
KYLE WIGGERS 對此做了詳細的介紹,將其文章進行了不改變願意的編譯,具體如下。
在一份預先出版的論文中,微軟研究團隊詳細地介紹了他們的工作——為開放領域的對話進行無監督的上下文重寫。他們聲稱,在重寫質量和多輪響應生成方麵,他們的實驗結果已經達到了最新基準。
正如研究人員所解釋的那樣,對話上下文提出了句子建模中所沒有的挑戰,比如主題轉換、共同引用(像他、她、它、他們這種)、長期依賴。大多數係統解決這些問題的方法是在最後一段話中添加關鍵字,或者用 AI 模型學習數字表示,但這種方法往往會遇到障礙,比如無法選擇正確的關鍵詞、無法處理較長的上下文等。
這時候,就是微軟研究團隊的方法的用武之地了。它通過對語境信息的考量,重新製定了對話中的最後一句話;這麼做是為了生成一個獨立的話語,既不存在相互參照,也不依賴過去對話的其它話語。

注:【 圖片來源:Microsoft 所有者:Microsoft 】
舉個例子,如果將“我討厭喝咖啡。- - 為什麼?它挺好喝的啊。”轉化成“為什麼會討厭喝咖啡呢?它挺好喝的啊。”,這就借用了“它”和“為什麼”。其中,“它”指代的是對話中提到的咖啡,“為什麼”則是“為什麼討厭喝咖啡”的縮寫形式。
對此,研究人員設計了一個機器學習係統——上下文重寫網絡(按:context rewriting network, CRN),來實現端到端的流程自動化。這個係統是由一個序列到序列模型組成的,它能夠將固定長度的話語映射到固定長度的重寫句子上。並且,它還具有一個獨立的注意力機製,這個機製能夠通過最後話語中的不同單詞來幫助它從上下文中複製單詞。
那麼,這個係統是如何被設計出來的呢?
首先,微軟研究團隊使用偽數據對模型進行了訓練,這些偽數據是通過提取上下文的關鍵字,將這些關鍵字插入到原始對話中的最後話語中來生成的。然後,為了讓最後的響應影響重寫過程,他們利用了強化學習去推動係統朝著目標前進。
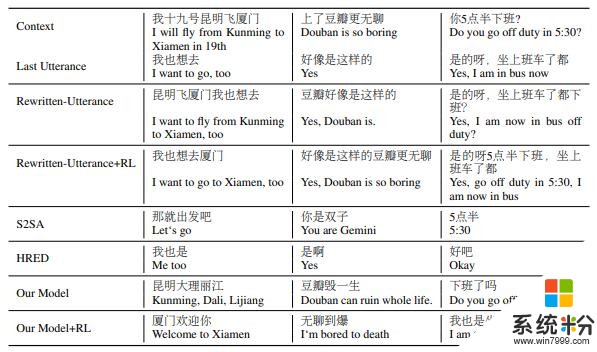
注:【 圖片來源:Microsoft 所有者:Microsoft 】
在一係列實驗中,該團隊評估了他們的方法在幾種重寫質量,多回合響應生成,多回合響應選擇以及基於端到端檢索的任務上的應用。他們注意到,由於他們的模型更傾向於從上下文中提取更多的單詞,因此該模型在強化學習後偶爾會變得不穩定,不過,這也顯著地提升了話語的多樣性。
微軟研究團隊認為,他們的工作朝著更易解釋和更易控製的上下文建模中邁進了一步。另外,該研究團隊還表示,他們的模型可以從嘈雜的語境中提取出重要的關鍵詞,然後將這些關鍵詞插入到最後的話語中,使其不僅變得易於控製和解釋,還有助於將信息直接傳遞到最後的話語中。
注:本文編譯自 KYLE WIGGERS 發表在 venturebeat 上的文章。
相關資訊
最新熱門應用

抹茶交易所官網app
其它軟件137MB
下載
抹茶交易所app
其它軟件137MB
下載
中安交易所官網
其它軟件58.84MB
下載
熱幣全球交易所app蘋果
其它軟件38.33MB
下載
歐聯交易所app
其它軟件34.95 MB
下載
bitstamp交易所
其它軟件223.89MB
下載
幣行交易所app安卓版
其它軟件11.97MB
下載
zbx交易平台
其它軟件32.73 MB
下載
鏈一交易所
其它軟件94.15MB
下載
易付幣交易所官網安卓版
其它軟件108.01M
下載