
選自arXiv,作者:Tao Ge, Furu Wei, Ming Zhou,機器之心編譯。

因為 seq2seq 模型在語法糾錯上存在缺陷,微軟亞洲研究院的自然語言計算團隊近日提出了流暢度提升學習和推斷機製,用於改善 seq2seq 模型的語法糾錯性能。實驗表明,改進後的模型取得了當前最佳性能,並首次在兩個基準上都超越了人類水平。
用於語法糾錯(GEC)的序列到序列(seq2seq)模型(Cho et al., 2014; Sutskever et al., 2014)近年來吸引了越來越多的注意力(Yuan & Briscoe, 2016; Xie et al., 2016; Ji et al., 2017; Schmaltz et al., 2017; Sakaguchi et al., 2017; Chollampatt & Ng, 2018)。但是,大部分用於 GEC 的 seq2seq 模型存在兩個缺陷。第一,seq2seq 模型的訓練過程中使用的糾錯句對有限,如圖 1(a)所示。受訓練數據的限製,具備數百萬參數的模型也可能無法實現良好的泛化。因此,如果一個句子和訓練實例有些微的不同,則此類模型通常無法完美地修改句子,如圖 1(b)所示。第二,seq2seq 模型通常無法通過單輪 seq2seq 推斷完美地修改有很多語法錯誤的句子,如圖 1(b)和圖 1(c)所示,因為句子中的一些錯誤可能使語境變得奇怪,會誤導模型修改其他錯誤。

圖 1:(a)糾錯句對;(b)如果句子與訓練數據有些微的不同,則模型無法完美地修改句子;(c)單輪 seq2seq 推斷無法完美地修改句子,但多輪推斷可以。
為了解決上述限製,微軟研究者提出一種新型流暢度提升學習和推斷機製,參見圖 2。
對於流暢度提升學習,seq2seq 不僅使用原始糾錯句對來訓練,還生成流暢度較差的句子(如來自 n-best 輸出的句子),將它們與訓練數據中的正確句子配對,從而構建新的糾錯句對,前提是該句子的流暢度低於正確句子,如圖 2(a)所示。研究者將生成的糾錯句對稱為流暢度提升句對(fluency boost sentence pair),因為目標端句子的流暢度總是會比源句子的流暢度高。訓練過程中生成的流暢度提升句對將在後續的訓練 epoch 中作為額外的訓練實例,使得糾錯模型可以在訓練過程中看到具有更多語法錯誤的句子,並據此提升泛化能力。
對於模型推斷,流暢度提升推斷機製允許模型以多輪推斷的方式漸進地修改句子,隻要每一次提議的編輯能夠提升語句的流暢度,如圖 2(b) 所示。對於有多個語法錯誤的語句,一些錯誤將優先得到修正。而經修正的部分能讓上下文更加清晰,這對模型接下來修改其它錯誤非常有幫助。此外,由於這種任務的特殊性,我們可以重複編輯輸出的預測。微軟進一步提出了一種使用兩個 seq2seq 模型的往返糾錯方法,其解碼順序是從左到右和從右到左的 seq2seq 模型。又因為從左到右和從右到左的解碼器使用不同的上下文信息解碼序列,所以它們對於特定的錯誤類型有獨特的優勢。往返糾錯可以充分利用它們的優勢並互補,這可以顯著提升召回率。
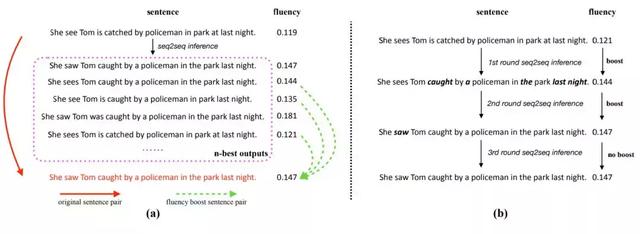
圖 2:流暢度提升學習和推斷機製:(a)給出一個訓練實例(即糾錯句對),流暢度提升學習機製在訓練過程中從 seq2seq 的 n-best 輸出中構建多個流暢度提升句對。流暢度提升句對將在後續的訓練 epoch 中用作訓練實例,幫助擴展訓練集,幫助模型學習;(b)流暢度提升推斷機製允許糾錯模型通過多輪 seq2seq 推斷漸進式地修改句子,隻要句子的流暢度一直能夠提升。
結合流暢度提升學習和推斷與卷積 seq2seq 模型,微軟亞洲研究院取得了當前最佳的結果,這使其成為首個在兩個基準上都達到人類水平的 GEC 係統。
論文:REACHING HUMAN-LEVEL PERFORMANCE IN AUTOMATIC GRAMMATICAL ERROR CORRECTION: AN EMPIRICAL STUDY

論文地址:https://arxiv.org/pdf/1807.01270.pdf
摘要:神經序列到序列(seq2seq)方法被證明在語法糾錯(GEC)中有很成功的表現。基於 seq2seq 框架,我們提出了一種新的流暢度提升學習和推斷機製。流暢度提升學習可以在訓練期間生成多個糾錯句對,允許糾錯模型學習利用更多的實例提升句子的流暢度,同時流暢度提升推斷允許模型通過多個推斷步驟漸進地修改句子。結合流暢度提升學習和推斷與卷積 seq2seq 模型,我們的方法取得了當前最佳的結果:分別在 CoNLL-2014 標注數據集上得到 75.02 的 F0.5 分數,在 JFLEG 測試集上得到 62.42 的 GLEU 分數,這使其成為首個在兩個基準數據集上都達到人類水平(CoNLL72.58,JFLEG62.37)的 GEC 係統。
2 背景:神經語法糾錯
典型的神經 GEC 方法使用帶有注意力的編碼器-解碼器框架將原始句子編輯成語法正確的句子,如圖 1(a)所示。給出一個原始句子
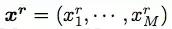
及其糾錯後的句子
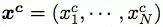
,其中
和
分別是句子 x^r 和 x^c 的第 M 和第 N 個單詞,則糾錯 seq2seq 模型通過最大似然估計(MLE)從糾錯句對中學習概率映射 P(x^c |x^r ),進而學習模型參數 Θ_crt 以最大化以下公式:
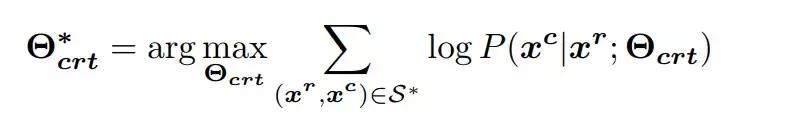
其中 S* 表示糾錯句對集。
對於模型推斷,通過束搜索輸出句子選擇
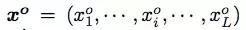
,這一過程需要最大化下列公式:
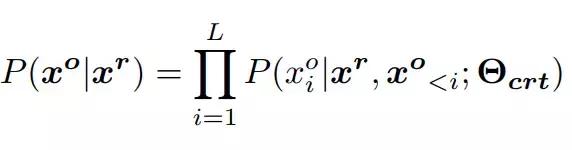
3 流暢度提升學習
用於 GEC 的傳統 seq2seq 模型僅通過原始糾錯句對學習模型參數。然而,這樣的糾錯句對的可獲得性仍然不足。因此,很多神經 GEC 模型的泛化性能不夠好。
幸運的是,神經 GEC 和神經機器翻譯(NMT)不同。神經 GEC 的目標是在不改變原始語義的前提下提升句子的流暢度;因此,任何滿足這個條件(流暢度提升條件)的句子對都可以作為訓練實例。
在這項研究中,研究者將 f(x) 定義為句子 x 的流暢度分數。
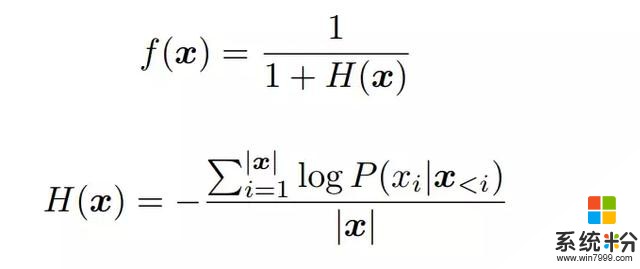
其中,P(x_i | x_<i)是給定上下文 x_<i 下 x_i 的概率,由語言模型計算得到,|x| 是句子 x 的長度。H(x) 是句子 x 的交叉熵,範圍為 [0, +∞)。因此 f(x) 的範圍為 (0, 1]。
流暢度提升學習的核心思想是生成流暢度提升的句對,其在訓練期間滿足流暢度提升條件,如圖 2(a)所示,因此這些句子對可以進一步幫助模型學習。
在這一部分中,研究者展示了三種流暢度提升策略:反向提升(back-boost)、自提升(self-boost)和雙向提升(dual-boost),它們以不同的方式生成流暢度提升句子對,如圖 3 所示。
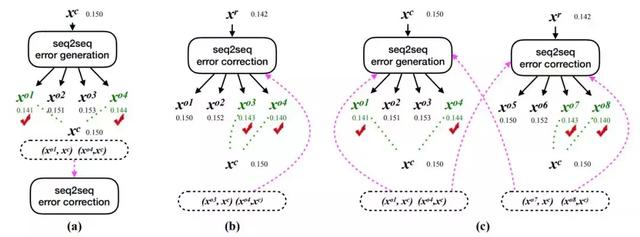
圖 3:三種流暢度提升學習策略:(a)反向提升,(b)自提升,(c)雙向提升。它們都能生成流暢度提升句對(虛線框中的句對),幫助訓練過程中的的模型學習。圖中的數字是對應句子的流暢度分數。
4 流暢度提升推斷
4.1 多輪糾錯
正如在第一節中討論的,一些具有多個語法錯誤的語句通常不能通過一般的 Seq2Seq 推斷(單輪推斷)得到完美的修正。幸運的是,神經 GEC 與 NMT 不同,它的源語言與目標語言相同。這一特征允許我們通過多輪模型推斷多次編輯語句,也就產生了流暢度提升推斷過程。如圖 2(b) 所示,流暢度提升推斷允許通過多輪 Seq2Seq 推斷漸進式地編輯語句,隻要每一次提議的編輯能夠提升語句的流暢度。具體來說,糾錯 Seq2Seq 模型首先將原語句 x^r 作為輸入,並輸出假設 x^o1。然後流暢度提升推斷將采用 x^o1 作為輸入以生成下一個輸出 x^o2,而不是將 x^o1 直接作為最終的預測。除非 x^ot 不再能提升 x^ot-1 的流暢度,否則這一過程就不會終止。
4.2 往返糾錯
基於多輪糾錯的思路,研究者進而提出了一個進階流暢度提升推斷方法:往返糾錯。該方法不使用 4.1 中介紹的 seq2seq 模型漸進性地修改句子,而是通過一個從右到左和一個從左到右的 seq2seq 模型依次修改句子,如圖 4 所示。

圖 4:往返糾錯:某些類型的錯誤(例如,冠詞錯誤)由從右到左的 seq2seq 模型會更容易糾錯,而某些錯誤(例如主謂一致)由從左到右的 seq2seq 模型更容易糾錯。往返糾錯使得二者互補,相對於單個模型能糾正更多的語法錯誤。
5 實驗
表 2 展示了 GEC 係統在 CoNLL 和 JFLEG 數據集上的結果。由於使用了更大規模的訓練數據,因此即使是基礎卷積 seq2seq 模型也超越了多數之前的 GEC 係統。流暢度提升學習進一步提升了基礎卷積 seq2seq 模型的性能。
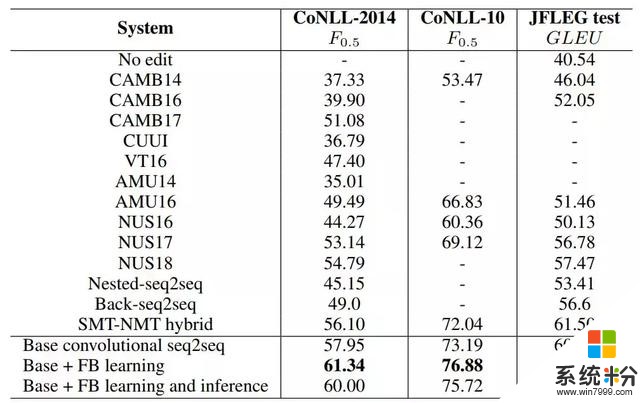
表 2:GEC 係統在 CoNLL 和 JFLEG 數據集上的結果對比。
如表 3 所示,流暢度提升學習提升了基礎卷積 seq2seq 模型所有層麵的表現(精度、召回率、F0.5 和 GLEU),表明流暢度提升學習確實有助於用於 GEC 的 seq2seq 模型的訓練。
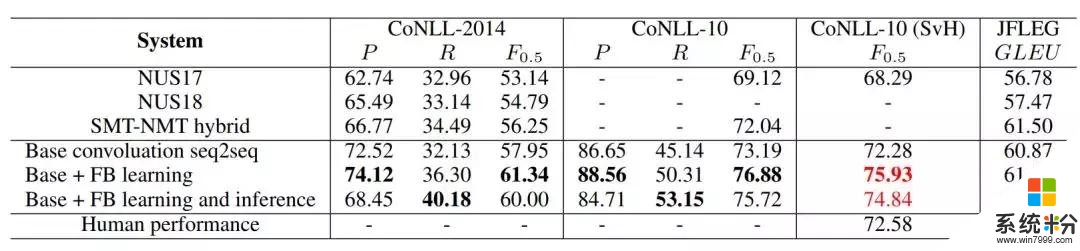
表 3:性能最佳的 GEC 係統在 CoNLL 和 JFLEG 數據集上的評估結果分析。紅色字體的結果超越了人類水平。
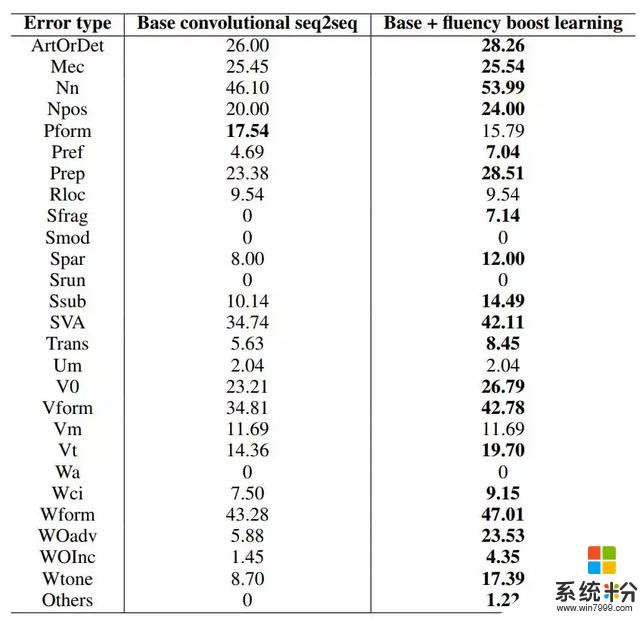
表 4:有/沒有流暢度提升學習的卷積 seq2seq 模型在 CoNLL-2014 數據集的每個錯誤類型上的召回率對比。
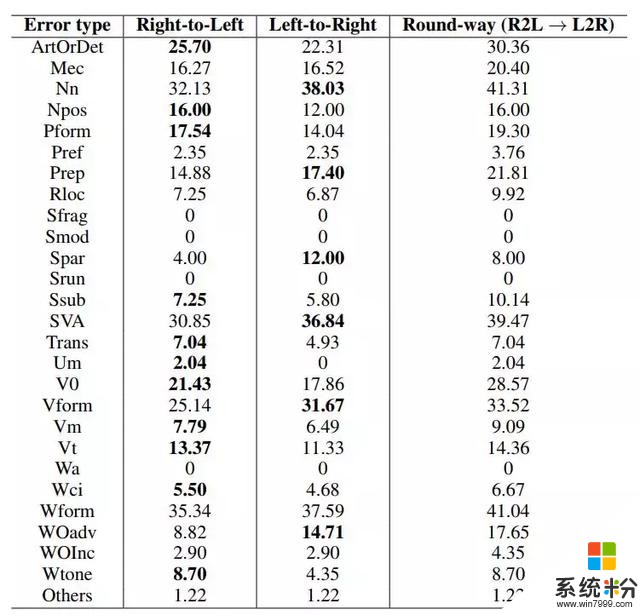
表 5:從左到右和從右到左的 seq2seq 模型對 CoNLL-2014 中每種錯誤類型的召回率
相關資訊
最新熱門應用

bicc數字交易所app
其它軟件32.92MB
下載
比特國際網交易平台
其它軟件298.7 MB
下載
熱幣交易所app官方最新版
其它軟件287.27 MB
下載
歐昜交易所
其它軟件397.1MB
下載
vvbtc交易所最新app
其它軟件31.69MB
下載
星幣交易所app蘋果版
其它軟件95.74MB
下載
zg交易所安卓版app
其它軟件41.99MB
下載
比特幣交易app安卓手機
其它軟件179MB
下載
福音交易所蘋果app
其它軟件287.27 MB
下載
鏈易交易所官網版
其它軟件72.70MB
下載