Trilobyte Systems 的 Golson 說到,他們故意設計了吃豆人小姐遊戲比普通吃豆人遊戲更加不可預測,所以玩家們很難打通關。複雜的遊戲使得研究人員試圖使用 AI 代理來對隨機環境做出理想的反應。Golson 還說到:“使用 AI 代理來通關吃豆人小姐遊戲是可行的,但由於遊戲的隨機性,所需要設計的 AI 程序將尤為複雜。”
強化學習
對於在不斷發展的強化學習領域工作的研究人員來說,這種不可預測性極有價值。在 AI 研究中,強化學習是監督學習的副本,是一種更常用的人工智能方法,它能夠讓係統在做任務時變得更好。
通過強化學習,代理對其每個動作都采取積極或消極的反應,通過不斷地試驗和犯錯誤來最大限度地獲得積極反應或獎賞。
具有監督學習的 AI 係統,通過給出良好和不恰當的示例,來學習如何在對話中做出適當的回應。而強化學習係統則是通過係統在對話中做出正確的回應,而後獲得更高級別反饋的方式來學習對話。
AI 專家認為,強化學習可以用於創建 AI 代理,這樣的代理可以做出更多的決定,能夠完成更複雜工作,為人們提供更高水平的服務。Mehrotra 表示,他們開發的能夠通關吃豆人小姐遊戲的係統,就可以為人們提供更好的服務。它可以在特定時間或任意時間幫助公司的銷售部門預測商品的潛在客戶。該係統可以使用多個代理,每個代理代表一個客戶,可以預測很多重要因素,例如:哪些客戶會續簽合同,哪些合同對於公司是有價值的。
有了 AI 係統預測的幫助,銷售主管可以把更多的時間放在潛在客戶身上,如此會提高出售機會,因為銷售人員的目光已經瞄準了最容易下訂單的客戶。
Van Seijen 表示,他希望這種分治策略可以被用在 AI 的其他研究領域,如自然語言處理領域。他還說到:“分治策略使人們在解決真正複雜的問題的方式上取得進步。”
via Microsoft
相關資訊
最新熱門應用

光速寫作軟件安卓版
辦公學習59.73M
下載
中藥材網官網安卓最新版
醫療健康2.4M
下載
駕考寶典極速版安卓app
辦公學習189.48M
下載
貨拉拉搬家小哥app安卓版
生活實用146.38M
下載
烘焙幫app安卓最新版
生活實用22.0M
下載
喬安智聯攝像頭app安卓版
生活實用131.5M
下載
駕考寶典科目四app安卓版
辦公學習191.55M
下載
九號出行
旅行交通133.3M
下載
全國潮汐表官方app最新
生活實用31.83M
下載
閃送一對一急送app安卓版
生活實用50.61M
下載